Как часто вас посещала мысль о трудоустройстве за границей, будь то просто временная работа или переезд на постоянное место жительство? Какую страну выбрать? Возможно ли пройти собеседования за тысячи километров по телефону и получить джоб-офер? Как будет выглядеть переезд и жизнь в другой стране? В данной статье я бы хотел поделиться личным опытом и опытом многих моих друзей работающих за рубежом.

Dmitry Gil
@HiltoN
Пользователь
Эффективная обработка фотографий в Photoshop
6 мин

Читая статьи о Photoshop, я часто удивляюсь тому, насколько многие авторы усложняют решение по сути простых задач по обработке. Этим страдают и многие «монументальные» писатели, например Дэн Маргулис. Но ему это простительно – его задача написать о всех тонкостях и нюансах процесса обработки, рассмотреть его со всех ракурсов и сторон. Хотя именно эта особенность подачи материала в его книгах отталкивает многих читателей.
На самом деле, корни подобных способов «увеличить резкость в 40 действий» растут из очень простой вещи – люди, которые пишут эти уроки, никогда не работали с большим объемом фотографий. То есть, как правило, у них есть пара фотографий и они готовы в процессе их обработки убить вечер-другой. Но когда у тебя идут постоянные заказы, и с каждой фотосессии тебе надо серьезно обработать несколько десятков кадров – начинаешь задумываться о более простых и удобных способах обработки.
О них мы сегодня и поговорим. Я расскажу вам о пяти простых, но очень эффективных инструментах Photoshop, которые я постоянно использую в своей работе.
Офис компании Boomburum
19 мин

Осторожно, трафик! Но можно хотя бы посмотреть картинки )
Идея создать дома свой «рабочий кабинет» у меня зрела давно – как-то сам дошел до осознания его необходимости, хотя немалый вклад в начинания сделал этот давний пост на Хабре. У меня было своё рабочее место – большой удобный стол, где помещалось практически всё и даже больше… но, по сути, он был проходным двором – все время кто-то ходил, был рядом, отвлекал… такое очень часто мешает сосредоточиться и начать работать. Иногда, бывает, сидишь весь вечер за компом и понимаешь, что абсолютно ничего не сделал, хотя родным заявил «так, мне надо поработать».
Непрофильные вопросы на интервью
4 мин
*внимание, это очень спорный и субъективный текст*
Иногда собеседования могут превратиться в скучную рутину и это может плохо сказаться на впечатлении от кандидата, и впечатлении кандидата о вас. Для меня собеседования всегда были возможностью узнать для себя что-то новое параллельно процессу оценивания знаний кандидата на ту или иную позицию. Но ведь кроме сугубо профильных вопросов хочется еще и кандидата узнать немного больше. Как правило, этим занимается HR-служба, но помимо общей характеристики бывает важно увидеть, как человек думает и ведет себя в вопросах «не о погоде».
Вот некоторые из вопросов, которые я задаю на интервью, чтобы его разнообразить.
Объясните ребенку, что такое обфускация кода, простыми словами, так, чтобы тот понял.
В качестве ребёнка выступаю я сам. Вместо «обфускация кода» может быть любое понятие, в зависимости от позиции. Этот вопрос помогает увидеть, может ли человек сделать сложное простым.
Я хочу работать в Google! Телефонное интервью (часть 1)
4 мин
Привет Хабр! Давно не писал. Да это и понятно. Защита диссертации, получение PhD, а сейчас ещё и активный поиск работы — всё это занимает очень много драгоценного времени. Но разговор сегодня пойдёт не о том. Хотелось бы поделиться с Вами, уважаемые хабралюди, ресурсами и описанием процесса подготовки к телефонному техническому интервью с Гуглом, первый технический этап которого я уже прошёл, и теперь готовлюсь ко второму, который будет в пятницу.
«Dense_rank()» vs «Max()» или расследование с неожиданным концом
8 мин
Здравствуйте, коллеги.
В этой статье я расскажу о своих изысканиях в вопросе: «А что же лучше: dense_rank() или max()» и, конечно, почему эти изыскания завершились с неожиданным, по крайней мере для меня, результатом.
