
The Economist: Десятки миллионов хирургических операций были отложены в связи с пандемией во всём мире. Больницам потребуется несколько месяцев, чтобы справиться с накопившимся отставанием. Национальная служба здравоохранения Англии (NHS) считает, что она уже отложила более двух миллионов запланированных операций, освободив 12 000 коек для пациентов c COVID-19.
The Hill: По оценкам Национального института аллергии и инфекционных заболеваний США из-за карантина почти половина от 650 000 американских онкологических больных не получают лечение, не назначаются две трети процедур физиотерапии, количество операций по трансплантации сократилось на 85%, экстренные оценки случаев инсульта снизились на 40% и более половины детей не были вовремя привиты, что всё вместе указывает на массовую будущую катастрофу в области здравоохранения.
Mirror: Последствия блокировки коронавируса могут привести к 200 000 дополнительных смертей в Великобритании из-за задержек и неправильного распределения приоритетов в системе здравоохранения, говорится в государственном докладе. За шесть месяцев было отменено 75% процедур по плановой медицинской помощи, а число госпитализаций в марте и апреле сократилось на четверть по сравнению с предыдущим периодом. На момент публикации статьи в Mirror в Великобритании зарегистрировано 45 000 смертей среди людей с положительным тестом на коронавирус.
The Telegraph: ЮНИСЕФ предупреждает, что карантин может унести больше жизней, чем коронавирус, а именно повлечь за собой свыше миллиона детских смертей от малярии, пневмонии и диареи в развивающихся странах в ближайшиее шесть месяцев. Только это значение в разы превышает официальное количество смертей во всём мире среди людей с положительным тестом на COVID-19 с начала пандемии.
The Hill: По оценкам Национального института аллергии и инфекционных заболеваний США из-за карантина почти половина от 650 000 американских онкологических больных не получают лечение, не назначаются две трети процедур физиотерапии, количество операций по трансплантации сократилось на 85%, экстренные оценки случаев инсульта снизились на 40% и более половины детей не были вовремя привиты, что всё вместе указывает на массовую будущую катастрофу в области здравоохранения.
Mirror: Последствия блокировки коронавируса могут привести к 200 000 дополнительных смертей в Великобритании из-за задержек и неправильного распределения приоритетов в системе здравоохранения, говорится в государственном докладе. За шесть месяцев было отменено 75% процедур по плановой медицинской помощи, а число госпитализаций в марте и апреле сократилось на четверть по сравнению с предыдущим периодом. На момент публикации статьи в Mirror в Великобритании зарегистрировано 45 000 смертей среди людей с положительным тестом на коронавирус.
The Telegraph: ЮНИСЕФ предупреждает, что карантин может унести больше жизней, чем коронавирус, а именно повлечь за собой свыше миллиона детских смертей от малярии, пневмонии и диареи в развивающихся странах в ближайшиее шесть месяцев. Только это значение в разы превышает официальное количество смертей во всём мире среди людей с положительным тестом на COVID-19 с начала пандемии.




 Знал бы прикуп — жил бы в Сочи.
Знал бы прикуп — жил бы в Сочи.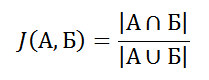


 Само наличие психологической деформации у какой-либо профессии, как правило, достаточно спорный момент ввиду того, что у разных людей она проявляется по-разному. Однако общую тенденцию можно выделить и, пожалуй, настало то время когда можно достаточно смело говорить, что программисты всё же имеют свой особенный психологический портрет который обусловлен их профессиональной деятельностью.
Само наличие психологической деформации у какой-либо профессии, как правило, достаточно спорный момент ввиду того, что у разных людей она проявляется по-разному. Однако общую тенденцию можно выделить и, пожалуй, настало то время когда можно достаточно смело говорить, что программисты всё же имеют свой особенный психологический портрет который обусловлен их профессиональной деятельностью.