Наверное, все, работающие с Java, знают об управлении памяти на уровне, что для ее распределения используется сборщик мусора. Не все, к сожалению, знают, как именно этот сборщик (-и) работает, и как именно организована память внутри процесса Java.

Александр @Alex_T_Aread-only
Пользователь
K8s best practices или что будет если их не соблюдать?
Средний
9 мин
Кейс

Всем привет! В данной статье хотелось бы рассказать о небольшом исследовании Kubernetes ограничений и рекомендаций, а так же что будет если их нарушить и о том что это может быть в некоторых случаях полезно и даже экономически выгодно. Будет рубрика "Ээээксперименты!", поищем проблемы, попробуем их решить и посмотрим что получиться.
Разбираемся с Docker: как создаются образы
13 мин

От любого инструмента, который внедряем в проект, мы ждём стабильной работы. Docker не исключение. Чтобы иметь возможность оперативно выявлять потенциальные проблемы и избегать сбоев, необходимо понимать внутренние особенности технологии. Эта статья — сборник заметок, которые помогут разобраться, как создаются образы контейнеров.
Что такое UEFI, и чем он отличается от BIOS?
5 мин
Перевод
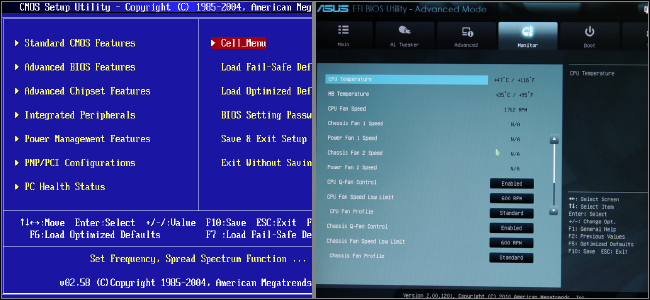
Новые компьютеры используют прошивку UEFI вместо традиционного BIOS. Обе эти программы – примеры ПО низкого уровня, запускающегося при старте компьютера перед тем, как загрузится операционная система. UEFI – более новое решение, он поддерживает жёсткие диски большего объёма, быстрее грузится, более безопасен – и, что очень удобно, обладает графическим интерфейсом и поддерживает мышь.
Некоторые новые компьютеры, поставляемые с UEFI, по-прежнему называют его «BIOS», чтобы не запутать пользователя, привычного к традиционным PC BIOS. Но, даже встретив его упоминание, знайте, что ваш новый компьютер, скорее всего, будет оснащён UEFI, а не BIOS.
Hello, World! Глубокое погружение в Терминалы
24 мин
На написание данной статьи меня вдохновила статья об анализе Сишного printf. Однако, там был пропущен момент о том, какой путь проходят данные после того, как они попадают в терминальное устройство. В данной статье я хочу исправить этот недочет и проанализировать путь данных в терминале. Также мы разберемся, чем отличается Terminal от Shell, что такое Pseudoterminal, как работают эмуляторы терминалов и многое другое.
Когда Linux conntrack вам больше не товарищ
5 мин
Перевод
Отслеживание соединений (“conntrack”) является основной функцией сетевого стека ядра Linux. Она позволяет ядру отслеживать все логические сетевые соединения или потоки и тем самым идентифицировать все пакеты, которые составляют каждый поток, чтобы их можно было последовательно обрабатывать вместе.
Уязвимость Docker Escape: побег из контейнера всё ещё возможен
6 мин

Как и любое другое программное обеспечение, в Docker присутствуют различные уязвимости. Одной из самых известных уязвимостей считается «Docker escape» — побег из контейнера Docker. Данная уязвимость позволяет получить доступ к основной (хостовой) операционной системе, тем самым совершая побег из контейнера.
Впервые данная уязвимость была обнаружена командой аналитиков по информационной безопасности из Project Zero в июле 2019 года. Несмотря на то, что с момента выявления уязвимости уже прошло более двух лет, её всё ещё можно реализовать.
Сертификаты K8S или как распутать вермишель Часть 1
5 мин