В этой статье я расскажу о своих изысканиях в вопросе: «А что же лучше: dense_rank() или max()» и, конечно, почему эти изыскания завершились с неожиданным, по крайней мере для меня, результатом.
Тонкости работы в командной строке Windows
3 мин
Недавно я вырос из лютого эникея в очень большой компании, до скромного сисадмина надзирающего за сетью в 10 ПК. И, как очень ленивый сисадмин, столкнулся с задачами по автоматизации своей деятельности. Полгода назад я еще не знал, что в командной строке Windows есть конвейеры. Это стало первым шокирующим открытием. И я пошел дальше, и выяснилось, что там, где я раньше писал утилитки на C#, Delphi или громоздкие скрипты с вложенными циклами, можно было обойтись парой команд
Не буду рассказывать о банальностях, типа о перечислении файлов и папок клавишей
forfiles или robocopy.Не буду рассказывать о банальностях, типа о перечислении файлов и папок клавишей
Tab. Под хабракатом расскажу о том, что может быть полезно начинающим админам и эникеям.Монолог инкогнито с одной айтишной конференции
7 мин
Disclaimer. Монолог ниже является стенограммой выступления одного из докладчиков на одной из айтишных конференций. Автор поста всего лишь публикует его здесь с разрешения докладчика.
Всем привет!
В программе мероприятий вам обещали инкогнито долларового миллионера. Увы, он отбыл на воды в Баден-Баден лечить переговорную печень и пришлось затыкать дыру кем попало.
Меня зовут Сергей. Чтобы сказать про себя «я плохой докладчик», нужно хотя бы им, докладчиком, быть. Я вообще не оно. Свою первую и одну из последних презентаций я провел в 18 лет в Испании, перед аудиторией человек в 100. Мой весьма средний на тот момент английский синхронно переводили на испанский, народ зевал и почесывал репы, ожидая когда ЭТО недоразумение закончит блеять и объявится кофебрейк.
Сказать что мне было стыдно — это ничего не сказать, красный как рак, я свалил вторым выходом, забился в свой номер и боялся показаться на глаза. Всякие public professionals типа Карнеги сказали бы «позор!» и «never again!». Для себя я решил — все что угодно, хоть жигулевское пиво по пятницам, только не публичные экзекуции
К чему это я? Многие, глядя на ИТшников, путают скромность со стеснительностью. Да и фиг с ними. Главное — чтобы мы сами не путали. Я — стеснительный, поэтому буду смотреть в пол и читать по бумажке. Я бы выпил, конечно, для смелости, граммчиков сто (а лучше сто пятьдесят), но организаторы запретили. Ну что, пусть фигово, зато честно!
Я владелец компании П, в которой мы уже лет 13 или 14 занимаемся разработкой всякой фигни, про которую никто не слышал. Не имея таланта делать что-то красивое и эстетичное, мы довольствуемся подводной частью айсберга: софт-свитчи и клиенты для IP-телефонии, аппаратно-программные решения для высоконагруженных систем обработки контента, системы имперсонализации web и e-mail для виртуального присутствия, облачное видеонаблюдение, несколько справочных и торговых интернет-порталов, ну и еще пара проектов в стадии стартапа, говорить о которых рано, потому что стыдно
Все о чем собираюсь сказать, основано исключительно на личном опыте, относится к маленьким компаниям и совершенно не обязано работать в больших, хотя иногда бывает. За 25 лет, отданных айти-бизнесу, я умудрился побывать в разных шкурах, от техника, подносящего кофе джуниор девелоперам, до владельца компаний, которому не надо вставать в 8. Посредине между этими сомнительными гранями было, наверное, два главных увлечения — язык Си и темное ирландское пиво. Увы, и то и другое со временем пришлось сильно урезать.
Всем привет!
В программе мероприятий вам обещали инкогнито долларового миллионера. Увы, он отбыл на воды в Баден-Баден лечить переговорную печень и пришлось затыкать дыру кем попало.
