
Наверняка многие уже успели наиграться с китайскими солнечными фонариками и разочароваться в них. Попробуем разобраться в вопросе: в чём причина их малой яркости и можно ли с этим что-то сделать?

Пользователь

Хайп вокруг нейросетей, выровненных при помощи инструкций и человеческой оценки (известных в народе под единым брендом «ChatGPT»), трудно не заметить. Люди разных профессий и возрастов дивятся примерами нейросетевых генераций, используют ChatGPT для создания контента и рассуждают на темы сознания, а также повсеместного отнимания нейросетями рабочих мест. Отдадим должное качеству продукта от OpenAI — так и подмывает использовать эту технологию по любому поводу — «напиши статью», «исправь код», «дай совет по общению с девушками».
Но как достичь или хотя бы приблизиться к подобному качеству? Что играет ключевую роль при обучении — данные, архитектура, ёмкость модели или что-то ещё? Создатели ChatGPT, к сожалению, не раскрывают деталей своих экспериментов, поэтому многочисленные исследователи нащупывают свой путь и опираются на результаты друг друга.
Мы с радостью хотим поделиться с сообществом своим опытом по созданию подобной модели, включая технические детали, а также дать возможность попробовать её, в том числе через API. Итак, «Салют, GigaChat! Как приручить дракона?»

Уже много времени прошло с момента публикации наших последних языковых моделей ruT5, ruRoBERTa, ruGPT-3. За это время много что изменилось в NLP. Наши модели легли в основу множества русскоязычных NLP-сервисов. Многие коллеги на базе наших моделей выпустили свои доменно-адаптированные решения и поделились ими с сообществом. Надеемся, что наша новая модель поможет вам поднять метрики качества, и ее возможности вдохновят вас на создание новых интересных продуктов и сервисов.
Появление ChatGPT и, как следствие, возросший интерес к методам обучения с подкреплением обратной связью от человека (Reinforcement Learning with Human Feedback, RLHF), привели к росту потребности в эффективных архитектурах для reward-сетей. Именно от «интеллекта» и продуктопригодности reward-модели зависит то, насколько эффективно модель для инструктивной диалоговой генерации будет дообучаться, взаимодействуя с экспертами. Разрабатывая FRED-T5, мы имели в виду и эту задачу, поскольку от качества её решения будет во многом зависеть успех в конкуренции с продуктами OpenAI. Так что если ваша команда строит в гараже свой собственный ChatGPT, то, возможно, вам следует присмотреться и к FRED’у. Мы уже ранее рассказывали в общих чертах об этой модели, а сейчас, вместе с публичным релизом, настало время раскрытия некоторых технических подробностей.
Появление новых, более производительных GPU и TPU открывает возможности для использования в массовых продуктах и сервисах всё более емких моделей машинного обучения. Выбирая архитектуру своей модели, мы целились именно в ее пригодность к массовому realtime-инференсу, поскольку время выполнения и доступное оборудование — это основные факторы, лимитирующие возможность создания массовых решений на основе нейросетевых моделей. Если вы уже используете в своем решении модель ruT5, то подменив ее на FRED-T5 вы, вероятно, получите заметное улучшение значений ваших целевых метрик. Конечно, в скором будущем мы обучим еще более емкие варианты модели FRED-T5 и проверим их возможности — мы планируем и дальнейшее развитие линейки энкодер-декодерных моделей для обработки русского языка.
В ноябре 2022 года мы выпустили свою первую диффузионную модель для синтеза изображений по текстовым описаниям Kandinsky 2.0, которая собрала как позитивные, так и отрицательные отклики. Её ключевой особенностью была мультиязычность и использование двойного текстового энкодера на входе сети: XLMR-clip и mT5-small. Рефлексия после релиза подтолкнула нас к перестройке планов по развитию архитектуры и к сильному стремлению получить буст в качестве генераций, чтобы выйти на уровень аналогичных решений, названия которых слишком хорошо известны, чтобы их называть. В то же время мы могли наблюдать за появлением новых генеративных моделей и их файнтюнов, таких как ControlNet, GigaGAN, GLIGEN, Instruct Pix2Pix и др. В этих работах представлены и новые взгляды на генерацию, и новые возможности использования латентного пространства для внесения контролируемых изменений через текстовые промты, а также для смешивания изображений — возможности использования генеративных моделей расширяются постоянно. Бурное развитие прикладных кейсов привело к интенсивно нарастающему числу различных привлекательных для пользователей реализаций этих функций — визуализация городов, изображения известных личностей в нетипичных ситуациях и многие другие.

