Всем привет, меня зовут Максим Гусев!
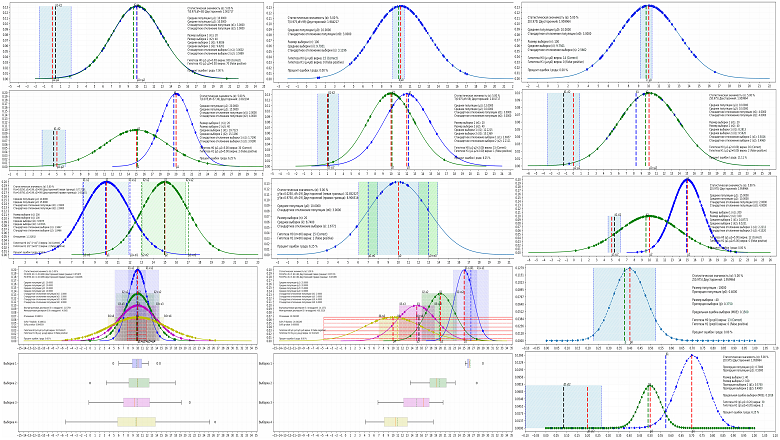
Каждому человеку хоть раз в жизни приходила в голову гениальная бизнес или продуктовая идея. Если Вы уже придумали идею продукта или решили предложить новый проект своему руководству, как определить его стоимость? Что делать если проект находится на концептуальной стадии или проект/продукт настолько уникален, что такой тип работ никогда в мире не проводился? Как оценить то, чего ещё не было? Как оценить решение проблем, с которыми ты ещё не столкнулся? Как оценить и не промахнуться в несколько раз?
Я руководитель международных проектов (PMP) и портфелей (PfMP) с реализованными проектами в Турции, Арабских Эмиратах, Германии, Франции, России и Беларуси. С более чем 10-летним опытом управления проектами и 4-летним опытом разработки автономных транспортных средств/робототехники и сегодня я хочу Вам рассказать об определении стоимости технически сложных продуктов и проектов.