763 и 759 выглядят более правдоподобно, в этом случае задержка получается
10 / (763 + 759) ≈ 0.006570 с = 6570 мкс.
измеренная fio
(5071 + 8018) / 2 = 6544.5
опять неплохо сходится.
не могли бы вы повторить тест с параметрами write_iops_log и write_lat_log и выложить результат? хочу попробовать разобраться откуда взялись 5000 iops.
Не смущает, что на рисунке latency примерно 2/3 t?
смущает. потому что, очевидно, продолжительность измерений должна быть на порядки больше задержек ввода-вывода.
Вот еще рисунок в котором допустим два разных SSD с разной latency.
честно говоря, не понимаю, что вы хотите этими картинками показать.
в обоих случаях формула latency ≈ qd/iops будет более-менее работать (более-менее потому, что непонятно как точно считать iops на интервалах, соизмеримых с задержкой ввода/вывода)
Можно, конечно, сказать, что IOPSы здесь неправильно нарисованы и надо все заштриховать, но когда вы все заштрихуете (упретесь в возможности контроллера, забив его длинной очередью), у вас скорее всего из-за неспособности больше операций прожевать latency начнет сильно расти, возможно экспоненциально. С огромной дисперсией. Причем рост начнется не по забиванию контроллера, а даже раньше, когда забьете очередью каналы в контроллере, кеши и какие-нибудь другие ресурсы, которые внутрях есть.
не понял что вы имеете в виду под «всё заштриховать».
увеличить qd? так мы пока говорили про измерения с постоянной (не важно какой, важно, что не меняющейся в процессе теста) глубиной очереди.
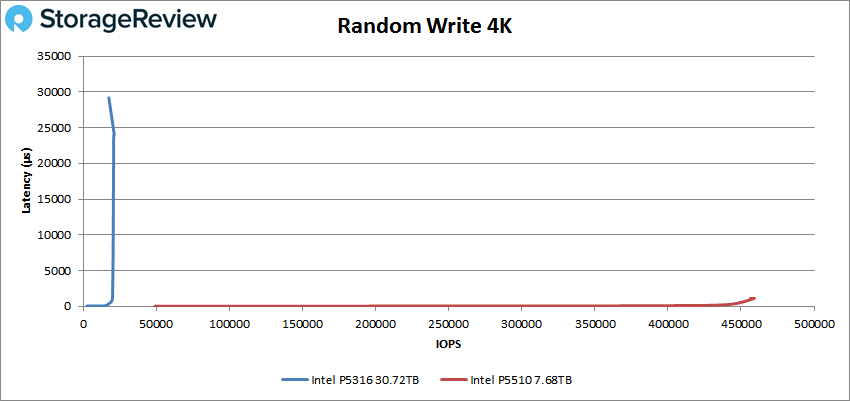
Ну и на графики StorageReview выше посмотрите. Вы видите на них ту зависимость latency ~ 1/IOPS?
а где там графики с постоянной qd?
сама идея не ограничивать qd, а ограничивать iops и строить зависимость latency от iops мне нравится, но вот реализация на storagereview не выдерживает никакой критики — из-за того, что на графики попадают секундные «хвосты», разглядеть задержки в левой части графика проблематично, а таблиц с числовыми значениями сходу я не нашёл.
измеренное же fio значение (94.68 + 12.92) / 2 = 53.80 мкс, отличие менее 1%.
почему в вашем примере не так — сходу не могу сказать.
подозреваю, что среднее значение iops в вашем примере «показывает погоду на марсе», но, к сожалению, за несколько минут я не смог разобраться как именно оно считается в fio.
Теперь Интел всем должен за стагнацию в развитии процессоров, которую Ryzen'ы якобы переломили (а по факту лишь в прошлом году смогли временно перегнать Core'ы)
именно что переломили, с появлением реальной конкуренции с райзенами прогресс у intel явно ускорился.
И при этом никого почему-то не волнует, что AVX512 в продуктах AMD вообще не присутствует.
что удивительного в том, что amd внедряет новые команды разработки intel позднее, чем intel?