Всем привет. Меня зовут Добрый Кот Telegram.
От коллектива FR-Solutions и при поддержке @irbgeo Telegram : Продолжаем серию статей по сертификатам k8s.
Хочу поделиться с вами некоторым мыслями на тему сертификатов в кубе.
Магия SSH
11 мин
С SSH многие знакомы давно, но, как и я, не все подозревают о том, какие возможности таятся за этими магическими тремя буквами. Хотел бы поделиться своим небольшим опытом использования SSH для решения различных административных задач.
Оглавление:
1) Local TCP forwarding
2) Remote TCP forwarding
3) TCP forwarding chain через несколько узлов
4) TCP forwarding ssh-соединения
5) SSH VPN Tunnel
6) Коротко о беспарольном доступе
7) Спасибо (ссылки)
Оглавление:
1) Local TCP forwarding
2) Remote TCP forwarding
3) TCP forwarding chain через несколько узлов
4) TCP forwarding ssh-соединения
5) SSH VPN Tunnel
6) Коротко о беспарольном доступе
7) Спасибо (ссылки)
Tcpdump на разных уровнях
4 мин

Утилита Tcpdump знакома любому сетевому администратору, с ее помощью мы собираем трафик для последующего анализа. Типичная история – собираем траффик, приходящий на нужный интерфейс и затем уже анализируем его Wireshark. Подход практичный, ведь Wireshark Действительно очень мощный и полезный инструмент и о нем мы напишем еще не одну статью, но сегодня речь пойдет про Tcpdump. Не секрет, что утилита Tcpdump не интерпретирует протоколы прикладного уровня, ограничиваясь работой с транспортным уровнем. Однако, в этой статье мы рассмотрим различные варианты использования утилиты Tcpdump для более глубокой фильтрации трафика.
Итак, Tcpdump - утилита UNIX, позволяющая перехватывать и анализировать сетевой трафик, проходящий или приходящий через компьютер, на котором запущена данная программа.
HTTP 1, 2 и 3 — просто
Простой
5 мин
Туториал

Просто о том, чем отличаются HTTP1, HTTP2 и HTTP3, а также почему HTTP3 ещё и QUIC. Статья для junior'ов, интересующихся и готовящихся к собеседованиям.
Docker Compose: упрощение работы с использованием Makefile
6 мин
Перевод
Каждые несколько лет в индустрии разработки ПО происходит смена парадигмы. Одним из таких явлений можно признать рост интереса к концепции микросервисов. Хотя микросервисы — это технология не самая новая, лишь в последнее время её популярность буквально взлетела до небес.
Большие монолитные сервисы в наши дни заменяют независимыми автономными микросервисами. Микросервис можно рассматривать как приложение, которое служит единственной и очень специфической цели. Например — это может быть реляционная СУБД, Express-приложение, Solr-сервис.