Меня зовут Сергей. Чтобы сказать про себя «я плохой докладчик», нужно хотя бы им, докладчиком, быть. Я вообще не оно. Свою первую и одну из последних презентаций я провел в 18 лет в Испании, перед аудиторией человек в 100. Мой весьма средний на тот момент английский синхронно переводили на испанский, народ зевал и почесывал репы, ожидая когда ЭТО недоразумение закончит блеять и объявится кофебрейк.
Сказать что мне было стыдно — это ничего не сказать, красный как рак, я свалил вторым выходом, забился в свой номер и боялся показаться на глаза. Всякие public professionals типа Карнеги сказали бы «позор!» и «never again!». Для себя я решил — все что угодно, хоть жигулевское пиво по пятницам, только не публичные экзекуции
К чему это я? Многие, глядя на ИТшников, путают скромность со стеснительностью. Да и фиг с ними. Главное — чтобы мы сами не путали. Я — стеснительный, поэтому буду смотреть в пол и читать по бумажке. Я бы выпил, конечно, для смелости, граммчиков сто (а лучше сто пятьдесят), но организаторы запретили. Ну что, пусть фигово, зато честно!
Я владелец компании П, в которой мы уже лет 13 или 14 занимаемся разработкой всякой фигни, про которую никто не слышал. Не имея таланта делать что-то красивое и эстетичное, мы довольствуемся подводной частью айсберга: софт-свитчи и клиенты для IP-телефонии, аппаратно-программные решения для высоконагруженных систем обработки контента, системы имперсонализации web и e-mail для виртуального присутствия, облачное видеонаблюдение, несколько справочных и торговых интернет-порталов, ну и еще пара проектов в стадии стартапа, говорить о которых рано, потому что стыдно
Все о чем собираюсь сказать, основано исключительно на личном опыте, относится к маленьким компаниям и совершенно не обязано работать в больших, хотя иногда бывает. За 25 лет, отданных айти-бизнесу, я умудрился побывать в разных шкурах, от техника, подносящего кофе джуниор девелоперам, до владельца компаний, которому не надо вставать в 8. Посредине между этими сомнительными гранями было, наверное, два главных увлечения — язык Си и темное ирландское пиво. Увы, и то и другое со временем пришлось сильно урезать.
Oracle Business Intelligence — обзор
8 мин
Привет, хабр. По работе мне приходится иметь дело с OBIEE (Oracle Business Intelligence Enterprise Edition) в качестве разработчика и администратора, поэтому я решил поделиться тем объемом знаний, который успел накопить. Надеюсь, кому-нибудь это поможет в освоении системы. Сначала я планирую рассказать про систему в целом, затем — про архитектуру и взаимодействие компонентов, а в конце — рассказать про те особенности, с которыми пришлось столкнуться за время работы.
Oracle Business Intelligence Enterprise Edition (OBIEE, OBI) — программная платформа для решения задач бизнес-аналитики: интерактивных и публикуемых отчетов, мониторинга KPI и бизнес-процессов. Является потомком Siebel Analytics. Основные функциональные части, доступные пользователям:
Обзор системы
Oracle Business Intelligence Enterprise Edition (OBIEE, OBI) — программная платформа для решения задач бизнес-аналитики: интерактивных и публикуемых отчетов, мониторинга KPI и бизнес-процессов. Является потомком Siebel Analytics. Основные функциональные части, доступные пользователям:
- Answers (также называются Interactive Dashboards) — построение интерактивных отчетов, доступных для пользователей через веб-интерфейс OBIEE. Единицей отчетности является analysis — простой отчет, как правило, включающий в себя одно отображение (таблицу, график, диаграмму и т.п.). Analysis объединяются в информационные панели (Dashboards), с которыми работают конечные пользователи. Информационные панели также могут включать в себя приглашения (prompts) — элементы настройки, с помощью которых пользователь может взаимодействовать с панелью.
- Publisher (также иногда в него включают Delivers) — средство создания и рассылки статических отчетов. Т.к. publisher развился из отдельного продукта, то в нем есть возможность строить отчеты на собственной модели данных, независимой от модели данных OBI, однако можно использовать и общую модель. Также есть возможность рассылки существующих отчетов из answers.
