Эта статья посвящена поверхностному обзору ключевых подходов к достижению консенсуса в децентрализованной среде. Материал позволит разобраться с задачами, которые решают рассмотренные протоколы, областью их применения, особенностями проектирования и использования, а также позволит оценить перспективы их развития и имплементации в децентрализованных системах учета.

Пользователь
Marvel: Infinity War или Как собрать данные под свой проект за пару минут
4 мин

У меня есть две сферы интересов. Первая: общество анонимных
Диод. Светодиод. Стабилитрон
13 мин
Туториал

Не влезай. Убьет! (с)
Постараюсь объяснить работу с диодами, светодиодами, а также стабилитронами на пальцах. Опытные электронщики могут пропустить статью, поскольку ничего нового для себя не обнаружат. Не буду вдаваться в теорию электронно-дырочной проводимости pn-перехода. Я считаю, что такой подход обучения только запутает начинающих. Это голая теория, почти не имеющая отношения к практике. Впрочем, интересующимся теорией предлагаю эту статью. Всем желающим добро пожаловать под кат.
Рыцари плаща и руткитов: что посмотреть про хакеров. Сериалы
8 мин
Лето — пора путешествий и заслуженного отдыха. Каким бы ни было путешествие и куда бы вы ни направлялись, наверняка, это будет длинная дорога (авиаперелет или поезд), или же среднего качества связь, если мы говорим об удаленных от благ цивилизации местах.
Обычно запасливые люди берут с собой в путешествие кучу фильмов и сериалов, чтобы было чем заткнуть уши в транспорте и слушать голоса любимых персонажей.
Мы приготовили для вас небольшую подборку сериалов, так или иначе связанных с ИT. А натолкнула нас на идею этого поста многолетняя дружба ЛАНИТ с Международным фестивалем документального кино "ДОКЕР", где, кстати, в том числе с нашей помощью традиционной стала номинация для фильмов о возможностях информационных технологий «Let IT Doк!».
 Кадр из сериала «Mr. Robot» (eps3.1_undo.gz)
Кадр из сериала «Mr. Robot» (eps3.1_undo.gz)
Обычно запасливые люди берут с собой в путешествие кучу фильмов и сериалов, чтобы было чем заткнуть уши в транспорте и слушать голоса любимых персонажей.
Мы приготовили для вас небольшую подборку сериалов, так или иначе связанных с ИT. А натолкнула нас на идею этого поста многолетняя дружба ЛАНИТ с Международным фестивалем документального кино "ДОКЕР", где, кстати, в том числе с нашей помощью традиционной стала номинация для фильмов о возможностях информационных технологий «Let IT Doк!».
Сборник демографических рассказов в одной карте
2 мин

В свежем номере журнала The Lancet опубликована моя статья — любопытная карта и небольшое к ней пояснение. Решил рассказать об этом на Хабре, поскольку есть надежда, что реализованный способ визуализации данных может пригодиться еще кому-то.
Kashnitsky, I., & Schöley, J. (2018). Regional population structures at a glance. The Lancet, 392(10143), 209–210. https://doi.org/10.1016/S0140-6736(18)31194-2
Собственно, вот карта в высоком разрешении (кликабельно).
Карту можно воспроизвести точь-в-точь за несколько минут, код на гитхабе.
Данные создают цвета
10 курсов по машинному обучению на лето
5 мин
За последние десятилетия с помощью машинного обучения создали самоуправляемые автомобили, системы распознавание речи и эффективный поиск. Сейчас это одна из самых быстроразвивающихся и перспективных сфер на стыке компьютерных наук и статистики, которая активно используется в искусственном интеллекте и data science. Методы машинного обучения используются в науке, технике, медицине, ритейле, рекламе, генерации мультимедиа и других областях.
Команда Университета ИТМО собрала десять курсов по машинному обучению, которые можно успеть пройти до конца лета. Одним они помогут войти в профессию, а другим — углубиться в нее.

