
Как мы подходим к поддержке ML-моделей в синтезе речи
10 мин
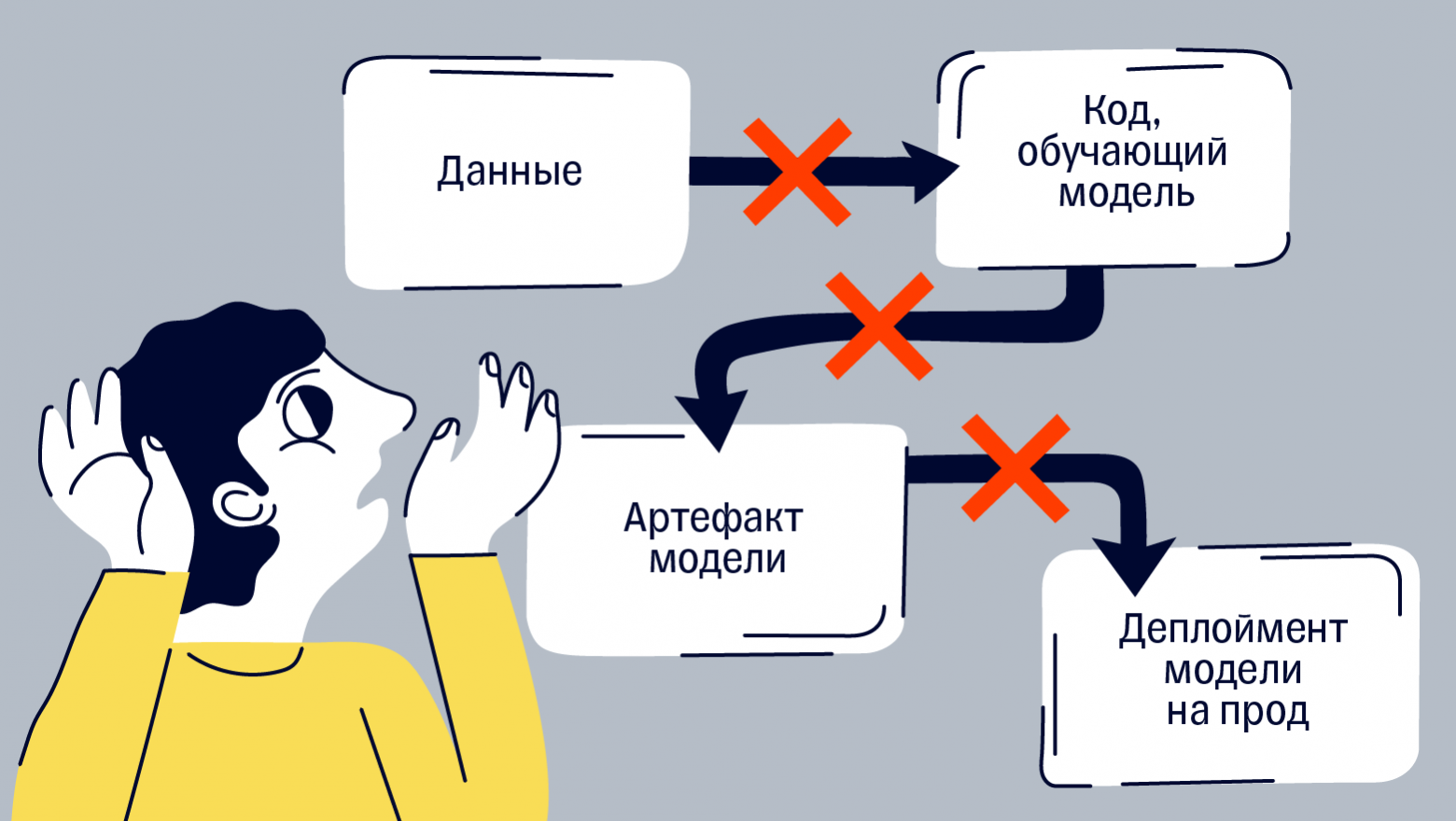
Всем привет! Меня зовут Александра Сорока, я занимаюсь синтезом речи в Тинькофф. А это — мой текст о том, зачем вообще думать о долгосрочной поддержке кода и ML-моделей. Я расскажу, почему мы отказались от опенсорсных решений, как работаем с датасетами и разными версиями моделей и как замеряем их качество. Статья может оказаться полезной для всех, кто хочет знать, как ничего не поломать.