В наши дни сложно представить себе разработку новой программной системы без применения микросервисов. А эта ситуация, в свою очередь, ведёт нас к платформе Docker.
Большие монолитные сервисы в наши дни заменяют независимыми автономными микросервисами. Микросервис можно рассматривать как приложение, которое служит единственной и очень специфической цели. Например — это может быть реляционная СУБД, Express-приложение, Solr-сервис.
В наши дни сложно представить себе разработку новой программной системы без применения микросервисов. А эта ситуация, в свою очередь, ведёт нас к платформе Docker.
Изучаем сетевой стек докера в rootless mode
Средний
16 мин
Туториал
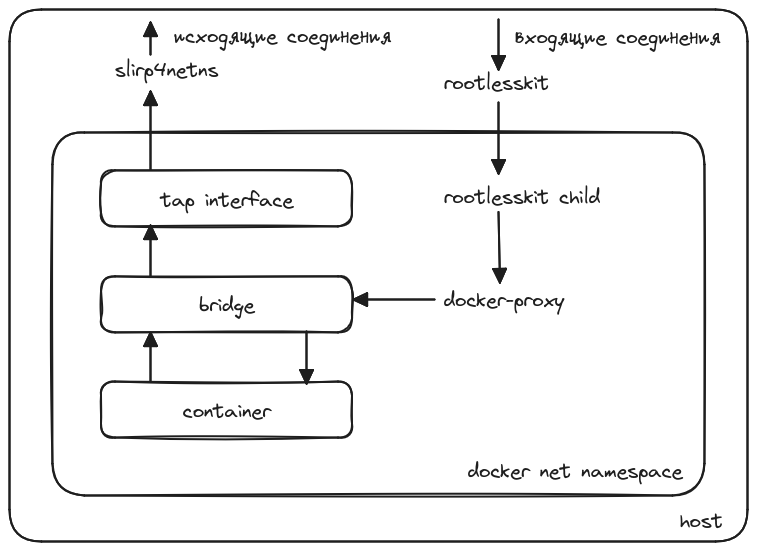
Недавно я столкнулся с докером в rootless mode и по привычке решил посмотреть на его сетевые интерфейсы на хосте. К своему удивлению я их не увидел, поэтому начал разбираться, как же в нем организовано сетевое взаимодействие. Результатами анализа я и поделюсь в этой статье.
Изучаем структуры MBR и GPT
9 мин
Для работы с жестким диском его для начала необходимо как-то разметить, чтобы операционная система могла понять в какие области диска можно записывать информацию. Поскольку жесткие диски имеют большой объем, их пространство обычно разбивают на несколько частей — разделов диска. Каждому такому разделу может быть присвоена своя буква логического диска (для систем семейства Windows) и работать с ним можно, как будто это независимый диск в системе.
Способов разбиения дисков на разделы на сегодняшний день существует два. Первый способ — использовать MBR. Этот способ применялся еще чуть ли не с появления жестких дисков и работает с любыми операционными системами. Второй способ — использовать новую систему разметки — GPT. Этот способ поддерживается только современными операционными системами, поскольку он еще относительно молод.
Способов разбиения дисков на разделы на сегодняшний день существует два. Первый способ — использовать MBR. Этот способ применялся еще чуть ли не с появления жестких дисков и работает с любыми операционными системами. Второй способ — использовать новую систему разметки — GPT. Этот способ поддерживается только современными операционными системами, поскольку он еще относительно молод.
Проблема PID 1 zombie reaping в Докере
8 мин
Перевод
Привет, Хабр!
Мы в Хекслете активно используем Докер как для запуска самого приложения и сопутствующих серверов, так и для запуска пользовательского кода в практических упражнениях по программированию. Без этих легковесных контейнеров нам было бы в разы сложнее справиться с этими задачами. Докер –замечательная технология, но иногда возникают неожиданные проблемы. Одна из таких проблем (и ее решение) описана в блоге Phusion (это создатели Phusion Passenger), сегодня мы публикуем ее перевод.
Примерно год назад, когда Докер был в версии 0.6, мы первыми представили Baseimage-docker. Это минимальный образ Ubuntu, модифицированный специально для Докера. Люди могут пуллить этот базовый образ из Docker Registry и использовать его как основу для своих образов.
Мы были ранними пользователям Докера, используя его для CI и для создания рабочего окружения задолго до выхода версии 1.0. Базовый образ мы сделали чтобы решить проблемы, специфичные для принципов работы Докера. Например, Докер не запускает процессы под специальным процессом init, который бы правильно обрабатывал дочерние процессы, поэтому возможна такая ситуация, когда зомби-процессы вызывают кучу проблем. Докер также не делает ничего с syslog, поэтому важные сообщения могут быть утеряны. И так далее.
Однако, мы выяснили, что многие люди не понимают проблем, с которыми мы столкнулись. Да, это довольно низкоуровневые системные механизмы Unix, которые понятны далеко не всем. Поэтому в этом посте мы опишем самую главную проблему, которую мы решаем – PID 1 zombie reaping problem.

