
Медитируем под звуки правок, запасаемся тайлами, ищем места из аниме и готовимся к 20-летию OpenStreetMap.

Аналитик-разработчик
Медитируем под звуки правок, запасаемся тайлами, ищем места из аниме и готовимся к 20-летию OpenStreetMap.

Привет! Это мой первый пост на Хабре, буду рад услышать профессиональное и не очень мнение по поводу этой статьи.
Реализуем Яндекс Карты в KMP проекте с использованием Compose Multiplatform. Нестандартное решение с интерфейсом на Swift и передачей кода через DI.

Здравствуй, дорогой читатель.
Спешу поделиться тем, как на самом деле найти геоданные без регистрации и СМС. По чесноку. Без всяких-яких. И даже “подписывайтесь на телеграмм канал” - не будет, у меня его и нет…
И речь пойдёт про инструмент Osmosis.

In this tutorial, I want to talk about the practical experience of native compilation of a production application written in Kotlin with Spring Boot and Gradle using GraalVM. I’ll start right away with the pros and cons of the native compilation feature itself and where it can be useful, and then I’ll move directly to the build process for MacOS and Windows.
At the end of the article, in the afterword block, I will talk in more detail about the project and why such a need arose, given quite a few limitations and pitfalls of supporting native compilation both from Spring Boot and from GraalVM.

Cloak — это подключаемый транспорт, который расширяет возможности традиционных прокси-инструментов, таких как OpenVPN, Shadowsocks и Tor для обхода сложной цензуры и дискриминации данных.
Руководство будет включать:
1. Предисловие
2. Описание работы Cloak
3. Настройку сервера Cloak
4. Настройку клиента Cloak на OpenWRT
5. Настройку клиента OpenVPN
В серии предыдущих статей я описывал, почему повсеместно используемые VPN- и прокси-протоколы такие как Wireguard и L2TP очень уязвимы к выявлению и могут быть легко заблокированы цензорами при желании, обозревал существующие гораздо более надежные протоколы обхода блокировок, клиенты для них, а также описывал настройку сервера для всего этого.
Но кое о чем мы не поговорили. Во второй статье я вскользь упомянул самую передовую и недетектируемую технологию обхода блокировок под названием XTLS-Reality, и пришло время рассказать о ней поподробнее, а именно - как настроить клиент и сервер для нее.
Кроме того, что этот протокол еще более устойчив к выявлению, приятным фактом будет и то, что настройка сервера XTLS-Reality гораздо проще, чем описанные ранее варианты - после предыдущих статей я получил довольно много комментариев типа "А что так сложно, нужен домен, нужны сертификаты, и куча всего" - теперь все будет гораздо проще.

Как известно, в 2007 году кроме того, что деревья были выше, а трава зеленей, еще и в Интернете не было особых ограничений - можно было открыть почти любой сайт и наслаждаться им. До ковровых блокировок Telegram оставалось ещё 10 лет... К сожалению, в наше время такой возможности уже нет. Причины тут всем известны, в частности, некоторые компании уже не предоставляют своих услуг в России.
Хорошо, что существует возможность в рамках домашней сети восстановить свободный Интернет таким, каким он был в 2007-м. Именно этим мы и займемся. Стоит отметить, что в 2007 году довольно часто можно было встретить подключения на скорости 64-128 Кб/с, а то и вовсе dial-up; Wi-Fi был редкостью, а мобильная связь - довольно дорогим удовольствием. Однако, эти особенности того времени мы постараемся не воспроизводить.
Представляю вашему вниманию Freeroute - простой маршрутизатор, который позволяет направлять трафик на разные шлюзы в зависимости от домена назначения. Free в названии, как водится, означает свободный, а не бесплатный.
Последнее время вижу очень много статей на тему vds с впн для тех или иных задач.
В основном людям нужен такой сервер для обычного неторопливого серфинга.
В связи с тем что сервер за пределами РФ стало получить сложнее и дороже решил поделиться этим способом. Он подойдет если у вас есть возможность создать виртуалку дома или рф хостинг который заметно дешевле зарубежного.


Некоммерческая организация LAION и энтузиасты по всему миру занимаются разработкой Open Assistant — это проект, цель которого в предоставлении всем желающим доступа к продвинутой большой языковой модели, основанной на принципах чат-бота, с конечной целью революции в инновациях в области обработки естественного языка...

Работа с Ingress-контроллерами обычно предполагает работу с Kubernetes в облаке, где внешние ip присваиваются автоматически. Я изучаю Kubernetes, обходясь обычным ноутбуком за NAT, на котором в виртуальных машинах запущены разные разновидности Kubernetes. Когда я разбирался с Ingress-контроллером, у меня возникло непреодолимое желание завести в него публичный ip и обратиться к нему извне. Давайте посмотрим, как это можно сделать.