- Action Framework — набор средств для выполнения каких-либо автоматизированных действий из OBIEE — например, рассылка отчетов по достижению показателем определенного значения, вызова внешних веб-служб, вызова java кода и т.п. Действия могут быть объединены в цепочки. Возможно настройка различных каналов оповещения пользователей — e-e-mail, sms, пейджер и т.п.
- Scorecard and Strategy Management — средства для отслеживания ключевых параметров производительности (KPI) и работы с системами показателей (Scorecard — http://en.wikipedia.org/wiki/Balanced_scorecard). Используются для наглядного отображения статуса выполнения целей (компании, проекта). Доступ пользователей, как и в случае с answers, осуществляется через веб-интерфейс.
- Marketing — средства интеграции с Siebel Marketing.
- Office Tools — средства интеграции с Microsoft Office.
Именование объектов в Oracle. Взгляд «со стороны»
15 мин
«Старая песня о главном»
«Стандарты именование объектов БД» и «правила оформления кода» темы не новые. Так или иначе, к вопросу выработки или заимствования таких стандартов и правил приходят все команды разработчиков. При желании в сети можно найти статьи и презентации по данной теме, а так же примеры и шаблоны различных соглашений. Многие из них безусловно полезны, некоторые — практически идеальны, если бы не одна маленькая оговорка: они написаны разработчиками и для разработчиков.
К сожалению, в моей субъективной реальности разработчики являют собой лишь некую абстракцию. Эдакие фантомы по ту сторону телефонной трубки, от которых меня отделяют тысячи километров и 3 часовых пояса. Прямого доступа в их коллективный мозг у меня нет. Доступны только образы, порожденные данным мозгом,- в виде объектов эксплуатируемой системы.
В принципе, пожелания по оформлению и именованию у «прикладника» (администратора приложения/технолога) и разработчика на 90 процентов совпадают. Но существуют все же некоторые отличия в восприятии «читателя» и «писателя», о которых я хотел бы поговорить.
Шпаргалка по Redis
8 мин
Туториал
Про Redis (официальный сайт, материалы на Хабре) написано много, но мне до сего дня не хватало материала, который послужил бы шпаргалкой по его практическому использованию, а так же справочником по базовым теоретическим моментам. Постараюсь заполнить этот пробел в богатой базе знаний Хабра.
Я поставил перед собой цель показать возможности Redis с помощью примеров кода. После публикации приму любые предложения по улучшению материала.
Здесь используется общение с сервером через консольный клиент, но, основываясь на приведенных примерах, можно легко найти реализацию этих примеров в клиентских библиотеках на вашем любимом языке.
Redis — хранилище данных в формате «ключ-значение». Факты о ключах:
Про типы данных Redis есть отдельная хорошая статья: «Структуры данных, используемые в Redis».
Я поставил перед собой цель показать возможности Redis с помощью примеров кода. После публикации приму любые предложения по улучшению материала.
Здесь используется общение с сервером через консольный клиент, но, основываясь на приведенных примерах, можно легко найти реализацию этих примеров в клиентских библиотеках на вашем любимом языке.
Ключи
Redis — хранилище данных в формате «ключ-значение». Факты о ключах:
- Ключи в Redis — бинарно-безопасные (binary safe) строки.
- Слишком длинные ключи — плохая идея, не только из-за занимаемой памяти, но так же и в связи с увеличением времени поиска определенного ключа в множестве в связи с дорогостоящим сравнением.
- Хорошая идея — придерживаться схемы при построении ключей: «object-type:id:field».
Типы данных Redis
- Строки (strings). Базовый тип данных Redis. Строки в Redis бинарно-безопасны, могут использоваться так же как числа, ограничены размером 512 Мб.
- Списки (lists). Классические списки строк, упорядоченные в порядке вставки, которая возможна как со стороны головы, так и со стороны хвоста списка. Максимальное количество элементов — 232 — 1.
- Множества (sets). Множества строк в математическом понимании: не упорядочены, поддерживают операции вставки, проверки вхождения элемента, пересечения и разницы множеств. Максимальное количество элементов — 232 — 1.
- Хеш-таблицы (hashes). Классические хеш-таблицы или ассоциативные массивы. Максимальное количество пар «ключ-значение» — 232 — 1.