А это пример пользовательского SSD, у которого латентность 5 мс (как у HDD) уже при 25 тыс. IOPS.
так это не sata виновата, это накопитель такой )
запустил на своём s3510 чтение в 4 потока, получил 30к iops и задержки 130 мкс. в 8 потоков 150 мкс. в 16 250 мкс (вот тут уже начал насыщаться контроллер на ssd; напоминаю, что это накопитель начального уровня).
заметьте, до насыщения шины ещё далеко, она не утилизирована ещё и наполовину, так что дело точно не в шине, а в самом накопителе.
Латентность — важная величина. NVMe для баз данных именно за нее и выбирают (NAND-то одинаковая и в SATA и в NVMe). Поэтому её стоит приводить в бенчмарках.
на самом деле время доступа/иопсы/мегабайты в секунду элементарно пересчитываются друг в друга.
из теста в предыдущем абзаце 130 мкс задержки в 4 потока на блоках 4 КБ эквиваленты 4/130e-6 ≈ 30к iops или же 120 МБ/с.
напомню, что я изначально написал
при времени доступа к nand >>50 мкс задержки шины уже особой роли не играют
при qd=1 время доступа чтения будет примерно 100 мкс что на sata, что на nvme накопителях.
и при qd=4, и при qd=8 тоже, я вам показал. и даже при qd=16 цифры сопоставимы.
да, при qd=1024 время доступа у nvme будет в разы меньше (а иопсы пропорционально выше), но если у вас на сервере qd=1024, то, скорее всего, что-то пошло не так.
на своих нагрузках разницу между sata и nvme накопителями в БД я вижу только в задачах вроде бэкапов; в типичной нагрузке на базу данных (если там нет seqscan'ов) разницы нет.
впрочем, повторюсь, сейчас sata ssd по сути уже не дешевле nvme, так что смысла выбирать sata нет.
Появляется дополнительный программный слой и дополнительный аппаратный (контроллер).
вы про sata?
так и nvme не обходится без программного слоя )
да, на один контроллер в цепочке cpu — nand в случае nvme меньше, но узким местом является не наличие контроллера само по себе, а достаточно узкая шина между ним и накопителем.
Только вчера читал тестирование PostgreSQL 2014 года и на SATA у них было что-то там 50 тыс. tps, а на NVMe 400 тыс. tps, а в RAM если диск держать 1500 тыс. tps.
ну это очень специфичная нагрузка, почти наверняка синтетика.
ноги растут из hdd: в те времена запросы накопители обрабатывали долго, накапливалась очередь. так как время доступа определяется механикой, то единственным способом улучшить производительность было увеличение числа шпинделей, а большие очереди — с одной стороны нормой, с другой — единственным способом утилизировать потенциальную производительность дисковой системы.
с приходом ssd ситуация в корне поменялась, среднее время доступа из 5-10 мс стало 50-100 мкс, то есть на два порядка ниже (притом, как я писал выше, оно определяется nand, и особо не зависит от интерфейса); плюс оно практически не растёт до до некоторого порога нагрузки (на hdd оно растёт лавинообразно при qd>1 на шпиндель), в результате выигрыш в производительности в сравнении с hdd несколько порядков.
в итоге, до некоторой (и достаточно большой для реальной жизни) нагрузки все ssd независимо от интерфейса примерно одинаковы, потом сдаётся sata, потом sas, ну а у nvme самый высокий потенциал.
ну так вот, привычка тестировать дисковую подсистему с глубиной очереди 100500 никуда не делась со времён hdd, только к реальным нагрузкам это тестирование имеет мало отношения.
условная аналогия: мы сравниваем суперкары по скорости разгона с 200 км/ч до 300 км/ч, да, это сравнение покажет какой кар круче, но к скорости передвижения в городском потоке это будет иметь мало отношения (скорость разгона до 80 км/ч, более актуальная в городе, у них, скорее всего, окажется примерно одинаковой).
P. S. весь этот текст был про случайный доступ, на последовательном sata сдаётся достаточно рано, на каких-нибудь бэкапах разница между sata и sas/nvme может быть видна невооружённым глазом.