Привет! Меня зовут Сергей Ермейкин, я Junior DevOps engineer в центре разработки IT-компании Lad. В моей первой статье на Хабре я расскажу про сборку своих GUI/GPU образов и покажу, как настроить хостовую и Kubernetes системы на примере игры GTA:VC.
В детстве мне очень нравилось играть в неё: рассекать на PCJ-600, вновь и вновь повторять "миссию с вертолетиком", "летать" на Panzer. Сейчас я выступаю всего лишь в роли зрителя, наблюдая за скоростными прохождениями игры. В один из таких просмотров я задался вопросом: можно ли автоматизировать процесс прохождения и направить искусственный интеллект на игру для выполнения этой задачи? Или как запустить в кластере графическое приложение, которое использует ресурсы видеокарты? Поэтому в данной статье я подготовлю среду для обучения искусственному интеллекту.
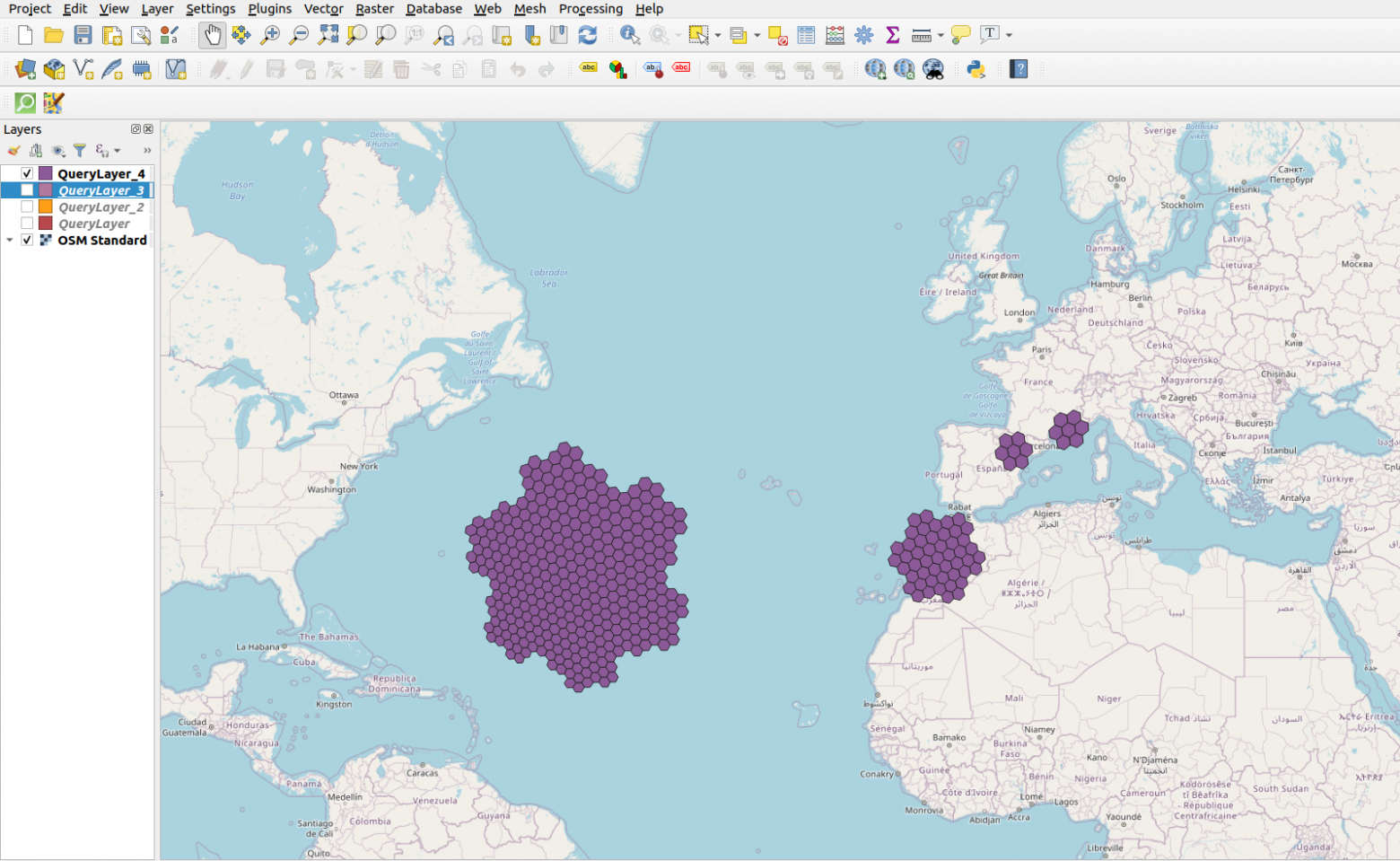
Когда человек раньше говорил что он контролирует весь мир, то его обычно помещали в соседнюю палату с Бонапартом Наполеоном. Надеюсь, что эти времена остались в прошлом и каждый желающий может анализировать геоданные всей земли и получать ответы на свои глобальные вопросы за минуты и секунды. Я опубликовал Openstreetmap_h3 — свой проект, который позволяет производить геоаналитику над данными из OpenStreetMap в PostGIS или в движке запросов, способном работать с Apache Arrow/Parquet.
Первым делом передаю привет хейтерам и скептикам. То что я разработал — действительно уникально и решает проблему преобразования и анализа геоданных используя обычные и привычные инструменты доступные каждому аналитику и датасаенс специалисту без бигдат, GPGPU, FPGA. То что выглядит сейчас простым в использовании и в коде — это мой личный проект в который я инвестировал свои отпуска, выходные, бессонные ночи и уйму личного времени за последние 3 года. Может быть я поделюсь и предысторией проекта и граблями по которым ходил, но сначала я все же опишу конечный результат.
Первый пост не претендует на монографию, начну с краткого обзора...

