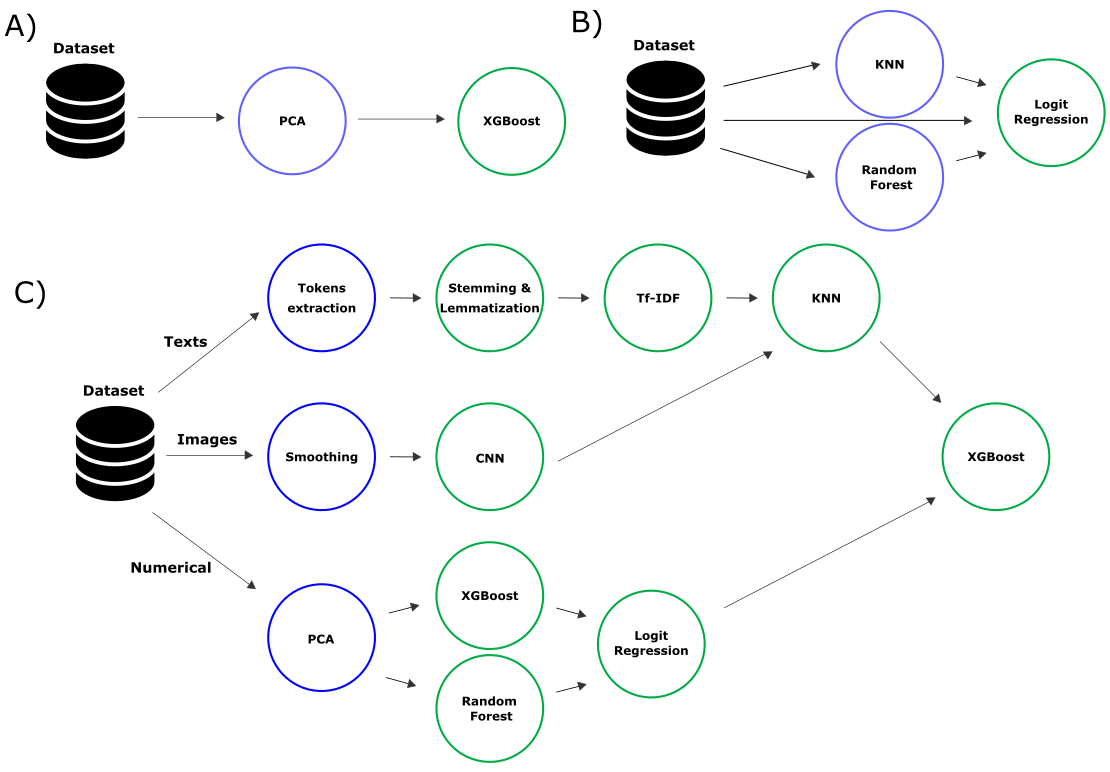
В этой серии статей мы рассмотрим, как на основе готовых моделей создавать приложения, использующие машинное обучение, и организовывать доступ пользователей к ним. Начнем с создания Web-приложения для классификации изображений на Streamlit и развертывания его на облачной платформе Heroku в бесплатном аккаунте. Этот подход подойдет для прототипов и персональных или учебных проектов.