Мы в Хекслете активно используем Докер как для запуска самого приложения и сопутствующих серверов, так и для запуска пользовательского кода в практических упражнениях по программированию. Без этих легковесных контейнеров нам было бы в разы сложнее справиться с этими задачами. Докер –замечательная технология, но иногда возникают неожиданные проблемы. Одна из таких проблем (и ее решение) описана в блоге Phusion (это создатели Phusion Passenger), сегодня мы публикуем ее перевод.
Примерно год назад, когда Докер был в версии 0.6, мы первыми представили Baseimage-docker. Это минимальный образ Ubuntu, модифицированный специально для Докера. Люди могут пуллить этот базовый образ из Docker Registry и использовать его как основу для своих образов.
Мы были ранними пользователям Докера, используя его для CI и для создания рабочего окружения задолго до выхода версии 1.0. Базовый образ мы сделали чтобы решить проблемы, специфичные для принципов работы Докера. Например, Докер не запускает процессы под специальным процессом init, который бы правильно обрабатывал дочерние процессы, поэтому возможна такая ситуация, когда зомби-процессы вызывают кучу проблем. Докер также не делает ничего с syslog, поэтому важные сообщения могут быть утеряны. И так далее.
Однако, мы выяснили, что многие люди не понимают проблем, с которыми мы столкнулись. Да, это довольно низкоуровневые системные механизмы Unix, которые понятны далеко не всем. Поэтому в этом посте мы опишем самую главную проблему, которую мы решаем – PID 1 zombie reaping problem.
Кое-что об inode
5 мин
Периодически, с целью переезда в ЦРС собеседуюсь в разных крупных компаниях, в основном Питера и Москвы на должность DevOps. Обратил внимание, что во многих компаниях (во многих хороших компаниях, например в яндексе) задают два сходных вопроса:
Как часто бывает, я был уверен, что эту тему знаю хорошо, но как только начал объяснять — обозначились провалы в знаниях. Чтобы систематизировать свои знания, заполнить пробелы и больше не позориться, пишу эту статью, может еще кому пригодится.
Начну «снизу», т.е. с жесткого диска (флешки, SSD и прочие современные штуки отбросим, для примера рассмотрим любой 20 или 80 гиговый старый диск, т.к. там размер блока 512 байт).
Жесткий диск не умеет адресовать свое пространство побайтно, условно оно разбито на блоки. Нумерация блоков начинается с 0. (называется это LBA, подробности тут: ru.wikipedia.org/wiki/LBA)
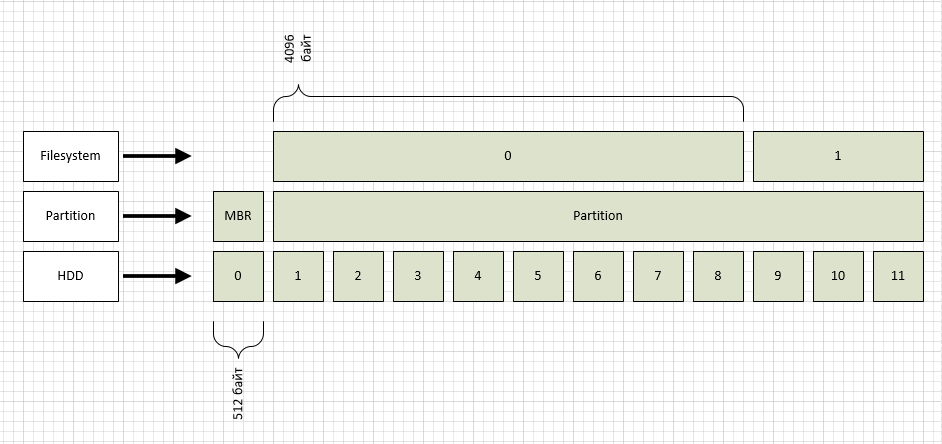
- что такое inode;
- по каким причинам можно получить ошибку записи на диск (или например: почему может закончиться место на диске, суть одна).
Как часто бывает, я был уверен, что эту тему знаю хорошо, но как только начал объяснять — обозначились провалы в знаниях. Чтобы систематизировать свои знания, заполнить пробелы и больше не позориться, пишу эту статью, может еще кому пригодится.
Начну «снизу», т.е. с жесткого диска (флешки, SSD и прочие современные штуки отбросим, для примера рассмотрим любой 20 или 80 гиговый старый диск, т.к. там размер блока 512 байт).
Жесткий диск не умеет адресовать свое пространство побайтно, условно оно разбито на блоки. Нумерация блоков начинается с 0. (называется это LBA, подробности тут: ru.wikipedia.org/wiki/LBA)
Как на самом деле Linux выполняет запись на диск?
6 мин
Перевод

