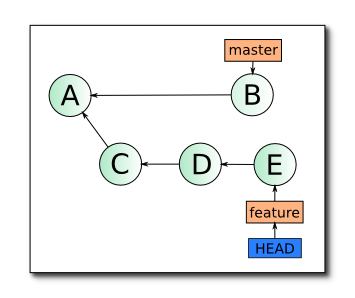
Время от времени мне приходится распутывать терминологические хитросплетения, связанные с употреблением словосочетаний, в которых встречается слово Selenium – Selenium 2.0, Selenium IDE, Selenium RC, Selenium WebDriver, Selenium Server, Selenium Grid.
Путаница возникает во многом из-за того, что нигде нет чёткого описания всех этих терминов на одной страничке, и я постараюсь восполнить этот информационный пробел.
Путаница возникает во многом из-за того, что нигде нет чёткого описания всех этих терминов на одной страничке, и я постараюсь восполнить этот информационный пробел.
 Когда вы выросли настолько, что появились узлы в разных городах, возникает задача распределения нагрузки между ними. Задачи такой балансировки могут быть разными, но цель, как правило, одна: сделать так, чтобы было хорошо. У меня дошли руки рассказать о том, как это делают обычно, и как это сделано в
Когда вы выросли настолько, что появились узлы в разных городах, возникает задача распределения нагрузки между ними. Задачи такой балансировки могут быть разными, но цель, как правило, одна: сделать так, чтобы было хорошо. У меня дошли руки рассказать о том, как это делают обычно, и как это сделано в  Как часто вам приходится разрабатывать и запускать приложение локально и упорно искать проблемы, потому что на продакшене приложение ведёт себя не совсем так, как вы этого хотели? А как часто вам присылают тикеты для решения проблемы в приложении, хотя на самом деле проблема именно в несовместимости версий разных приложений? А как долго вам приходится ждать виртуалку, когда для запуска новой версии приложения недостаточно ресурсов локальной машины? Для нас эти вопросы были довольно больными, и мы сломали тысячи копий в спорах, стараясь решить их. Практика показывает, что одним из вариантов для решения этих проблем может стать Vagrant.
Как часто вам приходится разрабатывать и запускать приложение локально и упорно искать проблемы, потому что на продакшене приложение ведёт себя не совсем так, как вы этого хотели? А как часто вам присылают тикеты для решения проблемы в приложении, хотя на самом деле проблема именно в несовместимости версий разных приложений? А как долго вам приходится ждать виртуалку, когда для запуска новой версии приложения недостаточно ресурсов локальной машины? Для нас эти вопросы были довольно больными, и мы сломали тысячи копий в спорах, стараясь решить их. Практика показывает, что одним из вариантов для решения этих проблем может стать Vagrant. 
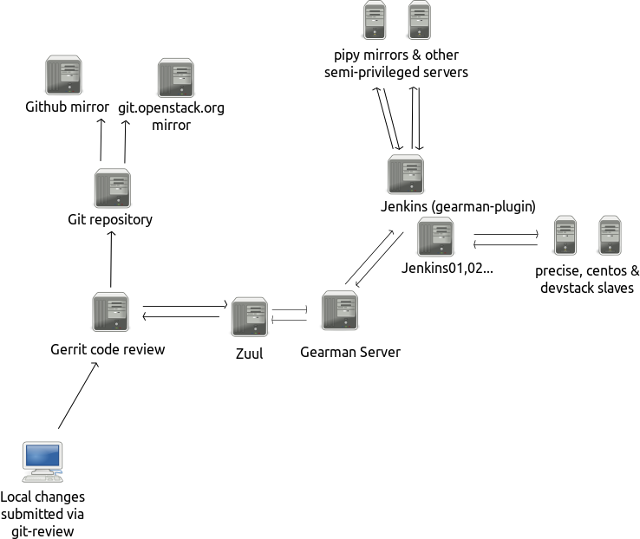
 Эта статья — How To, которое поможет вам легко обеспечить миграцию между версиями БД ваших PHP приложений с помощью
Эта статья — How To, которое поможет вам легко обеспечить миграцию между версиями БД ваших PHP приложений с помощью