P. P. S. с другой стороны, сегодня nvme накопители обычно стоят примерно как sata, поэтому выбирать sata никакого смысла нет. sas ssd же вообще для меня какая-то экзотика )
Из-за последнего существует 2 способа взаимодействия со случайными числами в Linux — /dev/random и /dev/urandom. Первый блокируется, когда оценка по количеству энтропии становится ниже нуля, а второй выдает числа всегда, даже если пул не пополняется случайными битам
In 2020, the Linux kernel version 5.6 /dev/random only blocks when the CPRNG hasn't initialized. Once initialized, /dev/random and /dev/urandom behave the same

гхм, цель intel (как и любой коммерческой компании) не в выпуске «получше и подешевле», а в зарабатывании денег, с этим у них всё хорошо.
https://www.intc.com/news-events/press-releases/detail/1505/intel-reports-third-quarter-2021-financial-results
вы явно не понимаете что такое O-нотация.
оценивается не насколько алгоритм быстр, а как затрачиваемое время изменяется при изменении
nну вот, например:
https://habr.com/ru/news/t/532060/
с настоящей оборонкой всё куда хуже.
я думаю, что там всё-таки совсем другое среднее значение iops.
763 и 759 выглядят более правдоподобно, в этом случае задержка получается
10 / (763 + 759) ≈ 0.006570 с = 6570 мкс.
измеренная fio
(5071 + 8018) / 2 = 6544.5
опять неплохо сходится.
не могли бы вы повторить тест с параметрами
write_iops_logиwrite_lat_logи выложить результат? хочу попробовать разобраться откуда взялись 5000 iops.смущает. потому что, очевидно, продолжительность измерений должна быть на порядки больше задержек ввода-вывода.
честно говоря, не понимаю, что вы хотите этими картинками показать.
в обоих случаях формула latency ≈ qd/iops будет более-менее работать (более-менее потому, что непонятно как точно считать iops на интервалах, соизмеримых с задержкой ввода/вывода)
не понял что вы имеете в виду под «всё заштриховать».
увеличить qd? так мы пока говорили про измерения с постоянной (не важно какой, важно, что не меняющейся в процессе теста) глубиной очереди.
а где там графики с постоянной qd?
сама идея не ограничивать qd, а ограничивать iops и строить зависимость latency от iops мне нравится, но вот реализация на storagereview не выдерживает никакой критики — из-за того, что на графики попадают секундные «хвосты», разглядеть задержки в левой части графика проблематично, а таблиц с числовыми значениями сходу я не нашёл.
имеем 92.2к iops на чтение + 92.2к iops на запись, считаем
latency = 10 / (92200 + 92200) ≈ 54.23 мкс
измеренное же fio значение (94.68 + 12.92) / 2 = 53.80 мкс, отличие менее 1%.
почему в вашем примере не так — сходу не могу сказать.
подозреваю, что среднее значение iops в вашем примере «показывает погоду на марсе», но, к сожалению, за несколько минут я не смог разобраться как именно оно считается в fio.
а что не так-то?
по вашей картинке:
iops=10/t (за t секунд произошло 10 операций)
latency≈t
по предложенной формуле:
latency≈qd/iops=10/(10/t)=t
какого года этот процессор?
у вас есть как минимум 5 вариантов действий:
расскажите, пожалуйста, о простых и стабильных способах суммирования пропускной способности каналов
сейчас на глаза попался обзор nvme-накопителя на qlc:
Что, сынку, помогли тебе твои
ляхиpci-e gen4?пруф можно?
именно что переломили, с появлением реальной конкуренции с райзенами прогресс у intel явно ускорился.
что удивительного в том, что amd внедряет новые команды разработки intel позднее, чем intel?
любые накопители выходят из строя с потерей данных, примите это как аксиому.
нужно хранить данные — делайте бэкапы.
IOPS=QD/latency
небольшая ошибка набегает из-за усреднений, но обычно это единицы процентов.
