Проскакивала когда-то статья: Отключённый промышленный твердотельник может потерять данные за неделю. В ней было некое количество контринтуитивных, но, вроде, логичных, утверждений: например, ситуация "хранить диск придётся при повышенной температуре — так хоть при записи пожалею, охлажу" на самом деле самая неблагоприятная. Так что стёбом здесь выглядит разве что термин "заряжать флешку". Хотя выше уже закономерно интересуются, будет ли это всё отрабатывать, если подать только питание.
Кстати, можно щёлкнуть по бейджику — должен появиться список репозиториев (возможно, с пометкой "and more"). Если ваш ник на GitHub такой же, как на Хабре, то в вашем случае как раз был contribution в чужой проект, попавший в архив.
Есть такая забавная библиотека GNU Pth. У неё примерно такой же API, как у Pthreads, но вместо полноценных потоков она использует корутины и щепотку костылей. Возможно, получится предсказуемее и более "fork-friendly".
А, и ещё: у MemTest есть немало параметров командной строки, в частности, один из них позволяет задать список тестов, поскольку сделать это при включённом btrace вы вряд ли сможете. Ссылку вновь даю на свой форк, просто потому, что не знаю, где выложена референсная версия в распакованном виде.
Оказывается, btrace постоянно требует нажать клавишу, чтобы продолжить, я же был уверен, что у меня ввод по serial-порту принципиально не работал — оказывается, он у меня "принципиально работал", причём независимо от того, есть ли реальный ввод… В общем, btrace может быть не совсем удобен для отладки "отдалённой" ошибки.
А оригинальный MemTest у меня вообще не собрался — жалуется на тучу отсутствующих символов. По поводу зависаний — я попробовал запустить в QEMU, и он тоже иногда подвисает изрядно (а иногда — намертво).
Зато я понял, что не компилирующийся с аналогичными ошибками мой порт с ARCH=i386 — это не я сломал, а "оно само". Более того, в итоге у меня есть буквально штук пять дебиановских патчей, один из которых всё чинит, и нужно просто понять, как. Так что спасибо за вопрос! :)
На счёт изначальной просьбы: честно скажу, перспектива "удалённой" отладки SMP-кода с соответствующим чтением хитрых спецификаций на x86 меня несколько пугает. :) У меня у самого, как ни решу проверить память, SMP-режим вечно вис, и я его не использовал. Я бы вам посоветовал во-первых, убедиться, что поведение обеих версий воспроизводимо (в том смысле, что различия в поведении — это не просто "шум"). Во-вторых, было бы логично как-нибудь запихнуть в параметры запуска MemTest опцию "btrace". У меня в GRUB 2 это выглядит как "linux16 /boot/memtest86+.bin btrace", а потом "boot".
Уточните, пожалуйста, откуда взят оригинал: с memtest.org, из дистрибутива или откуда-то ещё. Просто логично было бы накладывать этот патч именно поверх имеющихся в работающей версии.
Более того, у U-Boot, вроде бы, тоже имеется встроенная команда вроде memtest или что-то такое (прямо в загрузчике). Но попробовать всё-таки было интересно. Ну и MemTest, по слухам, и правда "умный", хотя видел упоминания из серии "MemTest нагружает память не так сильно, как хотелось бы (ссылка на статью с более продвинутым алгоритмом), но вот test номер N очень близок" (кстати, возможно именно этот тест был полностью на ассемблере, и я его пока так же полностью и закомментировал). Впрочем, MemTest можно было бы использовать как удобную стандартную оболочку для запуска "вот этого всего" из теоретических статей.
Вроде, она и есть. Могу посмотреть в списке заказов точную ссылку, но, если ничего не напутал в первой статье, то ссылка такая: https://ru.aliexpress.com/item/1892377255.html(надеюсь, это не считается рекламой)
Кстати, пока ковырялся в коде, наткнулся на такие строчки (ссылку даю на свой "форк", потому что сам исходники качал с официального сайта вообще в архиве):
/* Now setup the test parameters based on the current test number */
if (v->pass == 0) {
/* Reduce iterations for first pass */
c_iter = tseq[test].iter/FIRST_DIVISER;
} else {
c_iter = tseq[test].iter;
}
«Продвинутые пользователи мемтеста» об этом, наверное, и так прекрасно знали, а вот я лишь догадывался (что-то он как-то быстро, а потом как-то не очень).
Я подозреваю, что даже для JJTree можно такие сериализаторы генерировать как-нибудь, если допилить генератор парсеров. Хотя, в общем случае — не факт, не удивлюсь, если про это даже какая-нибудь теорема есть. :)
Здесь же идея была в том, чтобы взять готовые модули (в особенности, свеженаписанный модуль для Modelica) и разом получить инструмент для всех этих языков (даже для неопубликованных реализаций). В целом, две существующих стратегии запросто обобщаются на произвольное описание ANTLR / JJTree / чего-угодно — хоть Kaitai Struct. Хотя результат, да, может получиться менее удачный, чем если использовать "конструктивный" подход.
