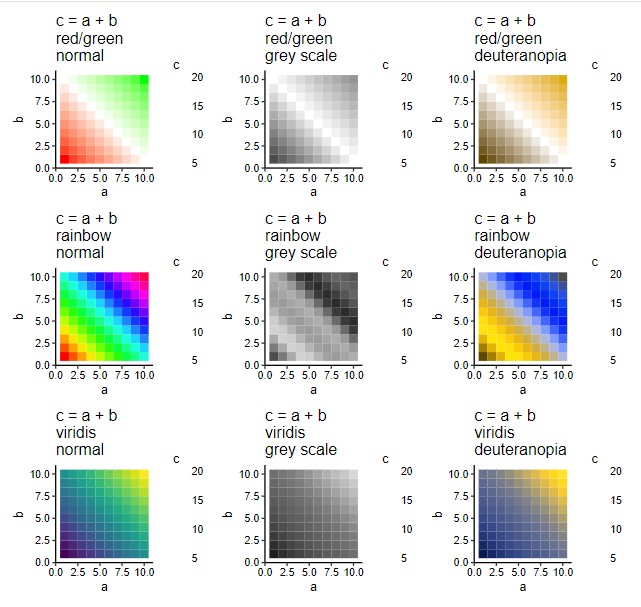
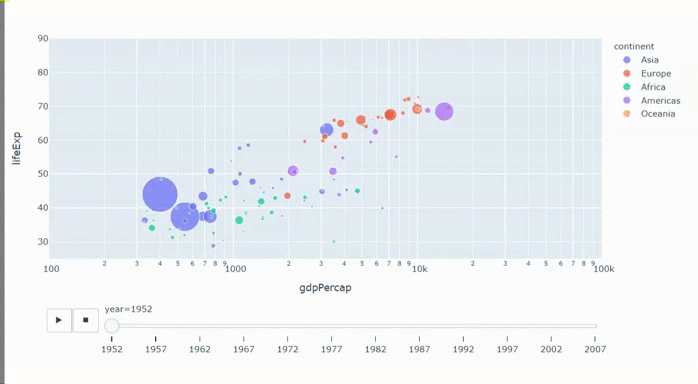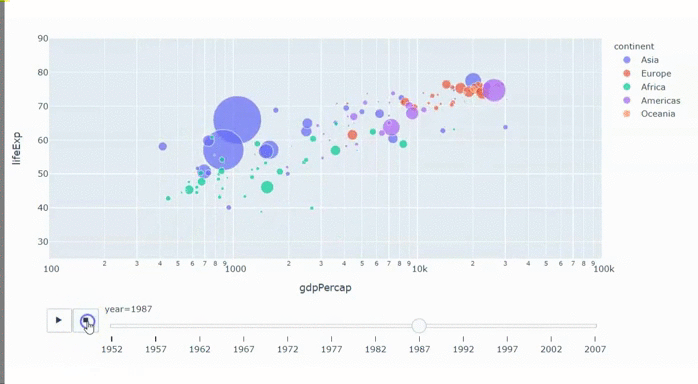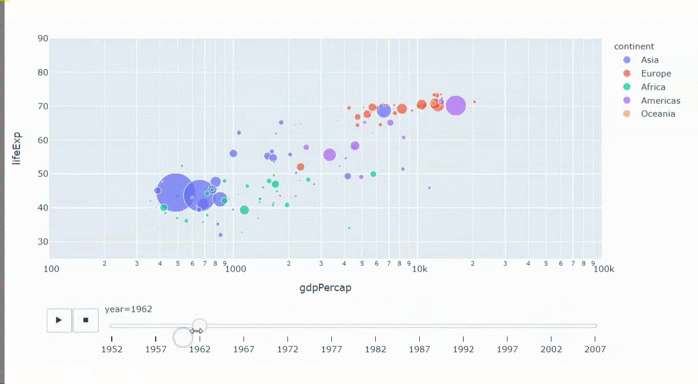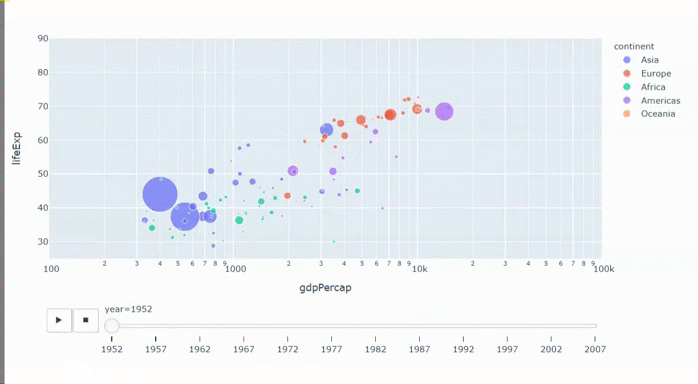
В статье я хочу поделиться успешным командным и личным опытом участия в хакатонах и ML соревнованиях. На примере 13-ти соревнований, по итогу которых мы победили или оказывались на призовых местах, я рассажу о практических советах для будущих участников.
На личном опыте я убедился, что не всегда для победы требуются сложные алгоритмы, мощное железо или большой опыт в индустрии. Иногда 5-6 строчек кода и немного смекалки достаточно, чтобы получить топ-1 решение. Я расскажу вам про не очевидные, на первый взгляд, но довольно простые решения, а также раскрою некоторые интересные моменты хакатонской кухни, которые, надеюсь, вдохновят вас на участие.
Статья будет полезна будущим участникам соревнований и data science специалистам, которые смогут применить описанные решения и практические советы в реальных задачах.