 Авокадо с зубами подсказывает, что так код легче поддерживать, дописывать и рефакторить. Мы всё теперь пишем только так.
Авокадо с зубами подсказывает, что так код легче поддерживать, дописывать и рефакторить. Мы всё теперь пишем только так.
Привет, Хабр! У нас была проблема: каждый писал код как хотел. Было очень тяжело это поддерживать и ревьюить. Мы сначала думали, что достаточно написать стандарт кода. Оказалось, недостаточно, ему ещё надо обучить. Чтобы обучить, мы открыли для ревью эталоны кода, чтобы покрыть ими самую частую логику взаимодействия с компонентами. Тоже не хватило. А заодно я узнал, что мои же «золотые» образцы противоречили моему же стандарту кода (сначала было смешно, а потом пришлось переписывать).
В итоге я сделал кукбук с большим количеством примеров, чтобы объяснить культуру и методологию не через абстракции, а очень предметно. Начал вроде как просто для себя, оказалось полезно — и внедрил в работу команды.
Всё это было нужно для того, чтобы мы все в команде понимали, что такое наш стандарт кода, делали одинаковые вещи примерно одинаково, имели набор готовых шаблонов на системные или платформенные обращения и уменьшили объёмы как самого ревью, так и диалогов после.
Началось с того, что однажды я увидел очередной большой кусок кода, где логика из одного сервиса ушла в другой, а интеграционных тестов было аж 54 штуки. Исправленная опечатка в одном из запросов потребовала трёх часов работы, хотя я заранее знал с точностью до строчки и знака, где именно эта опечатка.
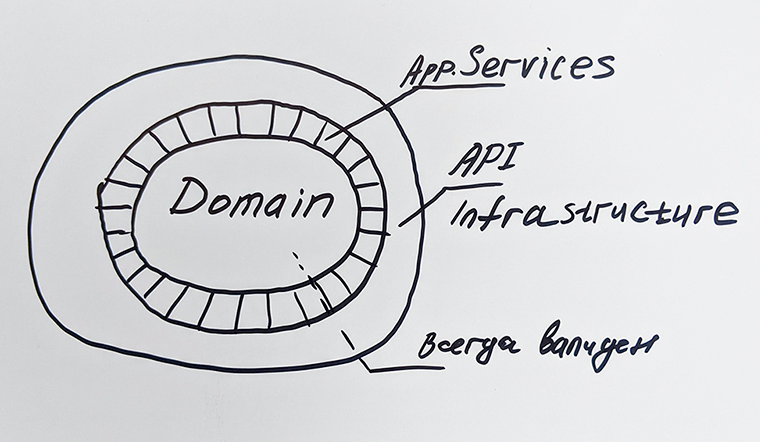
В общем, тот результат, который нас устроил, — это сочетание стандарта, библиотеки шаблонов и книги, как написать приложение. В ней мы делаем демоприложение и через все этапы показываем, почему принималось то или иное решение для реализации кода.
На сегодня ни в одной компании в России я не видел целостного подхода в сборке с кукбуком. Какие-то части встречаются, в сборке — нет. Вот я и хочу рассказать, как мы это сделали у себя в банке.
Посвящается всем, кто коллекционирует элегантные решения без привязки к языку, фрэймворку, Фаундлингам и Software Craftsmanʼам.
Погнали.