
 Порой встречаются такие артефакты природы, что начинаешь невольно задумывать о разных конспирологических теориях и альтернативной истории. Сегодня я хотел бы поговорить о разных малоизвестных и не очень аспектах операционной системы MS-DOS. Историй про дос на хабре было огромное множество: краткие очерки, подробная хронология, мемуары ностальгирующих, но никто ни разу не отмечал про MS-DOS 4.0 от 1985 года. Я считаю это очень важным звеном развития операционных систем для IBM PC, но удивительно мало информации о таком важном переходном этапе. Это буквально утерянная ветка доса и найти про нее информацию большая проблема. Что бы вы подумали если бы услышали о поддержке в DOS вытесняющей многозадачности, виртуальной памяти, свопа, семафоров и IPC. Фантастика?
Порой встречаются такие артефакты природы, что начинаешь невольно задумывать о разных конспирологических теориях и альтернативной истории. Сегодня я хотел бы поговорить о разных малоизвестных и не очень аспектах операционной системы MS-DOS. Историй про дос на хабре было огромное множество: краткие очерки, подробная хронология, мемуары ностальгирующих, но никто ни разу не отмечал про MS-DOS 4.0 от 1985 года. Я считаю это очень важным звеном развития операционных систем для IBM PC, но удивительно мало информации о таком важном переходном этапе. Это буквально утерянная ветка доса и найти про нее информацию большая проблема. Что бы вы подумали если бы услышали о поддержке в DOS вытесняющей многозадачности, виртуальной памяти, свопа, семафоров и IPC. Фантастика?MS-DOS, который мы никогда не видели
10 мин
Порой встречаются такие артефакты природы, что начинаешь невольно задумывать о разных конспирологических теориях и альтернативной истории. Сегодня я хотел бы поговорить о разных малоизвестных и не очень аспектах операционной системы MS-DOS. Историй про дос на хабре было огромное множество: краткие очерки, подробная хронология, мемуары ностальгирующих, но никто ни разу не отмечал про MS-DOS 4.0 от 1985 года. Я считаю это очень важным звеном развития операционных систем для IBM PC, но удивительно мало информации о таком важном переходном этапе. Это буквально утерянная ветка доса и найти про нее информацию большая проблема. Что бы вы подумали если бы услышали о поддержке в DOS вытесняющей многозадачности, виртуальной памяти, свопа, семафоров и IPC. Фантастика?



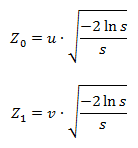

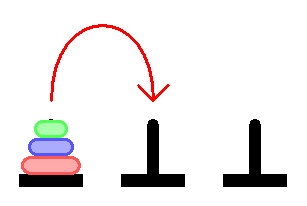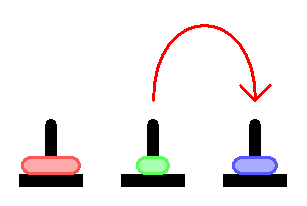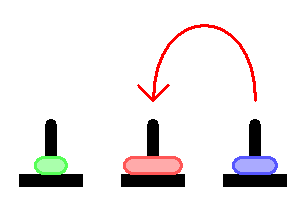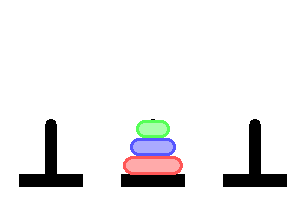 Пообщавшись с некоторыми знакомыми программистами, внезапно обнаружил, что не все знают про Ханойскую башню, а среди тех кто знает — мало кто понимает как решается эта задача.
Пообщавшись с некоторыми знакомыми программистами, внезапно обнаружил, что не все знают про Ханойскую башню, а среди тех кто знает — мало кто понимает как решается эта задача.

