Если нужно запустить сайт или веб-приложение в облаке, то привычным для многих способом будет аренда виртуальной машины с определённым объёмом памяти и параметрами CPU. Берём ресурсы чуть-чуть с запасом, чтобы приложение не тормозило и не теряло пользовательские запросы, и платим постоянный тариф за аренду мощностей провайдера. Но в таком случае всегда есть переплата за фактически неиспользуемую часть ресурсов, а часть ответственности за надёжность решения несёт сам пользователь.
Облачные решения сегодня предлагают несколько вариантов запуска контейнеров, и serverless-подход — один из них. Если разместить код приложения в Serverless Containers, облако само запустит нужный контейнер с вашим сервисом тогда, когда появится потребность в его вызове. Разница не только в тарификации по времени работы контейнера, но и в эластичности. Если нагрузка резко возрастёт, то сервис запустит дополнительные экземпляры контейнера. Но и здесь есть свои ограничения.
В этой статье покажем, какие есть способы запуска контейнеров в Yandex Cloud, и расскажем, как и когда лучше запускать контейнеры в Serverless Containers. Материал может пригодиться бэкенд-разработчикам, DevOps-инженерам и системным администраторам.
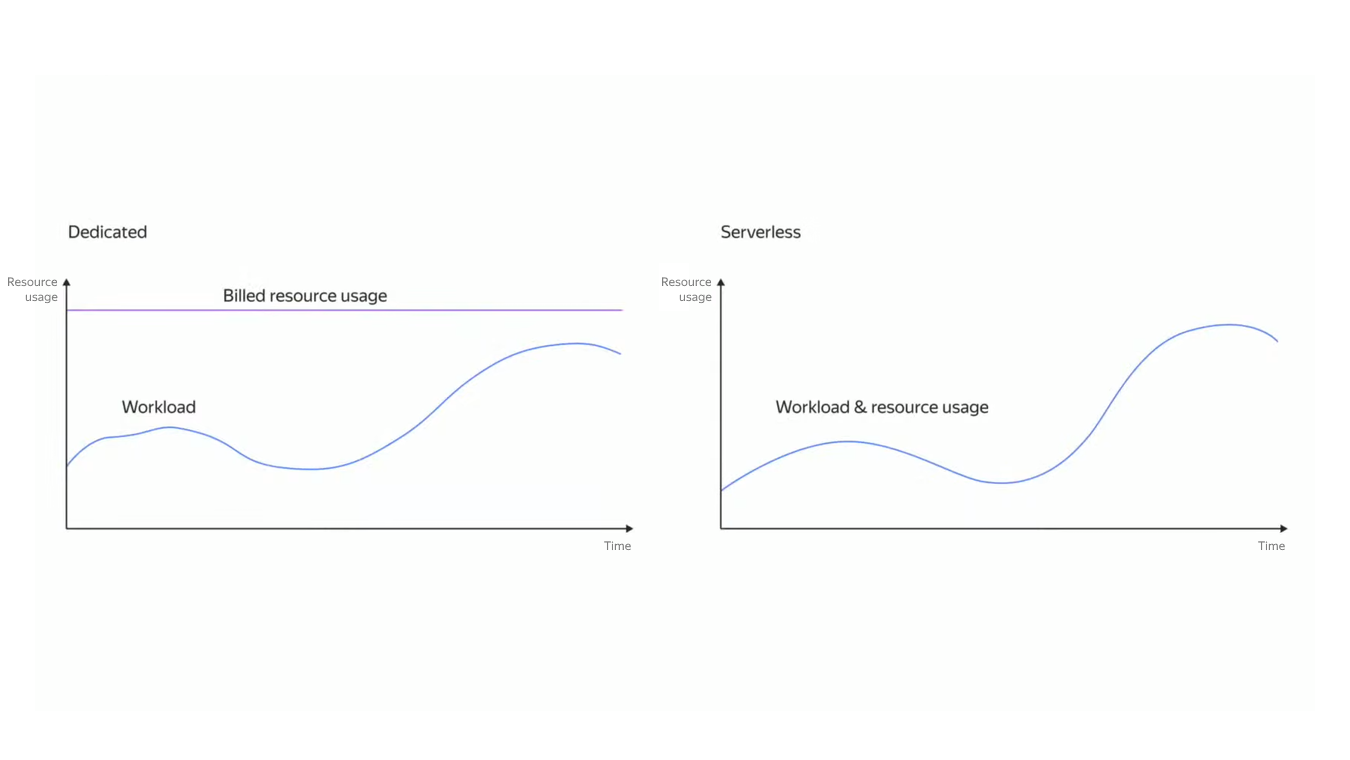
Облачные решения сегодня предлагают несколько вариантов запуска контейнеров, и serverless-подход — один из них. Если разместить код приложения в Serverless Containers, облако само запустит нужный контейнер с вашим сервисом тогда, когда появится потребность в его вызове. Разница не только в тарификации по времени работы контейнера, но и в эластичности. Если нагрузка резко возрастёт, то сервис запустит дополнительные экземпляры контейнера. Но и здесь есть свои ограничения.
В этой статье покажем, какие есть способы запуска контейнеров в Yandex Cloud, и расскажем, как и когда лучше запускать контейнеры в Serverless Containers. Материал может пригодиться бэкенд-разработчикам, DevOps-инженерам и системным администраторам.