Привет, Хабр. Я Игорь, руководитель команды, которая борется с мошенниками на Авито. Сегодня поговорим про вечную битву с негодяями, которые пытаются и даже иногда обманывают интернет-покупателей с помощью доставки товаров.


Пользователь
Привет, Хабр. Я Игорь, руководитель команды, которая борется с мошенниками на Авито. Сегодня поговорим про вечную битву с негодяями, которые пытаются и даже иногда обманывают интернет-покупателей с помощью доставки товаров.

Онлайн-курсы, кроме своей удобности и доступности, славятся тем, что на них необычайно легко забивать, что с успехом и делают многие слушатели. Забивать слушателям случается по самым разным причинам — непонятен курс, пропущен дедлайн, не успел набрать баллы, вышел Fallout 4 – у всех свои оправдания. А вот у нас оправданий быть не может: если человек покидает курс, мир теряет потенциального разработчика или специалиста по анализу данных, а ещё киловатт-часы и затраченное нашим героем время.
Самая сложная задача здесь — определить, кто из пользователей убежит, а зная их, уже намного проще предотвратить потери: “предупрежден, значит вооружен”.
В конце статьи вы узнаете, как с помощью решения проблемы попасть на хакатон по анализу данных


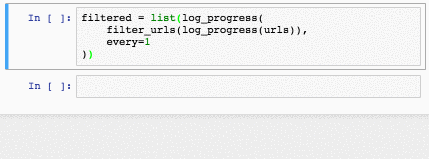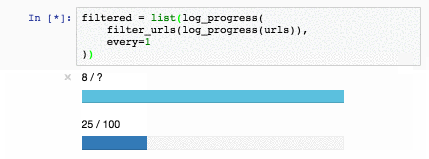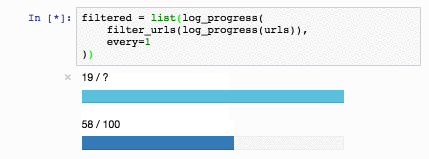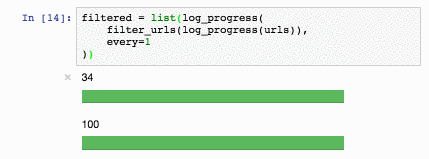
def log_progress(sequence, every=10):
for index, item in enumerate(sequence):
if index % every == 0:
print >>sys.stderr, index,
yield item






 Представьте себя в большом конференц-зале, набитом сотнями специалистов с бэйджиками на груди. Стаи тревожно выглядящих людей в перерыве слоняются мимо столов с закусками, уставленными печеньками и пирожками. Другие – вальсируют сквозь лабиринт тумб партнёров, рядом с которыми мужчины и женщины в деловых нарядах колдуют над аккуратно выложенными рекламными брошюрами и фирменными ручками. Третьи стоят, уставившись в свои телефоны…
Представьте себя в большом конференц-зале, набитом сотнями специалистов с бэйджиками на груди. Стаи тревожно выглядящих людей в перерыве слоняются мимо столов с закусками, уставленными печеньками и пирожками. Другие – вальсируют сквозь лабиринт тумб партнёров, рядом с которыми мужчины и женщины в деловых нарядах колдуют над аккуратно выложенными рекламными брошюрами и фирменными ручками. Третьи стоят, уставившись в свои телефоны…