Это гостевая публикация от Пэдди Байерса (Paddy Byers), сооснователя и технического директора Ably — платформы для стриминга данных в реальном времени. Оригинал статьи опубликован в блоге Ably.
Люди хотят быть уверены в надежности используемого сервиса. Однако в реальности отдельные компоненты неизбежно отказывают, и у нас должна быть возможность продолжать работу, несмотря на это.
В этой статье мы подробно рассмотрим концепции надежности и отказоустойчивости, которые стали определяющими при разработке платформы Ably.
Для начала дадим несколько определений:
Надежность — cтепень того, насколько пользователи могут положиться на продукт или сервис для решения своих задач. Доступность и устойчивость являются видами надежности.
Доступность — степень готовности продукта или сервиса к эксплуатации по требованию. Это понятие часто сcодят к обеспечению необходимого излишка ресурсов с учетом статистически независимых отказов.
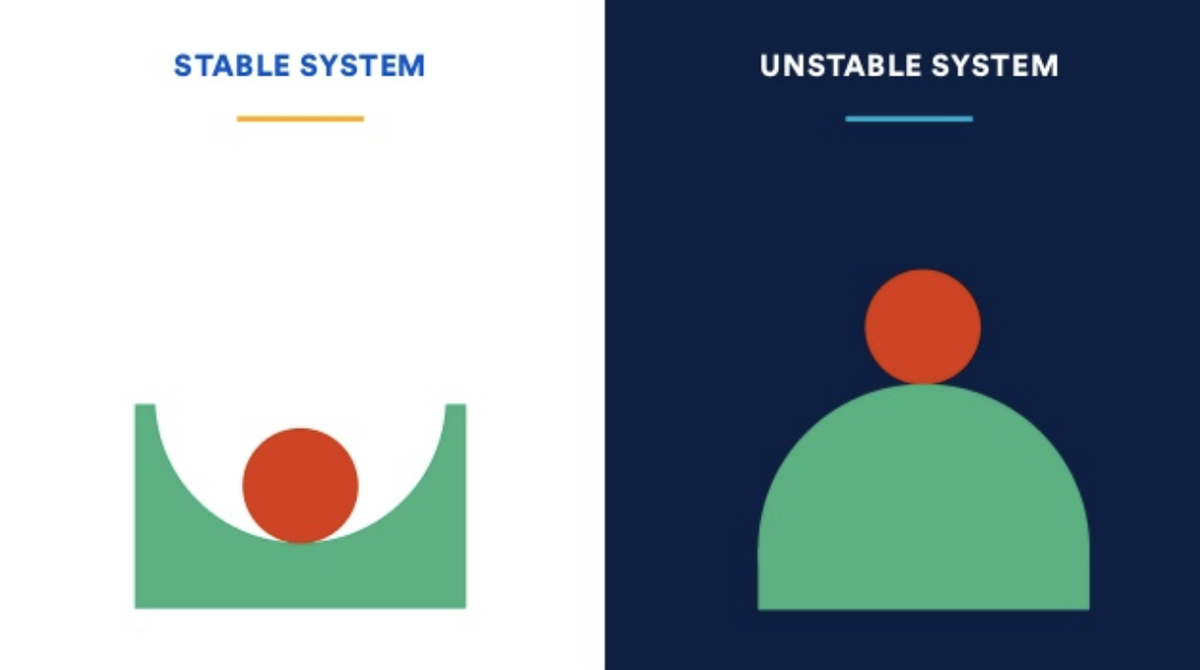
Устойчивость — cпособность продукта или сервиса соответствовать заявленным характеристикам в процессе использования. Это значит, что система не просто готова к эксплуатации: благодаря дополнительным мощностям, предусмотренным в ходе проектирования, она может продолжать работать под нагрузкой, как и ожидают пользователи.
Отказоустойчивость — способность системы сохранять надежность (доступность и устойчивость) при отказе отдельных компонентов или сбоях в подсистемах.
Отказоустойчивые системы спроектированы таким образом, чтобы смягчать воздействие неблагоприятных факторов и оставаться надежными для конечного пользователя. Методы обеспечения отказоустойчивости могут использоваться для улучшения доступности и устойчивости.