Все больше компаний переходят на гибридный формат работы: сотрудники проводят в офисе лишь несколько дней, решая большую часть задач из дома. В
«Онланте» (входит в группу компаний
ЛАНИТ) работали удаленно еще до того, как пандемия внесла свои коррективы. Эта статья — обзор сервисов, которые позволяют участвовать в брейнштормах, работать над проектом и получать уведомления о новых задачах и их приоритете, находясь в любой точке мира. Описываем не только преимущества сервисов, но и подмечаем недостатки. Читайте о них ниже.
В «Онланте» формат удаленной работы был опробован задолго до того, как это стало мейнстримом. Команда у нас большая: сотрудники живут в разных городах — Пензе, Барнауле, Краснодаре, Нижнем Новгороде и Твери. Поэтому, когда грянула пандемия, полный переход на удаленку прошёл легко и безболезненно: дистанционная работа отличается от обычной только местоположением.
Нередка ситуация, когда руководитель проекта находится за тысячи километров от команды, а джун чаще видит наставника в zoom, чем очно. Оставаться эффективными нам помогают четко выстроенные процессы и многочисленные инструменты. Это тайм-трекеры, канбан-доски и сервисы для управления проектами.
Самих сервисов, конечно, намного больше. И крохотные стартапы зачастую предоставляют лучшие решения, чем крупные игроки рынка. В один обзор все не поместятся. Поэтому в статью вошли программы, которые используются нами в работе, сервисы, к которым я прибегаю для решения личных дел или те, что порекомендовали мне друзья и я, протестировав, составил о них личное мнение.
И еще небольшая оговорка. В силу специфики отрасли у нас высокие требования к уровню информационной безопасности, поэтому и этот критерий также лег в отбор описываемых сервисов, используемых командой «Онланты».













 — Андрей, вы знакомы с трудами Michael Feathers, например, «Working Effectively with Legacy Code»? В книге акцентируется внимание на важности тестирования и выделяется одно из ключевых отличий legacy от не legacy-кода — это наличие тестов. Вы согласны с этим мнением?
— Андрей, вы знакомы с трудами Michael Feathers, например, «Working Effectively with Legacy Code»? В книге акцентируется внимание на важности тестирования и выделяется одно из ключевых отличий legacy от не legacy-кода — это наличие тестов. Вы согласны с этим мнением? 
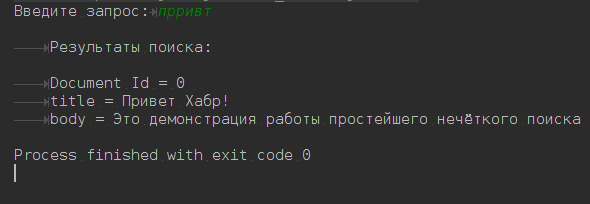 Пост расcчитан на начинающих, на людей незнакомых с технологией Apache Lucene. В нем нет материала о том, как устроен Apache Lucene внутри, какие алгоритмы, структуры данных и методы использовались для создания фреймворка. Пост является обучающим материалом-тизером, написанным для того, чтобы показать, как организовать простейший нечёткий поиск по тексту.
Пост расcчитан на начинающих, на людей незнакомых с технологией Apache Lucene. В нем нет материала о том, как устроен Apache Lucene внутри, какие алгоритмы, структуры данных и методы использовались для создания фреймворка. Пост является обучающим материалом-тизером, написанным для того, чтобы показать, как организовать простейший нечёткий поиск по тексту. 