Этого я точно не видел, поэтому спасибо за совет! Конечно, нужно посмотреть, как аналогичные задачи решались существующими инструментами. Просто удивило, что даже совсем примитивная стратегия тоже на что-то способна.
Насчёт добавления — тут есть нюанс, изначально не указанный в статье, который я сейчас дописал: у меня нет сериализаторов, превращающих AST в текст. Зато существующие языковые модули проставляют начало и конец узла в исходном тексте, поэтому можно взять оригинальный файл и "выкинуть лишнее" — отсюда изначальный посыл с итеративным выкидыванием лишнего. Это не ответ "нет" на ваш комментарий — просто обоснование, почему изначальное решение было таким.
Может это потому, что AFL смотрит что внутри экзешника что-то стриггерилось (у него там мапа специальная есть) и начинает эти места лучше проверять, делает ли так-же libFuzzer я не вкурсе.
Насколько я понимаю, там ещё отдельное искусство выбора того, какие мутации более перспективные — см., например, afl-rb и сравнение с другими подходами. Также можно посмотреть в документации на тему используемого в AFL подхода и мотивации выбрать именно такой.
UPD: ltrace, может, и не "устарел", но с ходу я не нашёл активности за последние 4 года в официальном репозитории. Впрочем, в таком же состоянии долго пребывал bzip2, а потом, вроде, кто-то принял "эстафету поддержки".
У меня есть смутное ощущение, что, в отличие от вовсю обновляющегося strace, трассировщик ltrace малость устарел. И тут начинаешь думать: "Это же должно делаться в кооперации с ld-linux.so, иначе можно наткнуться на внезапное расхождение". И тут, внезапно, натыкаешься на sotruss, который по крайней мере на моей системе реально идёт в пакете libc-dev-bin.

Проскакивала когда-то статья: Отключённый промышленный твердотельник может потерять данные за неделю. В ней было некое количество контринтуитивных, но, вроде, логичных, утверждений: например, ситуация "хранить диск придётся при повышенной температуре — так хоть при записи пожалею, охлажу" на самом деле самая неблагоприятная. Так что стёбом здесь выглядит разве что термин "заряжать флешку". Хотя выше уже закономерно интересуются, будет ли это всё отрабатывать, если подать только питание.
Кстати, можно щёлкнуть по бейджику — должен появиться список репозиториев (возможно, с пометкой "and more"). Если ваш ник на GitHub такой же, как на Хабре, то в вашем случае как раз был contribution в чужой проект, попавший в архив.
Критерии указаны в https://archiveprogram.github.com в разделе "What’s in the 02/02/2020 snapshot".
Если что, статья в итоге была опубликована, хотя и без тестирования на Windows.
Есть такая забавная библиотека GNU Pth. У неё примерно такой же API, как у Pthreads, но вместо полноценных потоков она использует корутины
и щепотку костылей. Возможно, получится предсказуемее и более "fork-friendly".А, и ещё: у MemTest есть немало параметров командной строки, в частности, один из них позволяет задать список тестов, поскольку сделать это при включённом
btraceвы вряд ли сможете. Ссылку вновь даю на свой форк, просто потому, что не знаю, где выложена референсная версия в распакованном виде.Оказывается,
btraceпостоянно требует нажать клавишу, чтобы продолжить, я же был уверен, что у меня ввод по serial-порту принципиально не работал — оказывается, он у меня "принципиально работал", причём независимо от того, есть ли реальный ввод… В общем,btraceможет быть не совсем удобен для отладки "отдалённой" ошибки.А оригинальный MemTest у меня вообще не собрался — жалуется на тучу отсутствующих символов. По поводу зависаний — я попробовал запустить в QEMU, и он тоже иногда подвисает изрядно (а иногда — намертво).
Зато я понял, что не компилирующийся с аналогичными ошибками мой порт с
ARCH=i386— это не я сломал, а "оно само". Более того, в итоге у меня есть буквально штук пять дебиановских патчей, один из которых всё чинит, и нужно просто понять, как. Так что спасибо за вопрос! :)На счёт изначальной просьбы: честно скажу, перспектива "удалённой" отладки SMP-кода с соответствующим чтением хитрых спецификаций на x86 меня несколько пугает. :) У меня у самого, как ни решу проверить память, SMP-режим вечно вис, и я его не использовал. Я бы вам посоветовал во-первых, убедиться, что поведение обеих версий воспроизводимо (в том смысле, что различия в поведении — это не просто "шум"). Во-вторых, было бы логично как-нибудь запихнуть в параметры запуска MemTest опцию "btrace". У меня в GRUB 2 это выглядит как "linux16 /boot/memtest86+.bin btrace", а потом "boot".