Диффузионные модели могут значительно расширить мир творческой работы и создания контента в целом. За последние несколько месяцев они уже доказали свою эффективность. Количество диффузионных моделей растет с каждым днем, а старые версии быстро устаревают

Unlock the power of Transformer Neural Networks and learn how to build your own GPT-like model from scratch. In this in-depth guide, we will delve into the theory and provide a step-by-step code implementation to help you create your own miniGPT model. The final code is only 400 lines and works on both CPUs as well as on the GPUs. If you want to jump straight to the implementation here is the GitHub repo.
Transformers are revolutionizing the world of artificial intelligence. This simple, but very powerful neural network architecture, introduced in 2017, has quickly become the go-to choice for natural language processing, generative AI, and more. With the help of transformers, we've seen the creation of cutting-edge AI products like BERT, GPT-x, DALL-E, and AlphaFold, which are changing the way we interact with language and solve complex problems like protein folding. And the exciting possibilities don't stop there - transformers are also making waves in the field of computer vision with the advent of Vision Transformers.
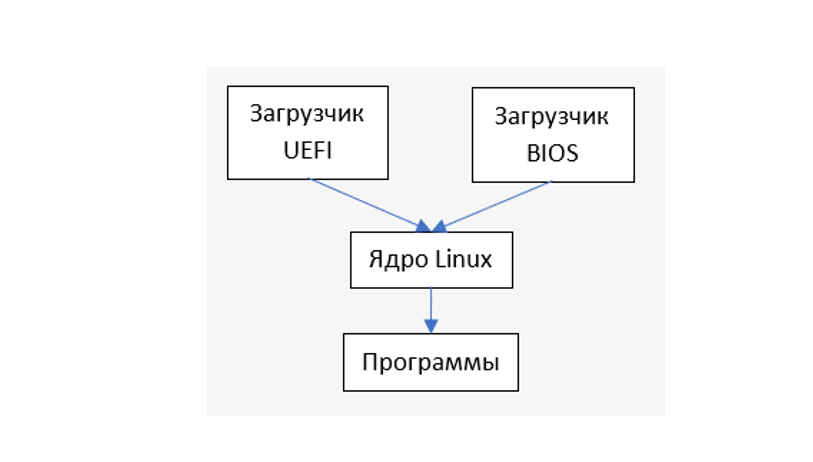
В статье описывается способ, как создать собственный загрузочный диск Linux (оптический диск или флешку), добавить в него только нужные программы и убрать все лишнее. Полученный образ в экспериментах занял менее 25 Мб. Он позволяет быстро загружаться, работать в текстовом режиме, создавать, редактировать, удалять файлы на разных файловых системах, имеет поддержку русского языка. За основу взят Debian.

Возможно, вы замечали, что Java-приложение может превышать лимит памяти, указанный в параметре -Xmx (максимальный размер кучи). Дело в том, что JVM помимо кучи использует и другие области памяти.
Давайте начнем со структуры памяти Java-приложения и источников потребления памяти.

Проект Docker, запущенный в 2013 году, стал одним из самых популярных инструментов в области контейнеризации. Спустя почти 10 лет Docker активно развивается, однако, не только сама компания Docker Inc привносит улучшения в свой продукт – обычные пользователи тоже вносят свой вклад, создавая различные инструменты, которые совершенствуют взаимодействие с системой Docker.
В статье мы рассмотрим топ-5 полезных утилит, которые упростят работу с Docker.

Всем привет. Меня зовут Добрый Кот Telegram.
В этой статье расскажем, как развернуть кластер чистыми бинарями и парочкой конфигов.
Вошли и вышли, приключение на 20 минут)
От коллектива FR-Solutions и при поддержке @irbgeo Telegram : Продолжаем серию статей о K8S.