Разработчик Вася не смог включиться в работу утром. Потом еще был эмоциональный митинг с заказчиком, после которого снова активировалась прокрастинация. В итоге вместо восьми запланированных часов работы — три. Вася понимает, что дома придется доделывать рабочие задачи, и потому он снова забьет на свое (постоянно откладываемое) обучение.
Тут появляются авторы статьи, которую вы читаете, и предлагают попробовать пару интересных штук для эффективного включения. Мы пробуем замедлиться в два раза и еще пощелкать с десяток примеров устного счета. После митинга – вынести всю рефлексию на бумагу и «шлифануть» это активной прогулкой. Простые решения, которые в совокупности позволяют не терять время на «тупняк в монитор».
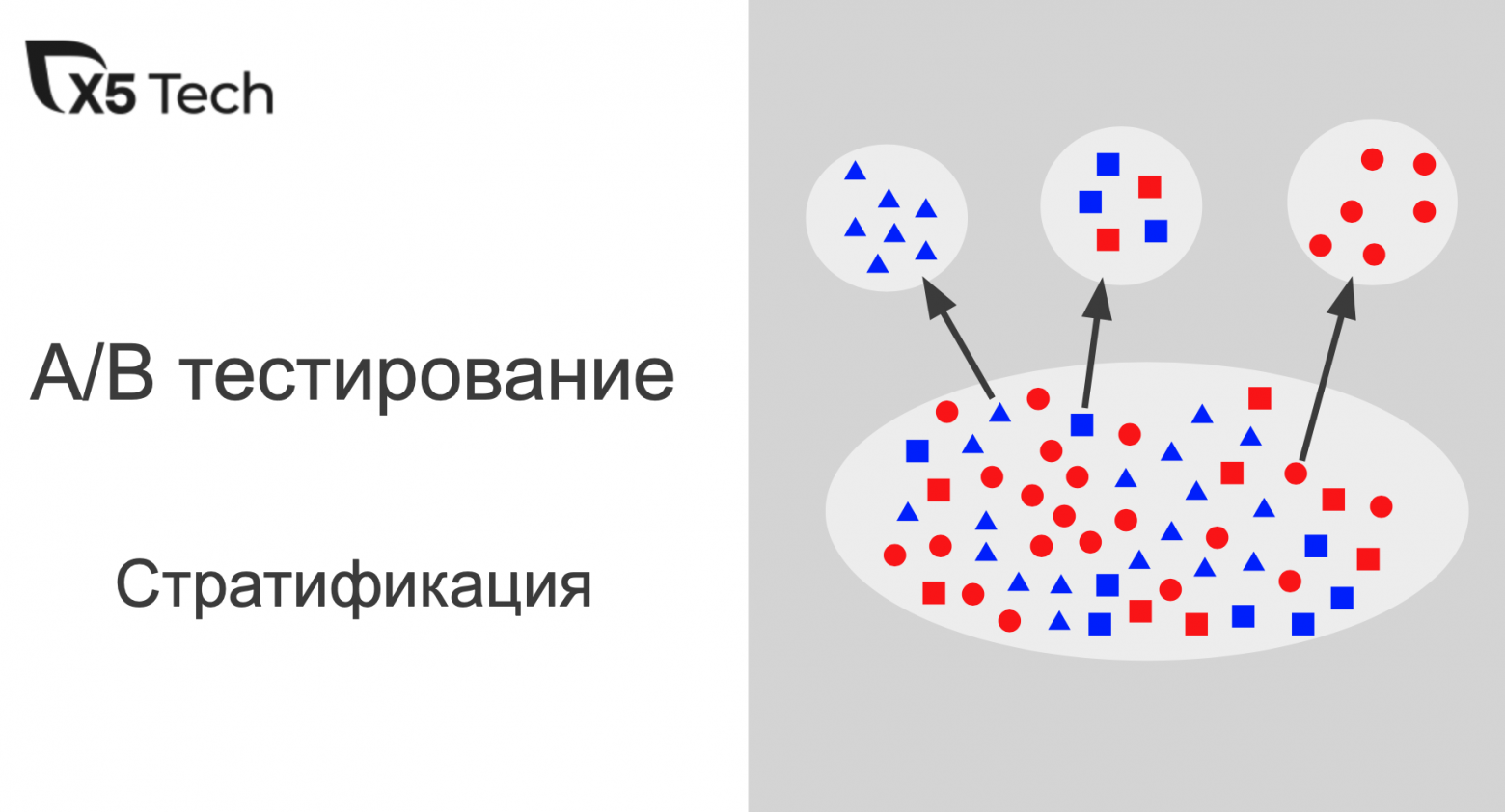
Как мы подобрали эти решения и почему именно они? В целом, подобных приемов есть около четырех десятков, а конкретных техник – и того больше. Чтобы выйти на конкретные действия, которые нужны именно вам, мы создали простой инструмент, описанный далее в статье.