Вероятно вы уже слышали про успехи нейросетей в генерации картинок по текстовому описанию.
Я решил разобраться, и заодно сделать небольшой туториал, по архитектуре модели Stable Diffusion. Сегодня мы не будем глубоко погружаться в математику и процесс тренировки. Вместо этого сфокусируемся на применении и устройстве основных компонент: UNet, VAE, CLIP.
В нашем мире мы можем сделать всё, что захотим. Всё что угодно.
— Боб Росс, The Joy Of Painting, сезон 29, эпизод 1


Недавно нашел статью 2018 года, в которой авторы поставили себе целью продемонстрировать, что не стоит смотреть на задачи, входы/выходы в которых являют собой последовательности, исключительно сквозь призму рекуррентных сетей, а в результате не только добились своей цели, но еще и улучшили state-of-the-art на модификации небезызвестного MNIST, но обо всем по порядку.
О чем, собственно, речь?
Авторы статьи, как они сами утверждают, стремятся показать, что для решения задач с последовательными данными в качестве стартовой точки должен рассматриваться именно сверточный, а не рекуррентный поход, и, чтобы доказать свою точку зрения, предлагают общую и вполне прямолинейную модель Temporal Convolutional Network (TCN) и сравнивают ее с рекуррентными решениями на, что называется, "домашнем поле" последних, а именно датасетах, которые часто используются для сравнения качества рекуррентных моделей.

Недавно компания 🤗 Hugging Face (стартап, стоящий за библиотекой transformers) выпустила новый продукт под названием "Infinity". Он описывается как сервер для выхода в “production”. Публичная демонстрация доступна на YouTube (ниже приведены скриншоты с таймингами и настройками, использованными во время демонстрации). Все основано на обещании, что продукт может выполнять работу с NLP с задержкой в 1 миллисекунду на графическом процессоре. По словам ведущего демонстрации, сервер Hugging Face Infinity стоит не менее 20.000$ в год за одну модель, развернутую на одной машине (общедоступная информация о ценовой масштабируемости отсутствует).
Мне стало любопытно немного покопаться и проверить, возможно ли достичь таких показателей? Спойлер: да, возможно, и с помощью этой статьи его легко воспроизвести и адаптировать к вашим РЕАЛЬНЫМ проектам.
А для тех, кому лень все это читать и хочется все получить из коробки... Ссылка на GitHub. Поставьте зведу сразу, а потом читайте 🤗
Меня зовут Николай, я Frontend-разработчик IT-компании Relog. Хочу рассказать о самых распространённых ошибках в вёрстке современных проектов.
Дело в том, что лишь малая часть современных фронтендеров обращает внимание на работу с HTML и CSS, предпочитая готовые решения, вроде UI-библиотек и систем сеток. Но эти решения неидеальные и приходится дописывать обёртки вокруг них, видоизменять код, переписывать стили и совершать прочие действия для соответствия требованиям проекта. Тут-то и начинаются проблемы: вёрстка местами становится избыточной, стили переназначются через important и с каждым релизом проект всё сложней поддерживать. Я уже не говорю об удобстве использования и доступности. Об этом думают вообще в последнюю очередь.
В этой статье я расскажу лишь о небольшой части проблем, которые можно достаточно быстро решить, не прибегая к радикальному переписыванию больших частей проекта.

Публикуем вторую часть материала о трансформерах. В первой части речь шла о теоретических основах трансформеров, были показаны примеры их реализации с использованием PyTorch. Здесь поговорим о том, какое место слои внутреннего внимания занимают в нейросетевых архитектурах, и о том, как создают трансформеры, ориентированные на решение различных задач.