Друзья мои, программисты и операторы, я бы хотел поговорить о том, как в Linux работает запись файлов.
Раньше я думал, что она устроена определённым образом, и как Джон Леннон, «I’m not the only one». Оказалось, операции записи работают совершенно иначе. То, как они работают, интересно и важно знать.
Позвольте начать с того, как я раньше думал о записи файлов.
Управление высокодоступными PostgreSQL кластерами с помощью Patroni. А.Клюкин, А.Кукушкин
62 мин
Туториал
Расшифровка доклада/tutorial "Управление высокодоступными PostgreSQL кластерами с помощью Patroni". А.Клюкин, А.Кукушкин
Patroni — это Python-приложение для создания высокодоступных PostgreSQL кластеров на основе потоковой репликации. Оно используется такими компаниями как Red Hat, IBM Compose, Zalando и многими другими. С его помощью можно преобразовать систему из ведущего и ведомых узлов (primary — replica) в высокодоступный кластер с поддержкой автоматического контролируемого (switchover) и аварийного (failover) переключения. Patroni позволяет легко добавлять новые реплики в существующий кластер, поддерживает динамическое изменение конфигурации PostgreSQL одновременно на всех узлах кластера и множество других возможностей, таких как синхронная репликация, настраиваемые действия при переключении узлов, REST API, возможность запуска пользовательских команд для создания реплики вместо pg_basebackup, взаимодействие с Kubernetes и т.д.
Слушатели мастер-класса подробно узнают, как работает Patroni, получат практические навыки настройки высокодоступных кластеров на его основе, познакомятся с различными дополнительными возможностями и поучаствуют в диагностике проблем. Будут рассмотрены следующие темы:
- область применения: какие задачи HA успешно решаются Patroni
- обзор архитектуры
- создание тестового кластера
- утилита patronictl
- изменение конфигурации PostgreSQL для кластера, управляемого Patroni
- мониторинг с помощью API
- подходы к переключению клиентов
- дополнительные возможности: ручное переключение, перезагрузка по расписанию, режим паузы
- настройка синхронной репликации
- расширяемость и универсальность
- частые ошибки и их диагностика

Kubernetes: шпаргалка для собеседования
Простой
10 мин
Обзор
Всем привет! Меня зовут Олег, я работаю исполнительным директором по разработке в Газпромбанке. На разных этапах карьеры я участвовал во многих собеседованиях, а в настоящее время сам собеседую кандидатов на должность инженеров DevOps и системных администраторов в Газпромбанке, вследствие чего у меня сформировалось некоторое представление о вопросах, которые могут быть заданы соискателям. И сейчас я хочу остановиться на разделе вопросов про Kubernetes.

Сразу хочу сказать, что изначально планировал сделать одну статью, но в итоге получилась такая простыня, что пришлось разделить текст на две части. Ссылку на вторую опубликую здесь, как только она появится (вот она).
Вопросы по Kubernetes достаточно часты на собеседованиях на инженерные вакансии, связанные с администрированием и эксплуатацией. Они могут варьироваться от базовых, рассчитанных на механическую проверку теоретических знаний («объясните, что такое service») до более сложных и комплексных, требующих глубинного понимания внутренних принципов Kubernetes и работы (каким образом опубликовать приложение, развёрнутое в Kubernetes). Давайте пойдём от базы в направлении возрастания сложности.
Сразу хочу сказать, что изначально планировал сделать одну статью, но в итоге получилась такая простыня, что пришлось разделить текст на две части. Ссылку на вторую опубликую здесь, как только она появится (вот она).
Вопросы по Kubernetes достаточно часты на собеседованиях на инженерные вакансии, связанные с администрированием и эксплуатацией. Они могут варьироваться от базовых, рассчитанных на механическую проверку теоретических знаний («объясните, что такое service») до более сложных и комплексных, требующих глубинного понимания внутренних принципов Kubernetes и работы (каким образом опубликовать приложение, развёрнутое в Kubernetes). Давайте пойдём от базы в направлении возрастания сложности.
Механизмы контейнеризации: namespaces
11 мин

Последние несколько лет отмечены ростом популярности «контейнерных» решений для ОС Linux. О том, как и для каких целей можно использовать контейнеры, сегодня много говорят и пишут. А вот механизмам, лежащим в основе контейнеризации, уделяется гораздо меньше внимания.
Все инструменты контейнеризации — будь то Docker, LXC или systemd-nspawn,— основываются на двух подсистемах ядра Linux: namespaces и cgroups. Механизм namespaces (пространств имён) мы хотели бы подробно рассмотреть в этой статье.
Начнём несколько издалека. Идеи, лежащие в основе механизма пространств имён, не новы. Ещё в 1979 году в UNIX был добавлен системный вызов chroot() — как раз с целью обеспечить изоляцию и предоставить разработчикам отдельную от основной системы площадку для тестирования. Нелишним будет вспомнить, как он работает. Затем мы рассмотрим особенности функционирования механизма пространств имён в современных Linux-системах.