… Кроме типовых для журнала статей, там была статья за авторством некоего «DI HALT» про то, как из двух телефонов и микроконтроллера извлечь кучу лулзов. «Прикольный ник» — подумал мальчик Андрей и перелистнул страницу, ибо ниасилил. А за ней была статья того же автора про то, как скрестить флешку с мышкой. «А вот это нам под силу» — подумал мальчик и убил уже знакомую вам флешку банальной переполюсовкой. Но зато он понял, что электроника — это весело и почти безопасно. — с просторов
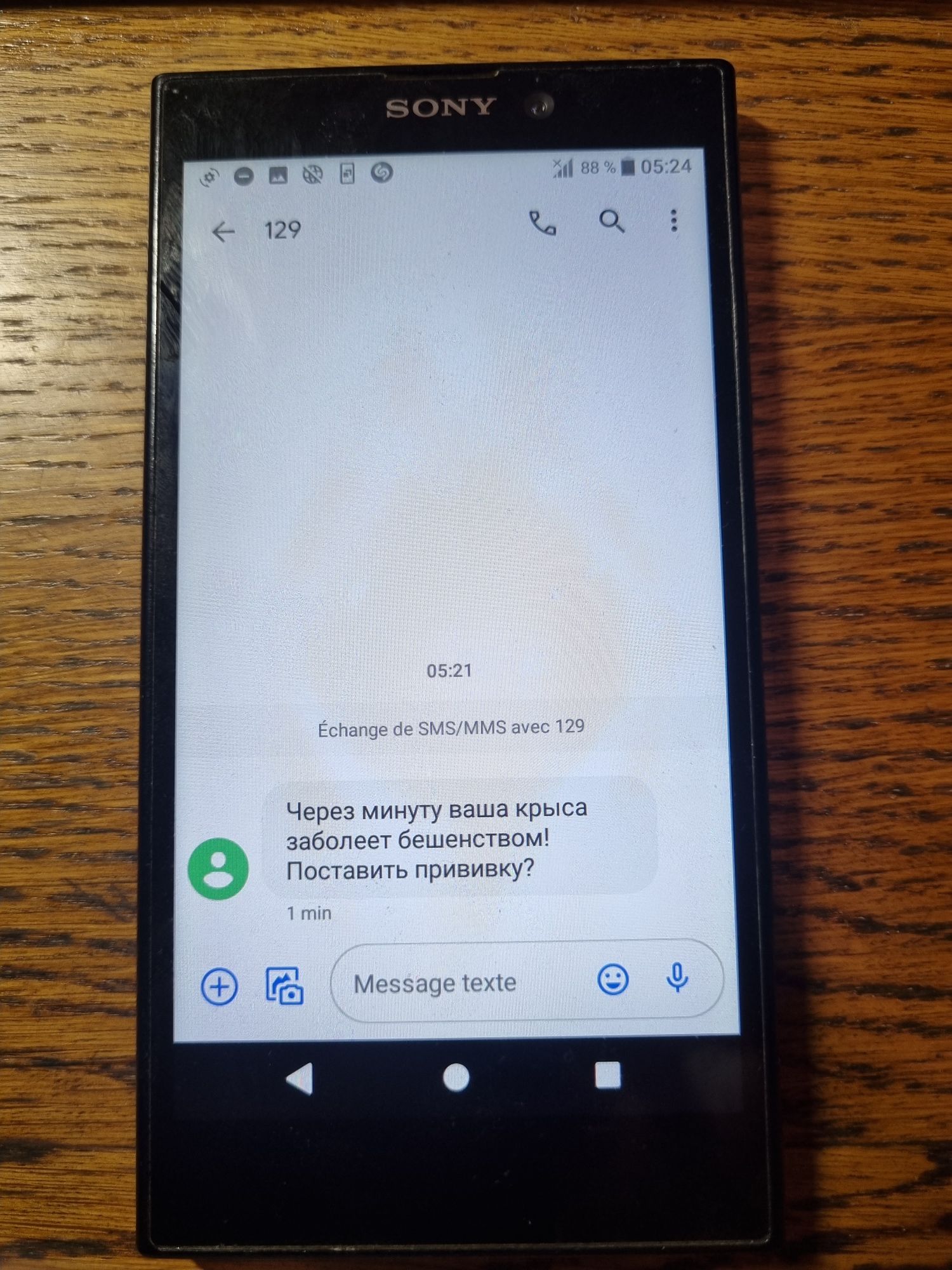
Приветствую всех!
Многие из вас наверняка слышали про OsmocomBB. Однако каких-то исчерпывающих мануалов по запуску почему-то крайне мало. Итак, в ходе данной статьи постараемся максимально простым образом запустить собственную базовую станцию из доступных комплектующих. Постараемся разобраться, как сделать так, чтобы оно точно заработало.
Приветствую всех!
Многие из вас наверняка слышали про OsmocomBB. Однако каких-то исчерпывающих мануалов по запуску почему-то крайне мало. Итак, в ходе данной статьи постараемся максимально простым образом запустить собственную базовую станцию из доступных комплектующих. Постараемся разобраться, как сделать так, чтобы оно точно заработало.