Трансформеры (transformers) — это очень интересное семейство архитектур машинного обучения. Существует много хороших учебных материалов по этой теме (например — вот и вот), но в последние несколько лет трансформеры, в основном, становились всё проще. Поэтому сейчас гораздо легче, чем раньше, объяснить принципы их работы. Этот материал представляет собой попытку, что называется, «на пальцах», объяснить то, как работают современные трансформеры.
Предполагается, что читатель обладает элементарными представлениями о нейронных сетях и об алгоритме обратного распространения ошибки. Если вы хотите освежить знания в этих областях — вот видео, которое поможет вам вспомнить основы нейронных сетей, а здесь вы найдёте рассказ о том, как соответствующие принципы применяются в современных системах глубокого обучения.
Для того чтобы понять примеры кода, понадобятся практические знания фреймворка PyTorch. Но эти примеры можно и пропустить без вреда для понимания остального материала.
Здесь можно найти видеолекции о трансформерах. А в этом репозитории имеется реализация простого трансформера с использованием PyTorch.
Эта статья родилась случайно. Слоняясь по книжному фестивалю и наблюдая, как дочка пытает консультантов, заставляя их искать Иэна Стюарта, мой глаз зацепился за знакомые буквы на обложке: "Nginx".
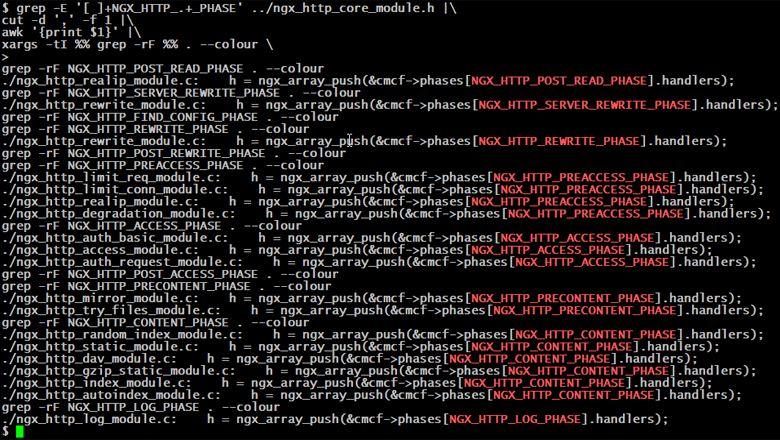
Надо же, на полках нашлось целых три книги - не полистать их было бы преступлением. Первая, вторая, третья... Ощущение, будто что-то не так. Ну вроде страниц много, текст связный, но каково содержание? Установка nginx, список переменных и модулей, а дальше docker, ansible. Открываем вторую: wget, лимиты запросов и памяти, балансировка, kubernetes, AWS. Третья: GeoIP, авторизация, потоковое вещание, puppet, Azure. Ребята, а где про то, как вообще работает nginx? На кого рассчитаны ваши книги? На состоявшегося админа, который и так знает архитектуру этого веб-сервера? Да он вроде с базовыми настройками и сам справится. На новичка, который не знает как пользоваться wget? Вы уверены, что ему знание о существовании ngx_http_degradation_module и тем паче "облака" важнее порядка прохождения запроса?
Итак. О чем не пишут в книгах.
(здесь и дальше мы говорим только о NGX_HTTP_)

Рассказываю, почему SQLite отлично подойдет вам в повседневной работе. И неважно, разработчик вы, аналитик, тестировщик, админ или продакт-менеджер.
Если вы следите за отчетами исследователей, которые участвуют в bug bounty программах, то наверняка знаете про категорию уязвимостей JavaScript prototype pollution. А если не следите и встречаете это словосочетание впервые, то предлагаю вам закрыть этот пробел, ведь эта уязвимость может привести к полной компрометации сервера и клиента. Наверняка хотя бы один продуктов вашей (или не вашей) компании работает на JavaScript: клиентская часть веб-приложения, десктоп (Electron), сервер (NodeJS) или мобильное приложение.
Эта статья поможет вам погрузиться в тему prototype pollution. В разделах Особенности JavaScript и Что такое prototype pollution? вы узнаете как работают объекты и прототипы JavaScript и как особенности их функционирования могут привести к уязвимостям. В разделах Prototype pollution на сервере и Prototype pollution на клиенте вы научитесь искать и эксплуатировать эту уязвимость на кейсах из реального мира. Наконец вы изучите способы защиты и почему самый распространенный способ защиты можно легко обойти.
Прежде чем перейти к следующим разделам, предлагаю вам открыть инструменты разработчика и по ходу статьи попробовать приведенные примеры своими руками, с тем чтобы в результате получить некоторый практический опыт и глубже понять материал.

