
Что делать, если в базу хочется записать массу «фактов» много большего объема, чем она способна выдержать? Сначала, конечно, приводим данные к более экономичной нормальной форме и получаем «словари», в которые будем писать однократно. Но как это делать наиболее эффективно?
Именно с таким вопросом мы столкнулись при разработке мониторинга и анализа логов серверов PostgreSQL, когда остальные способы оптимизации записи в БД оказались исчерпаны.
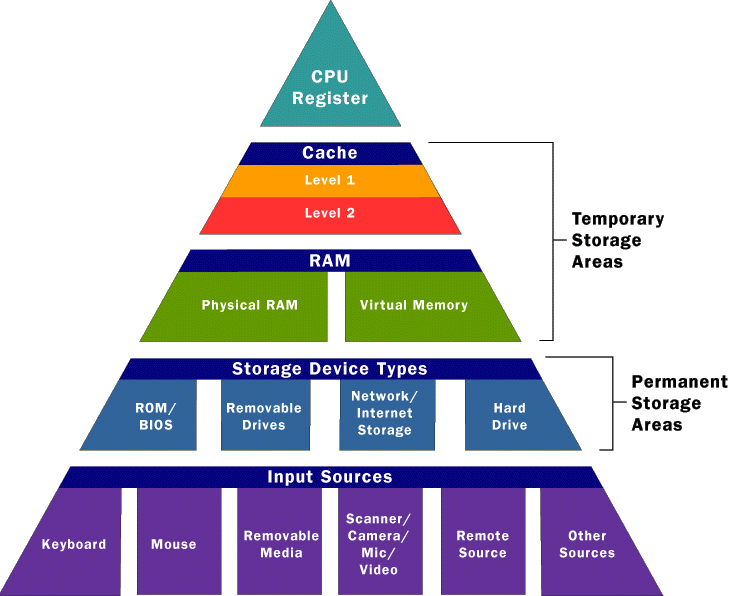
Сразу оговоримся, что наши коллекторы работают под управлением Node.js, поэтому с процессорными регистрами и кэшами мы никак не взаимодействуем. А вариант использования «стораджей» или внешних кэширующих сервисов/БД дает слишком большие задержки при входящих потоках в несколько сотен Mbps.
Поэтому мы стараемся кэшировать все в RAM, конкретно — в памяти JavaScript-процесса. Про то, как эффективнее это организовать, и пойдет речь дальше.
Именно с таким вопросом мы столкнулись при разработке мониторинга и анализа логов серверов PostgreSQL, когда остальные способы оптимизации записи в БД оказались исчерпаны.
Сразу оговоримся, что наши коллекторы работают под управлением Node.js, поэтому с процессорными регистрами и кэшами мы никак не взаимодействуем. А вариант использования «стораджей» или внешних кэширующих сервисов/БД дает слишком большие задержки при входящих потоках в несколько сотен Mbps.
Поэтому мы стараемся кэшировать все в RAM, конкретно — в памяти JavaScript-процесса. Про то, как эффективнее это организовать, и пойдет речь дальше.