так это не sata виновата, это накопитель такой )
запустил на своём s3510 чтение в 4 потока, получил 30к iops и задержки 130 мкс. в 8 потоков 150 мкс. в 16 250 мкс (вот тут уже начал насыщаться контроллер на ssd; напоминаю, что это накопитель начального уровня).
заметьте, до насыщения шины ещё далеко, она не утилизирована ещё и наполовину, так что дело точно не в шине, а в самом накопителе.
на самом деле время доступа/иопсы/мегабайты в секунду элементарно пересчитываются друг в друга.
из теста в предыдущем абзаце 130 мкс задержки в 4 потока на блоках 4 КБ эквиваленты 4/130e-6 ≈ 30к iops или же 120 МБ/с.
напомню, что я изначально написал
при qd=1 время доступа чтения будет примерно 100 мкс что на sata, что на nvme накопителях.
и при qd=4, и при qd=8 тоже, я вам показал. и даже при qd=16 цифры сопоставимы.
да, при qd=1024 время доступа у nvme будет в разы меньше (а иопсы пропорционально выше), но если у вас на сервере qd=1024, то, скорее всего, что-то пошло не так.
на своих нагрузках разницу между sata и nvme накопителями в БД я вижу только в задачах вроде бэкапов; в типичной нагрузке на базу данных (если там нет seqscan'ов) разницы нет.
впрочем, повторюсь, сейчас sata ssd по сути уже не дешевле nvme, так что смысла выбирать sata нет.
ну так я про это и писал, перечитайте внимательнее.
специально взял термин в кавычки (побуду КО: один из возможных смыслов кавычек — якобы).
вы про sata?
так и nvme не обходится без программного слоя )
да, на один контроллер в цепочке cpu — nand в случае nvme меньше, но узким местом является не наличие контроллера само по себе, а достаточно узкая шина между ним и накопителем.
ну это очень специфичная нагрузка, почти наверняка синтетика.
ноги растут из hdd: в те времена запросы накопители обрабатывали долго, накапливалась очередь. так как время доступа определяется механикой, то единственным способом улучшить производительность было увеличение числа шпинделей, а большие очереди — с одной стороны нормой, с другой — единственным способом утилизировать потенциальную производительность дисковой системы.
с приходом ssd ситуация в корне поменялась, среднее время доступа из 5-10 мс стало 50-100 мкс, то есть на два порядка ниже (притом, как я писал выше, оно определяется nand, и особо не зависит от интерфейса); плюс оно практически не растёт до до некоторого порога нагрузки (на hdd оно растёт лавинообразно при qd>1 на шпиндель), в результате выигрыш в производительности в сравнении с hdd несколько порядков.
в итоге, до некоторой (и достаточно большой для реальной жизни) нагрузки все ssd независимо от интерфейса примерно одинаковы, потом сдаётся sata, потом sas, ну а у nvme самый высокий потенциал.
ну так вот, привычка тестировать дисковую подсистему с глубиной очереди 100500 никуда не делась со времён hdd, только к реальным нагрузкам это тестирование имеет мало отношения.
условная аналогия: мы сравниваем суперкары по скорости разгона с 200 км/ч до 300 км/ч, да, это сравнение покажет какой кар круче, но к скорости передвижения в городском потоке это будет иметь мало отношения (скорость разгона до 80 км/ч, более актуальная в городе, у них, скорее всего, окажется примерно одинаковой).
P. S. весь этот текст был про случайный доступ, на последовательном sata сдаётся достаточно рано, на каких-нибудь бэкапах разница между sata и sas/nvme может быть видна невооружённым глазом.
P. P. S. с другой стороны, сегодня nvme накопители обычно стоят примерно как sata, поэтому выбирать sata никакого смысла нет. sas ssd же вообще для меня какая-то экзотика )
In 2020, the Linux kernel version 5.6 /dev/random only blocks when the CPRNG hasn't initialized. Once initialized, /dev/random and /dev/urandom behave the same
как раз zfs должно (должна?) откатываться на консистентное состояние и в том случае, если диски врут