
В начале мая 2016 года, еще до окончания объединения с Dell, компания EMC объявила о выходе нового поколения массивов среднего уровня под именем Unity. В сентябре 2016 года к нам привезли демо-массив Unty 400F в конфигурации с 10 SSD дисками на 1.6TB каждый. В чем различие между моделями с индексом F и без оного можете почитать по данной ссылке в блоге Дениса Серова. Так как перед передачей демо дальше заказчику возник временной лаг, то было принято решение погонять массив тем же самым тестом, которым ранее уже нагружались VNXe3200 и VNX5400. Что бы посмотреть хотя бы на «синтетике» так ли хорош Unity по сравнению с предыдущими поколениями массивов EMC, как это расписывает вендор. Тем более что, судя по презентациям вендора, Unity 400 является прямой заменой VNX5400.
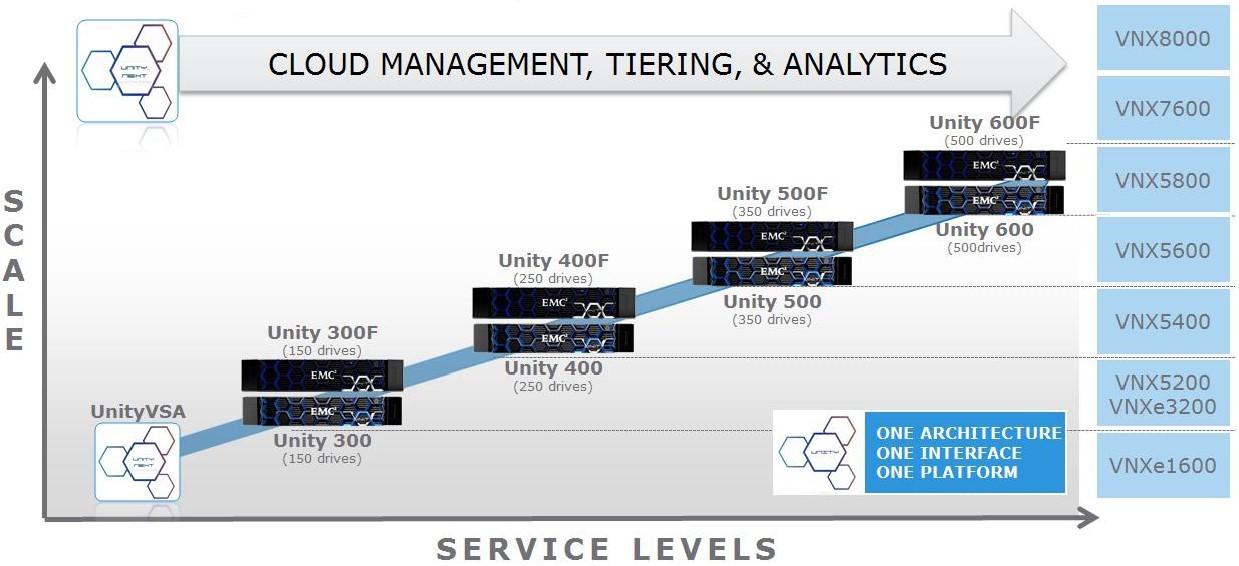
А DellEMC утверждает, что новое поколение по крайней мере в 3 раза производительнее, чем VNX2.
Если интересно, что из всего этого вышло, то…
А DellEMC утверждает, что новое поколение по крайней мере в 3 раза производительнее, чем VNX2.
Если интересно, что из всего этого вышло, то…



