
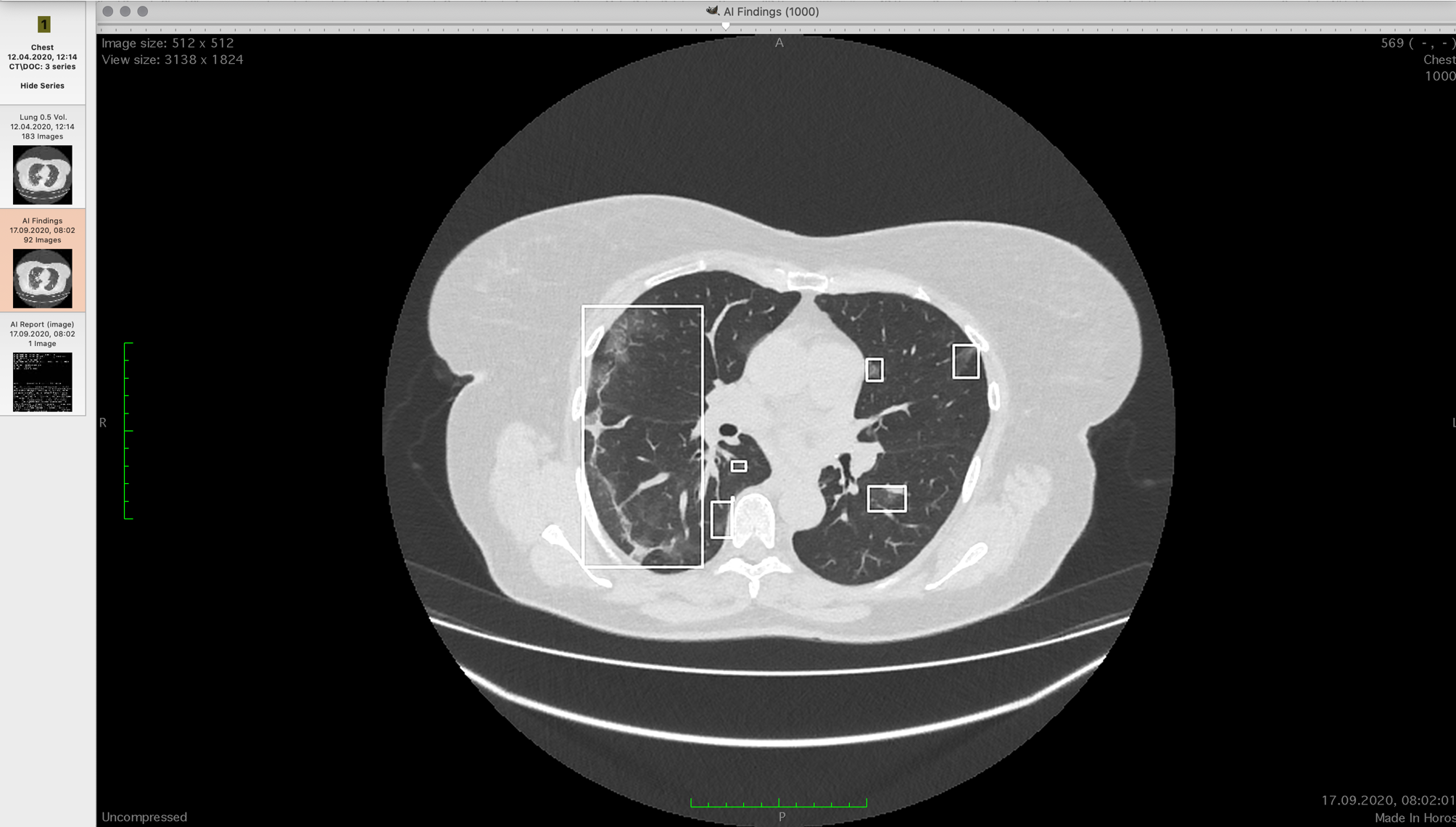
Срез КТ с зонами «матового стекла»
Пациентам с подтверждённым COVID-19 делают компьютерную томографию лёгких. Если повезёт — один раз, если нет — несколько. В первый раз нужно оценить уровень поражения в процентах. В зависимости от квартиля степени поражения определяется дальнейшая схема лечения, и они разительно отличаются. В апреле 2020 мы узнали, что есть две сложности:
- КТ — трёхмерное изображение, каждый слой такого изображения называется срезом. При 300–800 срезах лёгких на КТ врачи тратят от 1 до 15 минут на поиск характерных зон, чтобы определить степень поражения. Одна минута — это «на глаз», 30 минут — это среднее при ручном выделении и подсчёте зон повреждённой ткани. В сложных случаях результат может обрабатываться до часа.
- Точность диагностики уровня поражения коронавирусом экспертами «на глаз» высока на границах 0–30 % и 70–100 %. В диапазоне 30–70 погрешность очень высока, и мы обратили внимание, что кто-то из рентгенологов, как правило, системно завышает процент поражения на глаз, а кто-то занижает.
Задача сводится к определению повреждённой ткани лёгких и подсчёту доли их объёма к общему лёгких.
В конце апреля в кооперации с клиниками мы подготовили датасет обезличенных исследований пациентов с подтверждённым ПЦР-анализом COVID-19, отдали комиссии из десяти отличных экспертов-рентгенологов и разметили выборку для обучения с учителем.






 При работе с большими объемами данных иногда может остро встать проблема нехватки места на дисках. Одним из способов решения данной проблемы является сжатие, благодаря которому, на том же оборудовании, можно себе позволить увеличить объемы хранения. В данной статье мы рассмотрим, как работает сжатие данных в Apache Ignite. В статье будут описаны только реализованные внутри продукта способы сжатия на диске. Другие способы сжатия данных (по сети, в памяти) как реализованные, так и нет останутся за рамками.
При работе с большими объемами данных иногда может остро встать проблема нехватки места на дисках. Одним из способов решения данной проблемы является сжатие, благодаря которому, на том же оборудовании, можно себе позволить увеличить объемы хранения. В данной статье мы рассмотрим, как работает сжатие данных в Apache Ignite. В статье будут описаны только реализованные внутри продукта способы сжатия на диске. Другие способы сжатия данных (по сети, в памяти) как реализованные, так и нет останутся за рамками.





{kind=link}