 Ранее мы, Smart Engines, уже писали про наши технологии распознавания (паспорта РФ, банковских карт и многих других). Основной ценностью SDK является "ядро" или "движок" распознавания Smart IDReader, который объединяет функциональность сканирования всего, что мы умеем сканировать, под единым интерфейсом.
Ранее мы, Smart Engines, уже писали про наши технологии распознавания (паспорта РФ, банковских карт и многих других). Основной ценностью SDK является "ядро" или "движок" распознавания Smart IDReader, который объединяет функциональность сканирования всего, что мы умеем сканировать, под единым интерфейсом.
Библиотека распознавания написана на С++ для достижения максимальной производительности, но для использования с различными языками программирования у нас есть версии интерфейсов библиотеки на C++, C, C#, Objective-C, Java и даже Visual Basic. Мы поддерживаем все популярные операционные системы: iOS, Android, Windows, Linux, MacOS, Solaris и, разумеется, Эльбрус и AstraLinux. Наши алгоритмы оптимизированы под такие архитектуры, как ARMv7-v8, AArch64, x86, x86_64, SPARC, E2K.
Мы решили выложить демо-версию нашего SDK на Github, чтобы вы могли ознакомиться с интерфейсом библиотеки (как Objective-C часть, так и C++), почитать документацию и попробовать встроить Smart IDReader в ваше приложение. Репозиторий с демо-версией Smart IDReader iOS SDK доступен по ссылке: https://github.com/SmartEngines/SmartIDReader-iOS-SDK
Чтобы посмотреть, как Smart IDReader выглядит в нашем исполнении после встраивания, вы можете скачать бесплатные полные версии приложений из App Store и Google Play.
В этой статье мы расскажем, как iOS разработчик может использовать наши технологии для добавления функциональности распознавания документов в своё приложение.




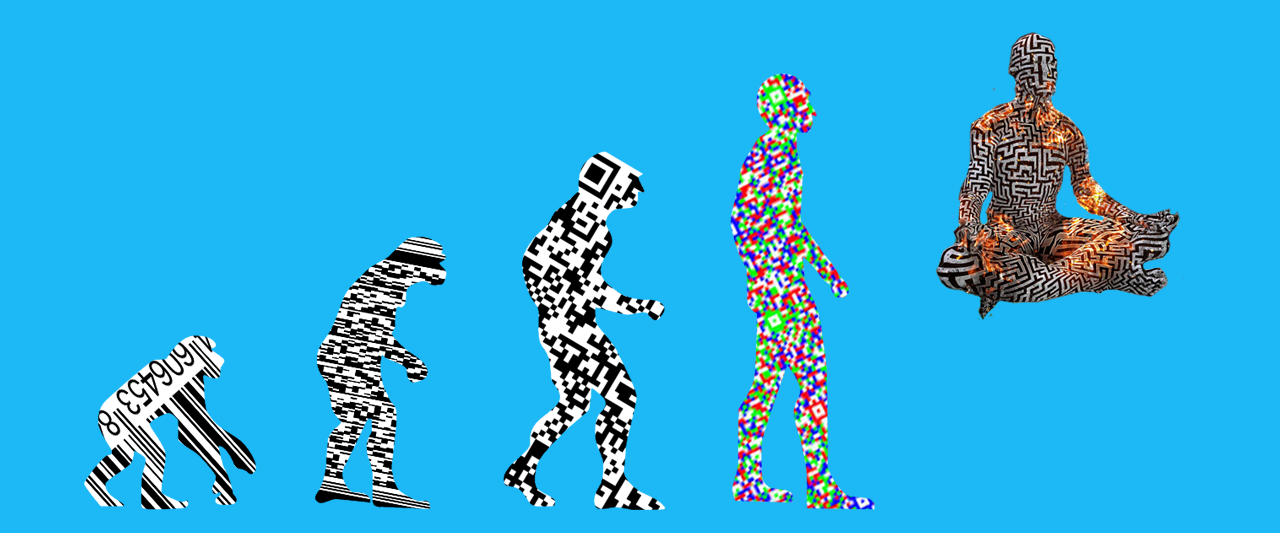

 На Хабре уже неоднократно затрагивалась тема применения так называемых “бандитов” для интеллектуального анализа данных. В отличии от уже привычного обучения машин по прецедентам, которое сплошь и рядом применяется в задачах распознавания, многорукий бандит применяется для построения в некотором смысле “рекомендательных” систем. На Хабре уже очень подробно и доступно рассказано о идее многорукого бандита и применимости ее к задаче рекомендации интернет-контента. Мы же в своем очередном посте хотели рассказать вам о симбиозе обучения по прецедентам и обучения с подкреплением в задачах распознавания видеопотока.
На Хабре уже неоднократно затрагивалась тема применения так называемых “бандитов” для интеллектуального анализа данных. В отличии от уже привычного обучения машин по прецедентам, которое сплошь и рядом применяется в задачах распознавания, многорукий бандит применяется для построения в некотором смысле “рекомендательных” систем. На Хабре уже очень подробно и доступно рассказано о идее многорукого бандита и применимости ее к задаче рекомендации интернет-контента. Мы же в своем очередном посте хотели рассказать вам о симбиозе обучения по прецедентам и обучения с подкреплением в задачах распознавания видеопотока.














 ===>
===>  ===>
===> 