
Все программы должны быть правильными, но некоторые программы должны быть быстрыми. Если программа обрабатывает видео-фреймы или сетевые пакеты в реальном времени, производительность является ключевым фактором. Недостаточно использовать эффективные алгоритмы и структуры данных. Нужно писать такой код, который компилятор легко оптимизирует и транслирует в быстрый исполняемый код.
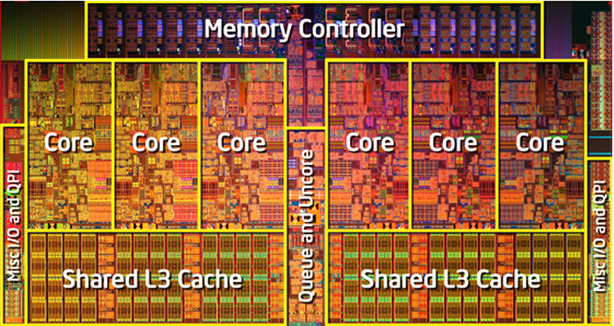
В этой статье мы рассмотрим базовые техники оптимизации кода, которые могут увеличить производительность вашей программы во много раз. Мы также коснёмся устройства процессора. Понимание как работает процессор необходимо для написания эффективных программ.
В этой статье мы рассмотрим базовые техники оптимизации кода, которые могут увеличить производительность вашей программы во много раз. Мы также коснёмся устройства процессора. Понимание как работает процессор необходимо для написания эффективных программ.

") ,
, )") — пересечение полуплоскостей,
— пересечение полуплоскостей, )") — алгоритм Форчуна) и некоторых тонкостях реализации (на языке C++).
— алгоритм Форчуна) и некоторых тонкостях реализации (на языке C++).
 Это последняя, на сегодняшний день, статья из цикла про внутреннее устройство конкурентных ассоциативных контейнеров. В предыдущих статьях рассматривались hash map, был построен алгоритм lock-free ordered list и контейнеры на его основе. За бортом остался один важный тип структур данных — деревья. Пришло время немного рассказать и о них.
Это последняя, на сегодняшний день, статья из цикла про внутреннее устройство конкурентных ассоциативных контейнеров. В предыдущих статьях рассматривались hash map, был построен алгоритм lock-free ordered list и контейнеры на его основе. За бортом остался один важный тип структур данных — деревья. Пришло время немного рассказать и о них.


 Пару месяцев назд Скотт Майерс (
Пару месяцев назд Скотт Майерс (
 Периодически, как правило во вторую среду месяца, можно услышать истории о том, что Windows после очередного обновления перестает загружаться, показывая синий экран смерти. В большинстве случаев причиной такой ситуации оказывается либо руткит, либо специфичное системное ПО, фривольно обращающееся со внутренними структурами ОС. Винят, конечно, все равно обновление, ведь «до него все работало». С таким отношением не удивительно, что «Майкрософт» не поощряет использование всего, что не документировано. В какой-то момент, а именно с релизом Windows Server 2003, MS заняла более активную позицию в вопросе борьбы с чудо-поделками сторонних разработчиков. Тогда появился механизм защиты целостности ядра — kernel patch protection, более известный как PatchGuard.
Периодически, как правило во вторую среду месяца, можно услышать истории о том, что Windows после очередного обновления перестает загружаться, показывая синий экран смерти. В большинстве случаев причиной такой ситуации оказывается либо руткит, либо специфичное системное ПО, фривольно обращающееся со внутренними структурами ОС. Винят, конечно, все равно обновление, ведь «до него все работало». С таким отношением не удивительно, что «Майкрософт» не поощряет использование всего, что не документировано. В какой-то момент, а именно с релизом Windows Server 2003, MS заняла более активную позицию в вопросе борьбы с чудо-поделками сторонних разработчиков. Тогда появился механизм защиты целостности ядра — kernel patch protection, более известный как PatchGuard. 
