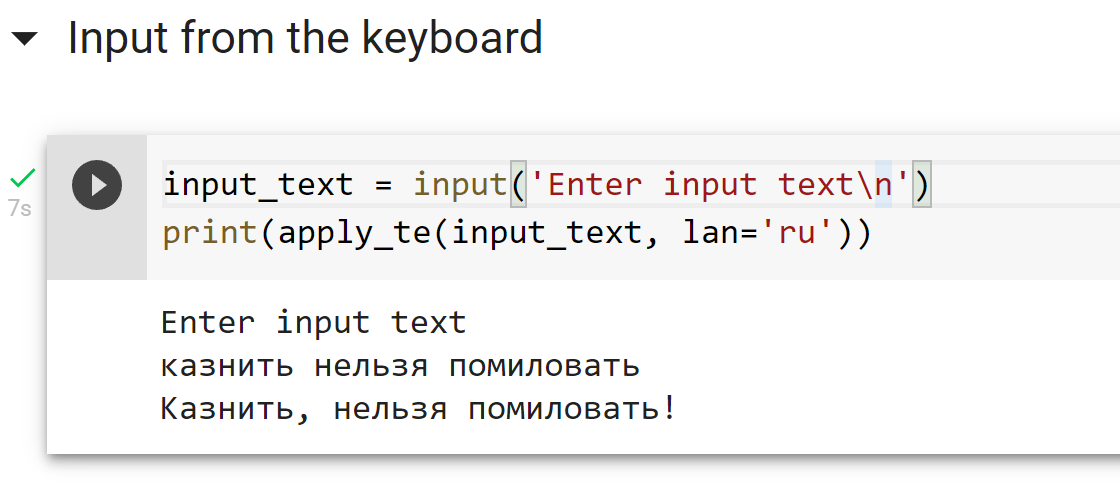
После запуска моделей на прод рано или поздно приходит понимание того, что Ваши сервисы популярны и что KPI растут. Вместе с популярностью приходят тормоза и нестабильность. В этой статье речь пойдет о прикладном аспекте оптимизации быстродействия алгоритмов/моделей на примере движка распознавания автомобильных номеров “Nomeroff Net”. Буду делиться опытом, полученным на протяжении 2-х летней разработки. Если коротко: нам удалось ускорить время распознавания 1 фото более чем в 10 раз.
“Чел догадался в свой сервер вставить RTX 3090” подумаете Вы… Приблизительно так и было, только если взять замеры до установки GPU то все ускорили в 100+ раз :).
Не будет детального описания архитектуры моделей (они давно известны в узких кругах), хочу поделиться важными моментами, на которые стоит обратить внимание при оптимизации ваших ML-сервисов.