Уточните, пожалуйста, откуда взят оригинал: с memtest.org, из дистрибутива или откуда-то ещё. Просто логично было бы накладывать этот патч именно поверх имеющихся в работающей версии.
Собрать-то собрал: https://gist.github.com/atrosinenko/f61a4865f35e4702ae3a1f8a49aee71e
Вот с проверкой работоспособности — сложнее. Если что, собирал вот так:
То есть, этот MemTest включает в себя патчи из текущей Ubuntu.
Более того, у U-Boot, вроде бы, тоже имеется встроенная команда вроде
memtestили что-то такое (прямо в загрузчике). Но попробовать всё-таки было интересно. Ну и MemTest, по слухам, и правда "умный", хотя видел упоминания из серии "MemTest нагружает память не так сильно, как хотелось бы (ссылка на статью с более продвинутым алгоритмом), но вот test номер N очень близок" (кстати, возможно именно этот тест был полностью на ассемблере, и я его пока так же полностью и закомментировал). Впрочем, MemTest можно было бы использовать как удобную стандартную оболочку для запуска "вот этого всего" из теоретических статей.Вроде, она и есть. Могу посмотреть в списке заказов точную ссылку, но, если ничего не напутал в первой статье, то ссылка такая: https://ru.aliexpress.com/item/1892377255.html (надеюсь, это не считается рекламой)
Кстати, пока ковырялся в коде, наткнулся на такие строчки (ссылку даю на свой "форк", потому что сам исходники качал с официального сайта вообще в архиве):
«Продвинутые пользователи мемтеста» об этом, наверное, и так прекрасно знали, а вот я лишь догадывался (что-то он как-то быстро, а потом как-то не очень).
Собственно, у меня тоже была отчасти похожая ситуация. Что-то вроде «в каждом четырёхбайтном (или восьмибайтном?) слове обнулилось по маске 0x0000ff00». Хотя, конечно, и близко не столь коварная, как в приведённой истории.
Интересный эффект:
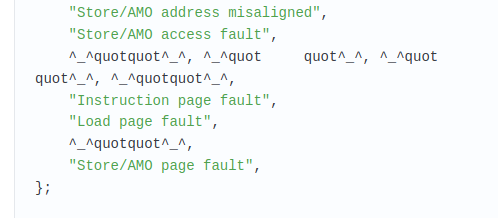
Это парсер глючит или я чего-то недопонял?
Я подозреваю, что даже для JJTree можно такие сериализаторы генерировать как-нибудь, если допилить генератор парсеров. Хотя, в общем случае — не факт, не удивлюсь, если про это даже какая-нибудь теорема есть. :)
Здесь же идея была в том, чтобы взять готовые модули (в особенности, свеженаписанный модуль для Modelica) и разом получить инструмент для всех этих языков (даже для неопубликованных реализаций). В целом, две существующих стратегии запросто обобщаются на произвольное описание ANTLR / JJTree / чего-угодно — хоть Kaitai Struct. Хотя результат, да, может получиться менее удачный, чем если использовать "конструктивный" подход.
Этого я точно не видел, поэтому спасибо за совет! Конечно, нужно посмотреть, как аналогичные задачи решались существующими инструментами. Просто удивило, что даже совсем примитивная стратегия тоже на что-то способна.
Насчёт добавления — тут есть нюанс, изначально не указанный в статье, который я сейчас дописал: у меня нет сериализаторов, превращающих AST в текст. Зато существующие языковые модули проставляют начало и конец узла в исходном тексте, поэтому можно взять оригинальный файл и "выкинуть лишнее" — отсюда изначальный посыл с итеративным выкидыванием лишнего. Это не ответ "нет" на ваш комментарий — просто обоснование, почему изначальное решение было таким.
Насколько я понимаю, там ещё отдельное искусство выбора того, какие мутации более перспективные — см., например, afl-rb и сравнение с другими подходами. Также можно посмотреть в документации на тему используемого в AFL подхода и мотивации выбрать именно такой.
UPD: ltrace, может, и не "устарел", но с ходу я не нашёл активности за последние 4 года в официальном репозитории. Впрочем, в таком же состоянии долго пребывал bzip2, а потом, вроде, кто-то принял "эстафету поддержки".
У меня есть смутное ощущение, что, в отличие от вовсю обновляющегося
strace, трассировщикltraceмалость устарел. И тут начинаешь думать: "Это же должно делаться в кооперации с ld-linux.so, иначе можно наткнуться на внезапное расхождение". И тут, внезапно, натыкаешься наsotruss, который по крайней мере на моей системе реально идёт в пакетеlibc-dev-bin.