
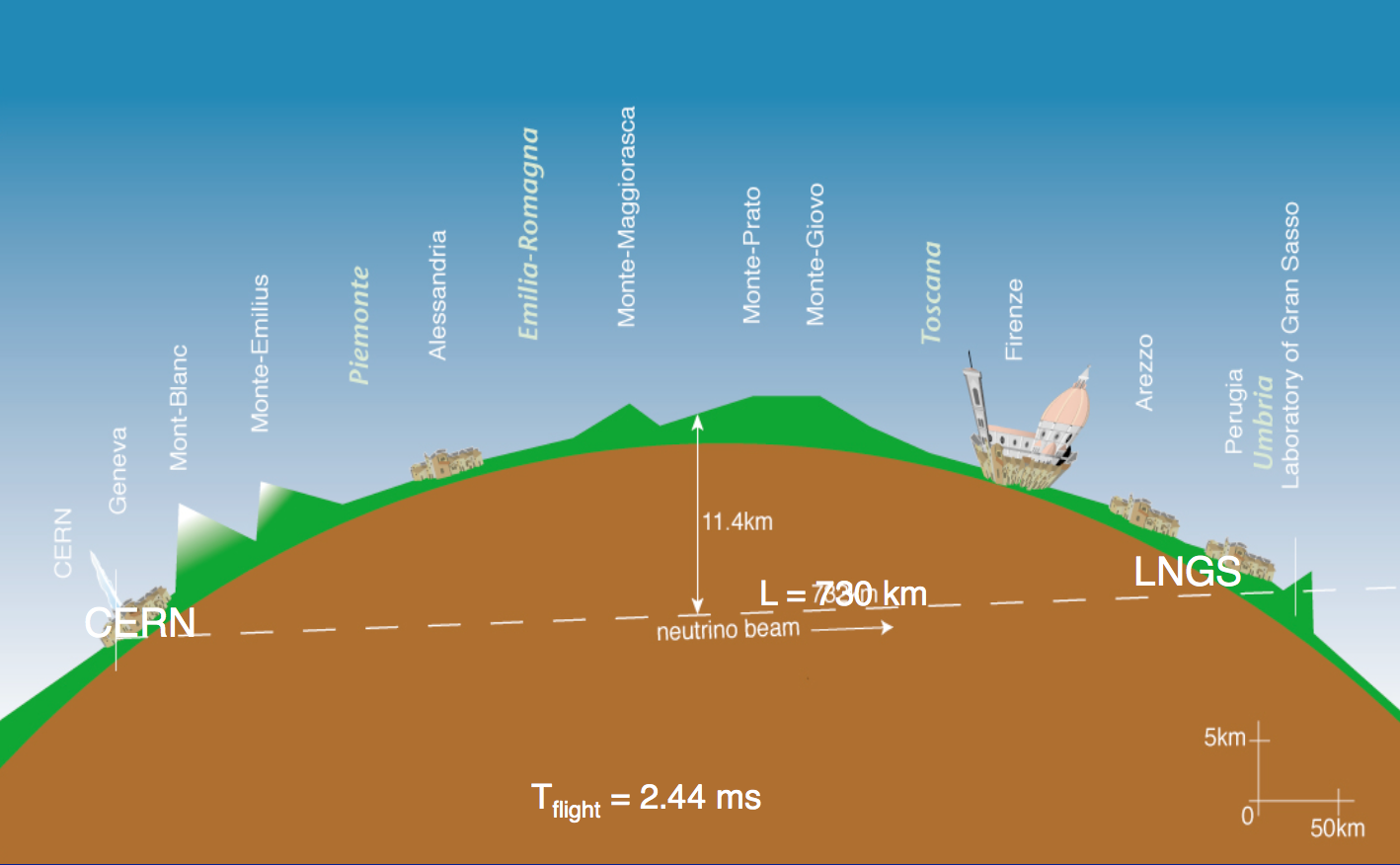
Ровно 20 лет назад — 23 сентября 1997 года — в интернете появился Яндекс. Аркадий Волож, Илья Сегалович, Елена Колмановская представили на выставке Softool поисковую систему Yandex.ru. Открывали её, перерезав ленточку перед компьютером — потому что не понимали, как надо открывать сайты в интернете.
Тогда он состоял из 5 тысяч сайтов, на которых было размещено около 4 гигабайт текста. Люди подходили к демонстрационному компьютеру, пробовали задавать запросы и получали ответы. На тот момент Яндекс учитывал морфологию русского языка, расстояние между словами и умел ранжировать документы.
Это одна из последних лекций, которую прочитал iseg, сооснователь и первый технический директор Яндекса Илья Сегалович. Она посвящена истории Яндекса с того момента, как Илья и Аркадий Волож сели в школе за одну парту. Качество записи лекции не настолько хорошее, насколько бы нам хотелось, но содержание — бесценно.
Тогда он состоял из 5 тысяч сайтов, на которых было размещено около 4 гигабайт текста. Люди подходили к демонстрационному компьютеру, пробовали задавать запросы и получали ответы. На тот момент Яндекс учитывал морфологию русского языка, расстояние между словами и умел ранжировать документы.
Это одна из последних лекций, которую прочитал iseg, сооснователь и первый технический директор Яндекса Илья Сегалович. Она посвящена истории Яндекса с того момента, как Илья и Аркадий Волож сели в школе за одну парту. Качество записи лекции не настолько хорошее, насколько бы нам хотелось, но содержание — бесценно.







{kind=link}