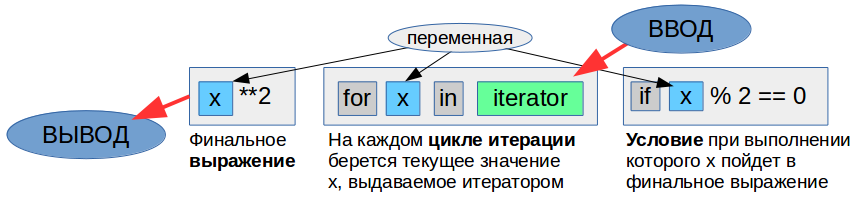
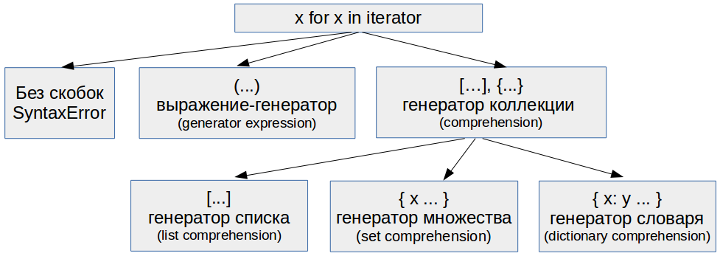
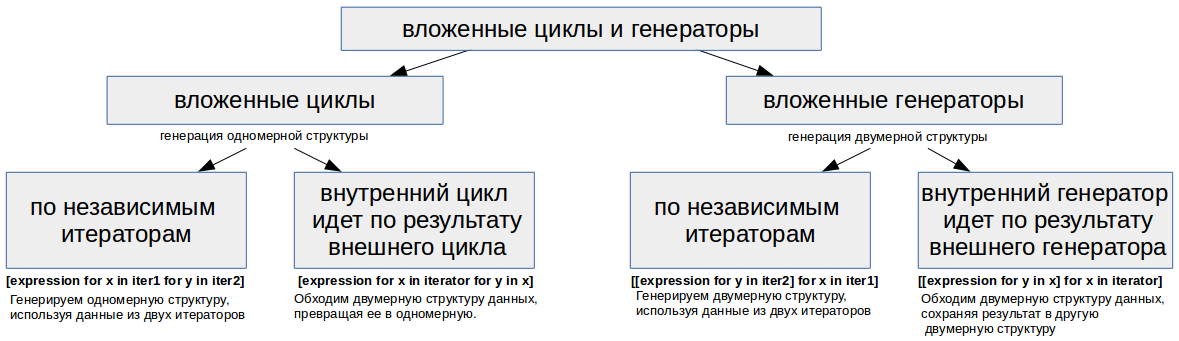
Содержание
В предыдущей статье мы начали реализацию транзакций, а также ознакомились с принципом ее работы: нет учетных записей, личные данные (например, имя или серия и номер паспорта) не требуются и не хранятся нигде в Bitcoin. Но все же должно быть что-то, что идентифицирует вас как владельца выходов транзакции (т. е. владельца монет, заблокированных на выходах). И это то, для чего нужны адреса в Bitcoin. До сих пор мы использовали произвольные строки в качестве адресов, теперь пришло время реализовать реальные адреса, таким образом, каким они реализованы в Bitcoin.
- Blockchain на Go. Часть 1: Прототип
- Blockchain на Go. Часть 2: Proof-of-Work
- Blockchain на Go. Часть 3: Постоянная память и интерфейс командной строки
- Blockchain на Go. Часть 4: Транзакции, часть 1
- Blockchain на Go. Часть 5: Адреса
- Blockchain на Go. Часть 6: Транзакции, часть 2
- Blockchain на Go. Часть 7: Сеть
Вступление
В предыдущей статье мы начали реализацию транзакций, а также ознакомились с принципом ее работы: нет учетных записей, личные данные (например, имя или серия и номер паспорта) не требуются и не хранятся нигде в Bitcoin. Но все же должно быть что-то, что идентифицирует вас как владельца выходов транзакции (т. е. владельца монет, заблокированных на выходах). И это то, для чего нужны адреса в Bitcoin. До сих пор мы использовали произвольные строки в качестве адресов, теперь пришло время реализовать реальные адреса, таким образом, каким они реализованы в Bitcoin.