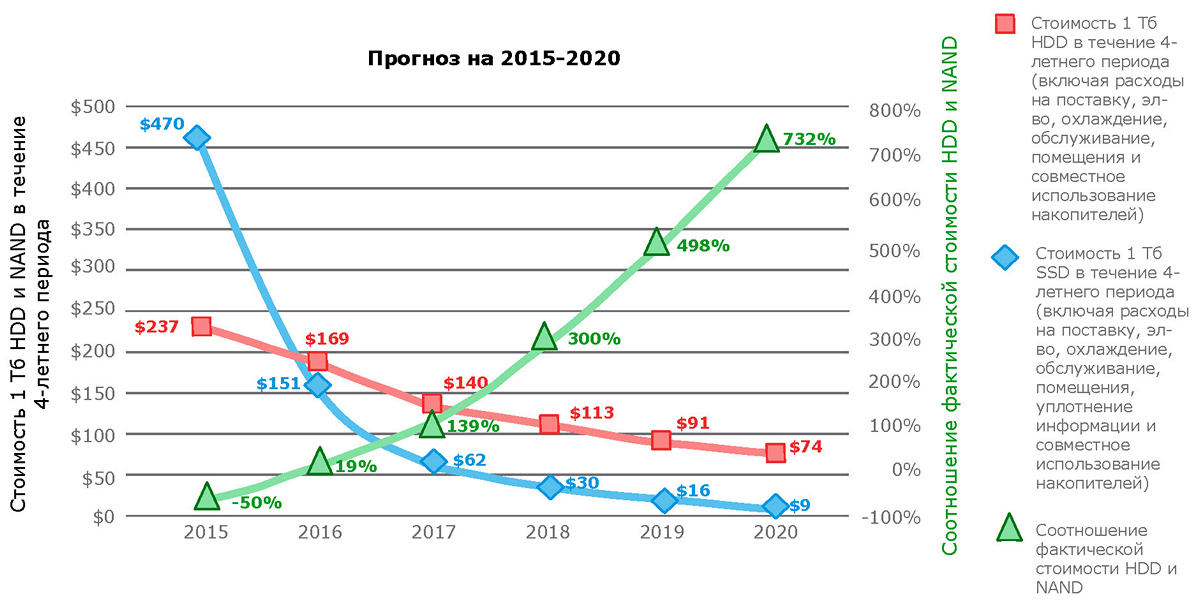








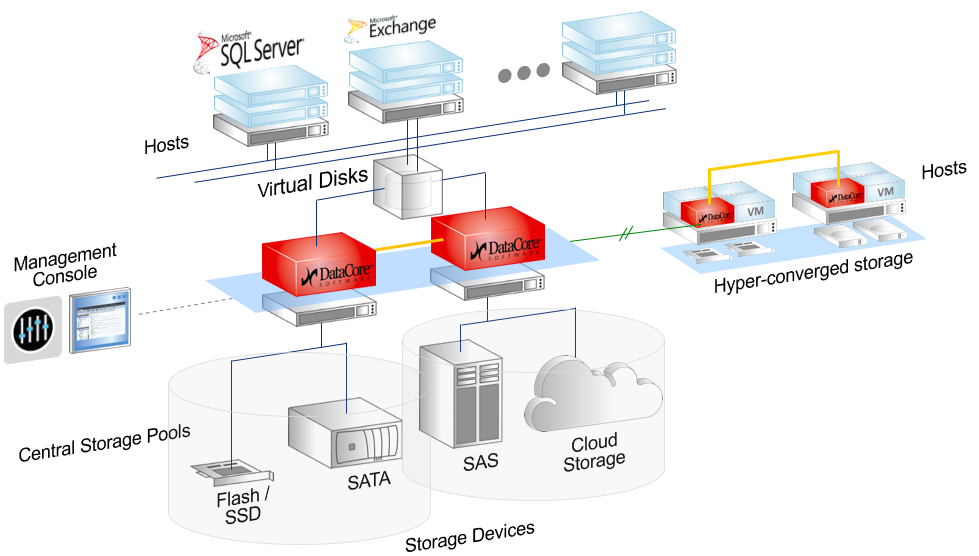

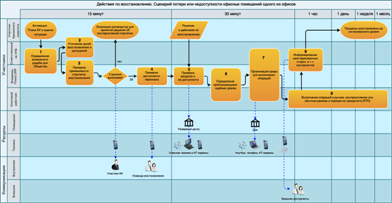
 Продолжая и дополняя тему номера «Отказы и аварии в ЦОД», мы поделимся несколькими наблюдениями без претензии на серьезный анализ причин и следствий. Возможно, некоторые моменты покажутся читателю курьезными и забавными, хотя все, что происходило, было очень серьезно. Надеемся, эти достаточно поучительные истории позволят читателю самому сделать выводы.
Продолжая и дополняя тему номера «Отказы и аварии в ЦОД», мы поделимся несколькими наблюдениями без претензии на серьезный анализ причин и следствий. Возможно, некоторые моменты покажутся читателю курьезными и забавными, хотя все, что происходило, было очень серьезно. Надеемся, эти достаточно поучительные истории позволят читателю самому сделать выводы. 