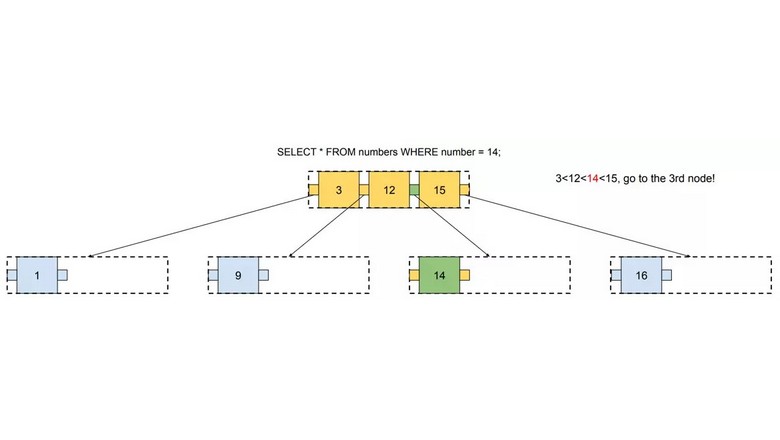
Романтическая научная фантастика XX века, а тем более космооперы, по-видимому, почти не учитывали фактор существенного отличия гравитации у разных планет, на которые приходится эпизодически высаживаться или колонизировать их. Как я уже писал в некоторых публикациях, в особенности, «Суперземля как иллюзия» и «Гикеаны, потомки нептунов», мы в настоящее время настолько одержимы идеей, что среди экзопланет найдётся множество жизнепригодных или даже обитаемых, что на месте мининептуна всегда готовы увидеть суперземлю. Впрочем, такое заблуждение характерно не только для нашего времени. Ещё в начале XX века Венера считалась «юной сестрой» Земли (так как предполагалось, что, чем ближе планета к Солнцу, тем позже она сформировалась), что там может царить тропическая эра, подобная мезозою, шуметь экзотические леса, а обширные океаны из-за сильной минерализации могут быть наполнены «зельтерской водой». Климат Венеры и её парниковый эффект – тема для отдельной публикации, и пока ограничусь ссылкой на это исследование 2019 года, в котором выдвигается гипотеза, что бесконтрольный парниковый эффект на Венере существует лишь чуть более 700 миллионов лет, а до этого там могли существовать вполне комфортные для жизни условия. А в этой статье попробуем обсудить феномен гравитационных колодцев и их опасность при сближении с суперземлями. Отдельно поблагодарю уважаемого @ilmarinen за его интереснейшие публикации о гравитационных манёврах в ныне закрытом корпоративном блоге «Маклауд», под впечатлением от которых я взялся писать эту статью.

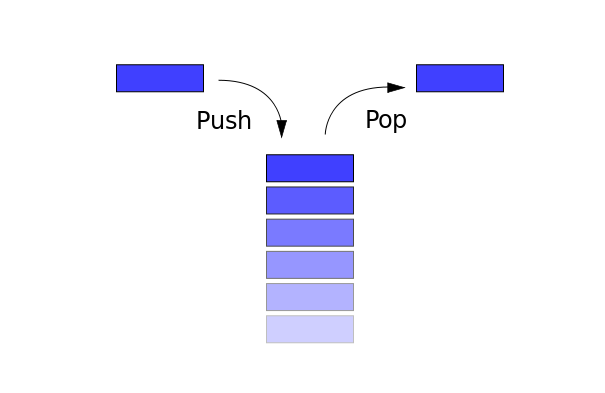
 методики FAANG — по этой причине практически во всех IT-собесах есть она: секция алгоритмов. Кто-то ей рад, кто-то не очень, но секция есть и уходить пока не планирует. Поэтому нужно закатать рукава и достойно встретить суровую реальность.
методики FAANG — по этой причине практически во всех IT-собесах есть она: секция алгоритмов. Кто-то ей рад, кто-то не очень, но секция есть и уходить пока не планирует. Поэтому нужно закатать рукава и достойно встретить суровую реальность.