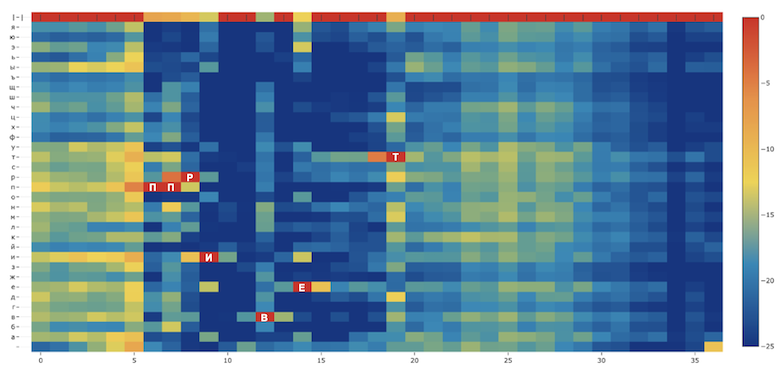

При разработке систем распознавания речи мы сталкиваемся с заблуждениями среди потребителей и разработчиков, в первую очередь связанными с разделением формы и сути. Одним из таких заблуждений является то, что в устной речи якобы "можно услышать" грамматически верные знаки препинания и пробелы между словами, когда по факту реальная устная речь и грамотная письменная речь очень сильно отличаются (устная речь скорее похожа на "поток" слегка разделенный паузами и интонацией, поэтому люди так не любят монотонно бубнящих докладчиков).
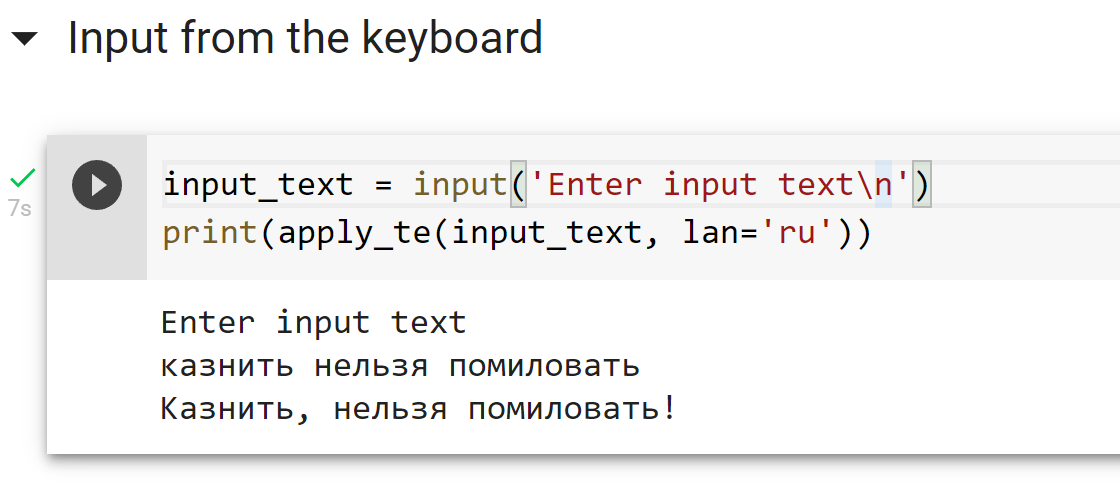
Понятно, что можно просто начинать каждое высказывание с большой буквы и ставить точку в конце. Но хотелось бы иметь какое-то относительно простое и универсальное средство расстановки знаков препинания и заглавных букв в предложениях, которые генерирует наша система распознавания речи. Совсем хорошо бы было, если бы такая система в принципе работала с любыми текстами.
По этой причине мы бы хотели поделиться с сообществом системой, которая:
- Расставляет заглавные буквы и основные знаки препинания (точка, запятая, дефис, вопросительный знак, восклицательный знак, тире для русского языка);
- Работает на 4 языках (русский, английский, немецкий, испанский);
- По построению должна работать максимально абстрактно на любом тексте и не основана на каких-то фиксированных правилах;
- Имеет минимальные нетривиальные метрики и выполняет задачу улучшения читабельности текста;
На всякий случай явно повторюсь — цель такой системы — лишь улучшать читабельность текста. Она не добавляет в текст информации, которой в нем изначально не было.