- Упорядоченные множества (sorted sets). Упорядоченное множество отличается от обычного тем, что его элементы упорядочены по особому параметру «score».
Про типы данных Redis есть отдельная хорошая статья: «Структуры данных, используемые в Redis».
Десятка лучших консольных команд
2 мин
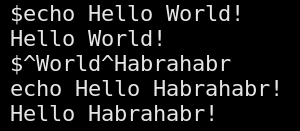 В данном посте я расскажу о наиболее интересных командах, которые могут быть очень полезны при работе в консоли. Однозначных критериев определения какая команда лучше другой — нет, каждый сам для своих условий выбирает лучшее. Я решил построить список команд на основе наиболее рейтинговых приемов работы с консолью от commandlinefu.com, кладовой консольных команд. Результат выполнения одной из таких команд под Linux приведен на картинке. Если заинтересовало, прошу под кат.
В данном посте я расскажу о наиболее интересных командах, которые могут быть очень полезны при работе в консоли. Однозначных критериев определения какая команда лучше другой — нет, каждый сам для своих условий выбирает лучшее. Я решил построить список команд на основе наиболее рейтинговых приемов работы с консолью от commandlinefu.com, кладовой консольных команд. Результат выполнения одной из таких команд под Linux приведен на картинке. Если заинтересовало, прошу под кат.UNPIVOT
5 мин
Туториал
За время моей работы, я сталкивался с широким кругом задач. Одни задачи требовали монотонной работы, другие сводились к чистому креативу.
Наиболее интересные задачи, которые я могу сейчас вспомнить, так или иначе, затрагивали вопросы оптимизации запросов.
Оптимизация – это, в первую очередь, поиск оптимального плана запроса. Однако, что делать в ситуации, когда стандартная конструкция языка выдает план, который очень далек от оптимального?
С такого рода проблемой я столкнулся, когда применял конструкцию UNPIVOT для преобразования столбцов в строки.
Путем небольшого сравнительного анализа, для UNPIVOT была найдена более эффективная альтернатива.
Наиболее интересные задачи, которые я могу сейчас вспомнить, так или иначе, затрагивали вопросы оптимизации запросов.
Оптимизация – это, в первую очередь, поиск оптимального плана запроса. Однако, что делать в ситуации, когда стандартная конструкция языка выдает план, который очень далек от оптимального?
С такого рода проблемой я столкнулся, когда применял конструкцию UNPIVOT для преобразования столбцов в строки.
Путем небольшого сравнительного анализа, для UNPIVOT была найдена более эффективная альтернатива.
Загружаем данные в Oracle
14 мин
Туториал
В своей предыдущей статье я показал, что при использовании асинхронных запросов, скорость опроса устройств по протоколу SNMP может достигать 9000 запросов в секунду (при условии, что у нас есть достаточное количество устройств для формирования такого потока ответов). Вопрос о том, что делать с этим потоком данных остался открытым.
Обычной практикой является обработка данных мониторинга посредством RDBMS (таких как Oracle Database). Но способны ли традиционные реляционные базы данных справиться с такой нагрузкой? Попробуем в этом разобраться.
Обычной практикой является обработка данных мониторинга посредством RDBMS (таких как Oracle Database). Но способны ли традиционные реляционные базы данных справиться с такой нагрузкой? Попробуем в этом разобраться.
Linux pipes tips & tricks
8 мин
Туториал
Pipe — что это?
Pipe (конвеер) – это однонаправленный канал межпроцессного взаимодействия. Термин был придуман Дугласом Макилроем для командной оболочки Unix и назван по аналогии с трубопроводом. Конвейеры чаще всего используются в shell-скриптах для связи нескольких команд путем перенаправления вывода одной команды (stdout) на вход (stdin) последующей, используя символ конвеера ‘|’:
cmd1 | cmd2 | .... | cmdN
Например:
$ grep -i “error” ./log | wc -l
43
grep выполняет регистронезависимый поиск строки “error” в файле log, но результат поиска не выводится на экран, а перенаправляется на вход (stdin) команды wc, которая в свою очередь выполняет подсчет количества строк.
