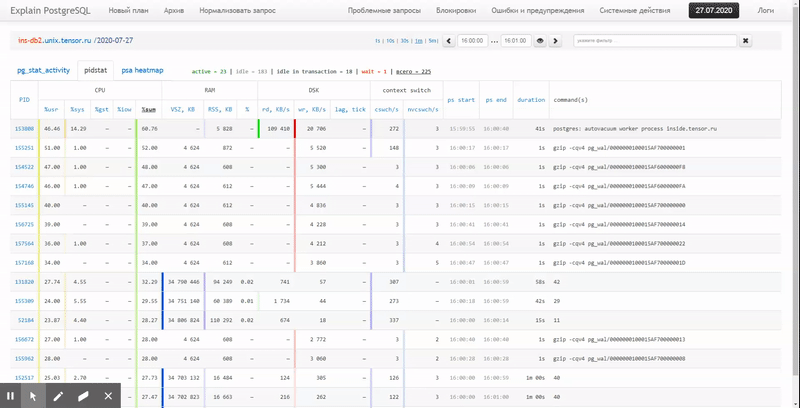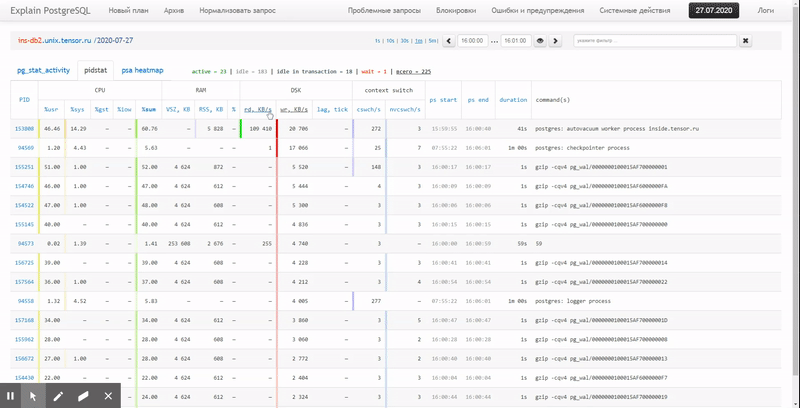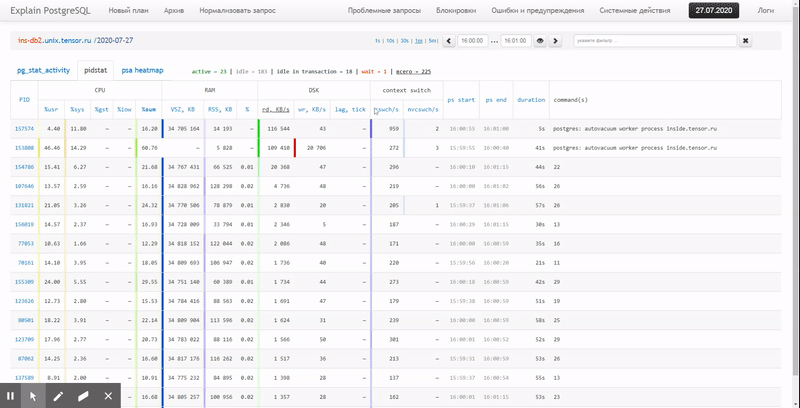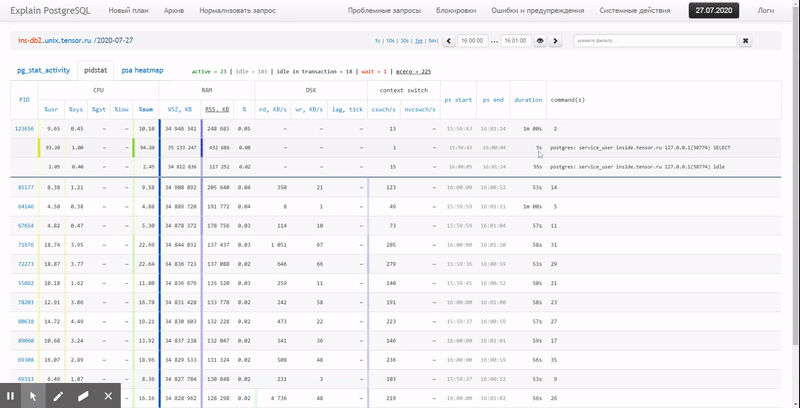
Ранее мы уже научились перехватывать блокировки из лога сервера PostgreSQL. Давайте теперь положим их в БД и разберем, какие фактические ошибки и проблемы производительности можно допустить на примере их простейшего анализа.
В логах у нас отражается всего 3 вида событий, которые могут происходить с блокировкой:
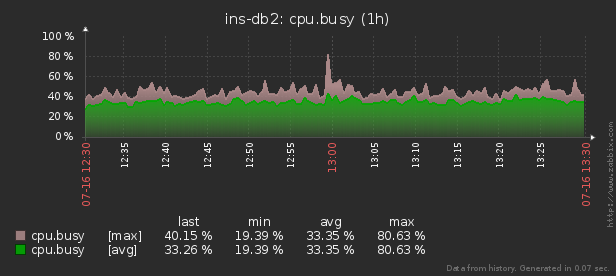
deadlock'и исключим из анализа — это просто ошибки, и попробуем выяснить, сколько всего времени мы потеряли из-за блокировок за конкретный день на определенном хосте.
В логах у нас отражается всего 3 вида событий, которые могут происходить с блокировкой:
- ожидание блокировки
LOG: process 38162 still waiting for ExclusiveLock on advisory lock [225382138,225386226,141586103,2] after 100.047 ms - получение блокировки
LOG: process 38162 acquired ExclusiveLock on advisory lock [225382138,225386226,141586103,2] after 150.741 ms - взаимоблокировка
ERROR: deadlock detected
deadlock'и исключим из анализа — это просто ошибки, и попробуем выяснить, сколько всего времени мы потеряли из-за блокировок за конкретный день на определенном хосте.