
За последние несколько лет я очень полюбил GitLab CI. В основном за его простоту и функциональность. Достаточно просто создать в корне репозитория файл .gitlab-ci.yml , добавить туда несколько строчек кода и при следующем коммите запустится пайплайн с набором джобов, которые будут выполнять указанные команды.
А если добавить к этому возможности include и extends, можно делать достаточно интересные вещи: создавать шаблонные джобы и пайплайны, выносить их в отдельные репозитории и повторно использовать в разных проектах без копирования кода.
Но к сожалению, не всё так радужно, как хотелось бы. Инструкция script в GitLab CI очень низкоуровневая. Она просто выполняет те команды, которые ей переданы в виде строк. Писать большие скрипты внутри YAML не очень удобно. По мере усложнения логики количество скриптов увеличивается, они перемешиваются с YAML делая конфиги нечитаемыми и усложняя их поддержку.
Мне очень не хватало какого-то механизма, который бы упростил разработку больших скриптов. В результате у меня родился микрофреймворк для разработки GitLab CI, про который я и хочу рассказать в этой статье (на примере простого пайплайна для сборки docker-образов).












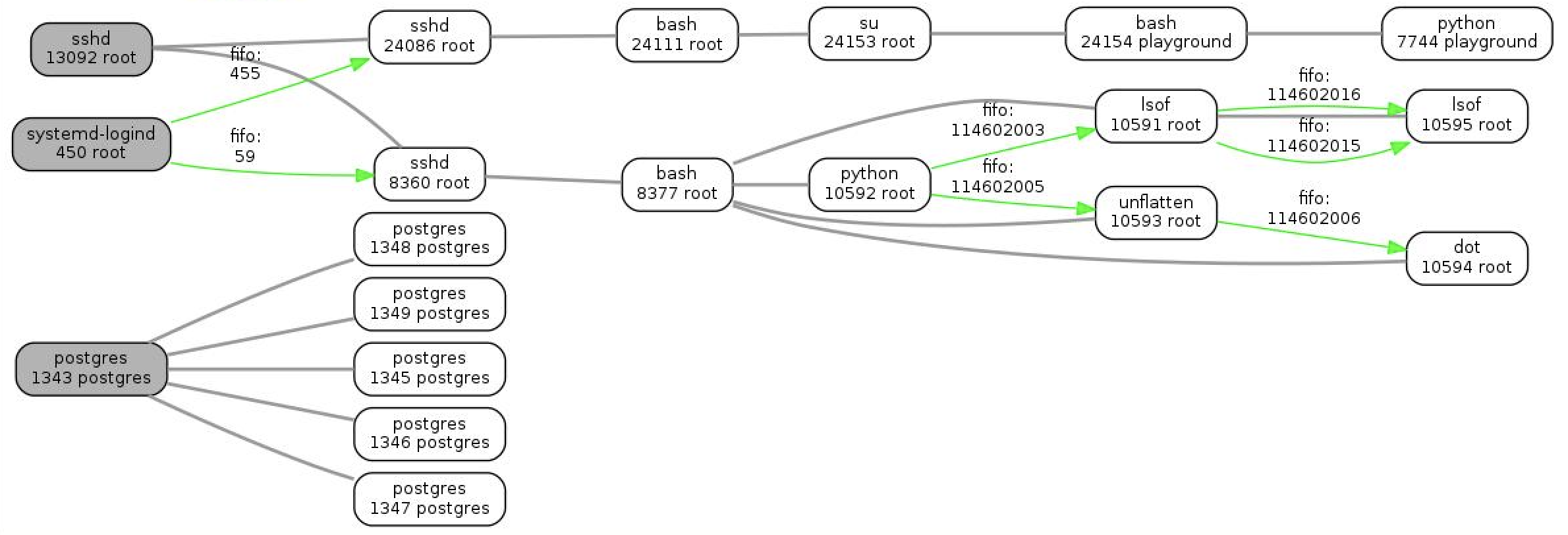
 Чтобы сделать мониторинг полезным, нам приходится прорабатывать разные сценарии вероятных проблем и проектировать дашборды и триггеры таким образом, чтобы по ним сразу была понятна причина инцидента.
Чтобы сделать мониторинг полезным, нам приходится прорабатывать разные сценарии вероятных проблем и проектировать дашборды и триггеры таким образом, чтобы по ним сразу была понятна причина инцидента. 

 Про разделение скорости, приоритезацию, работу шейпера и всего остального уже много всего написано и нарисовано. Есть множество статей, мануалов, схем и прочего, в том числе и написанных мной материалов. Но судя по возрастающим потокам писем и сообщений, пересматривая предыдущие материалы, я понял — что часть информации изложена не так подробно как это необходимо, другая часть просто морально устарела и просто путает новичков. На самом деле QOS на микротике не так сложен, как кажется, а кажется он сложным из-за большого количества взаимосвязанных нюансов. Кроме этого можно подчеркнуть, что крайне тяжело освоить данную тему руководствуясь только теорией, только практикой и только прочтением теории и примеров. Основным костылем в этом деле является отсутствие в Mikrotik визуального представления того, что происходит внутри очереди PCQ, а то, что нельзя увидеть и пощупать приходится вообразить. Но воображение у всех развито индивидуально в той или иной степени.
Про разделение скорости, приоритезацию, работу шейпера и всего остального уже много всего написано и нарисовано. Есть множество статей, мануалов, схем и прочего, в том числе и написанных мной материалов. Но судя по возрастающим потокам писем и сообщений, пересматривая предыдущие материалы, я понял — что часть информации изложена не так подробно как это необходимо, другая часть просто морально устарела и просто путает новичков. На самом деле QOS на микротике не так сложен, как кажется, а кажется он сложным из-за большого количества взаимосвязанных нюансов. Кроме этого можно подчеркнуть, что крайне тяжело освоить данную тему руководствуясь только теорией, только практикой и только прочтением теории и примеров. Основным костылем в этом деле является отсутствие в Mikrotik визуального представления того, что происходит внутри очереди PCQ, а то, что нельзя увидеть и пощупать приходится вообразить. Но воображение у всех развито индивидуально в той или иной степени.