Логика
Конвеер обеспечивает асинхронное выполнение команд с использованием буферизации ввода/вывода. Таким образом все команды в конвейере работают параллельно, каждая в своем процессе.
Размер буфера начиная с ядра версии 2.6.11 составляет 65536 байт (64Кб) и равен странице памяти в более старых ядрах. При попытке чтения из пустого буфера процесс чтения блокируется до появления данных. Аналогично при попытке записи в заполненный буфер процесс записи будет заблокирован до освобождения необходимого места.
Важно, что несмотря на то, что конвейер оперирует файловыми дескрипторами потоков ввода/вывода, все операции выполняются в памяти, без нагрузки на диск.
Вся информация, приведенная ниже, касается оболочки bash-4.2 и ядра 3.10.10.
Простой дебаг
Утилита strace позволяет отследить системные вызовы в процессе выполнения программы:
$ strace -f bash -c ‘/bin/echo foo | grep bar’
....
getpid() = 13726 <– PID основного процесса
...
pipe([3, 4]) <– системный вызов для создания конвеера
....
clone(....) = 13727 <– подпроцесс для первой команды конвеера (echo)
...
[pid 13727] execve("/bin/echo", ["/bin/echo", "foo"], [/* 61 vars */]
.....
[pid 13726] clone(....) = 13728 <– подпроцесс для второй команды (grep) создается так же основным процессом
...
[pid 13728] stat("/home/aikikode/bin/grep",
...
Сломается ли база, если выдернуть сервер из розетки, или потроха DB ORACLE для чайников
5 мин
Писал для коллег — программистов, далёких от предметной области, которые действительно, искренне не понимали, что такого сложного в базе данных. Они хотели хранить критические данные в простых файлах. Я задавал им каверзные вопросы о надёжности, скорости и одновременном доступе, они пытались «на ходу» придумать хитрые решения. В конце они трезво оценили требуемый объём кода и поняли, что им придётся написать свой маленький ORACLE или, хотя бы, MySQL. Затем я рассказал им, как были решены эти проблемы в DB ORACLE, их поразило изящество некоторых алгоритмов. Лекция понравилась, и я решил выложить её в открытый доступ.
Хранение деревьев в базе данных. Часть первая, теоретическая
4 мин
Туториал
Полгода назад написал бандл ClosureTable для фреймворка Laravel 3. Поводом для написания стала вот эта замечательная презентация Билла Карвина о способах хранения и обработки иерархических данных в MySQL с использованием PHP.
Итак. Существует несколько шаблонов проектирования баз данных для хранения и обработки иерархических структур:
Итак. Существует несколько шаблонов проектирования баз данных для хранения и обработки иерархических структур:
- Adjacency List («список смежности»)
- Materialized Path («материализованный путь»)
- Nested Sets («вложенные множества»)
- Closure Table («таблица связей»)
Что нового в SQLite (2013)?
5 мин
В последнем обновлении SQLite планировщик запросов претерпел серьезные изменения и отныне зовется Планировщик Запросов Следующего Поколения. Мы решили сделать небольшой обзор нового планировщика и некоторых других значительных обновлений SQLite в текущем году. Новый функционал может оказаться полезным разработчикам.
Выполнение внешнего файла из БД Oracle с целью получения информации о дисковом пространстве
5 мин
Зачастую для тех или иных нужд возникает необходимость выполнить команду OS из pl/sql или даже sql внутри Oracle Database.
Ниже описывается один из способов и его применение в задаче определения доступного дискового пространства.
Предлагаемый способ заключается в использование добавленного в 11.2 функционала «Препроцессинг данных внешних таблиц».
Ниже описывается один из способов и его применение в задаче определения доступного дискового пространства.
Предлагаемый способ заключается в использование добавленного в 11.2 функционала «Препроцессинг данных внешних таблиц».
Первые несколько миллисекунд HTTPS соединения
10 мин
Перевод
После нескольких часов чтения обзоров, Боб с нетерпением нажал на кнопку перехода к оформлению заказа на галлон цельного молока, и…
Воу, что только что произошло?
Воу, что только что произошло?