Команда Университета ИТМО собрала десять курсов по машинному обучению, которые можно успеть пройти до конца лета. Одним они помогут войти в профессию, а другим — углубиться в нее.
4 года Data Science в Schibsted Media Group
17 мин
Перевод

В 2014-м году я присоединился к небольшой команде в Schibsted Media Group в качестве 6-го специалиста по Data Science в этой компании. С тех пор я поработал над многими начинаниями в области Data Science в организации, в которой теперь таких уже 40 с лишним человек. В этом посте я расскажу о некоторых вещах, о которых узнал за последние четыре года, сперва как специалист, а затем как менеджер Data Science.
Этот пост следует примеру Robert Chang и его отличной статьи «Doing Data Science in Twitter», которую я нашел очень ценной, когда впервые прочитал ее в 2015-м году. Цель моего собственного вклада ― поведать настолько же полезные мысли специалистам и менеджерам Data Science по всему миру.
Я поделил пост на две части:
- Часть I: Data Science в реальной жизни
- Часть II: Управление командой Data Science
Онлайн, офлайн и P2P: как купить биткоин в России
4 мин

Изображение: VanityFair
{kind=link}
В последнее время цена самой популярной криптовалюты снижалась и сегодня находится на уровнях далеких от максимумов прошлого года, когда биткоин стоил более $20 тыс. При этом, популярность криптовалют только растет — по данным Statista, число криптокошельков приближается к 25 млн. Растет и количество способов приобретения криптовалюты — сегодня речь пойдет о тех из них, что доступны пользователям из нашей страны.
Визуализация статистики использования компьютера с R
6 мин

Думаю, многим интересно (хотя бы из любопытства), как именно они используют свой компьютер: самые нажимаемые кнопки, пройденное мышью расстояние, среднее время работы и другую информацию. В этой статье я расскажу один из вариантов того, как можно собрать такую информацию и затем представить её в виде интерактивных графиков. Все описанные действия производились на ноутбуке с ОС
Debian Wheezy, Python 2.7.3, R 2.15.
Параллелим R
3 мин
Туториал
Введение
Сейчас практически невозможно представить себе мир без параллельных вычислений. Параллелят все и вся, даже у мобильных телефонов теперь несколько ядер, а значит… ну вы понимаете. Но давайте поговорим не о мобильных приложениях, а о более полезных и интересных вещах. О машинном обучении. Тема тоже модная, разрекламированная, про машинное обучение слышали даже домохозяйки и только ленивый еще не трогал это руками. Для машинного обучения, и если быть более точным, для статистических расчетов есть множество разных фреймворков, на мой вкус лучший из них – R (да простят меня поклонники Octave). И речь пойдет именно о нем.
Disclaimer:
я не претендую на особую строгость изложения, моя задача донести до читателей общую мысль.
Анализируем Twitter при помощи R
4 мин
Здравствуйте, уважаемое хабрасообщество!
На Хабре уже несколько раз говорили о возможностях среды R, но я считаю, что дополнительная информация станет полезной, так как R — это очень интересный и мощный инструмент, который может быть применен в самых разных областях. Я попробую это доказать на примере анализа появления одного из трендов Twitter. Для этого нам понадобится библиотека twitteR, которая позволяет работать с Twitter через API. Но для начала расскажу подробнее об R.
На Хабре уже несколько раз говорили о возможностях среды R, но я считаю, что дополнительная информация станет полезной, так как R — это очень интересный и мощный инструмент, который может быть применен в самых разных областях. Я попробую это доказать на примере анализа появления одного из трендов Twitter. Для этого нам понадобится библиотека twitteR, которая позволяет работать с Twitter через API. Но для начала расскажу подробнее об R.
Введение в смарт-контракты. Их потенциальные и реальные ограничения
21 мин
Перевод

Это, пожалуй, самая интересная статья о перспективах применения смарт-контрактов в деловой практике, которая мне попадалась (правда, попадалось их не так уж много). Она написана юристами и опубликована в конце мая на сайте Гарварда. Хоть и на примере США, текст раскрывает такие вопросы как применение законодательства к сделкам на смарт-контрактах, проблему понимания сторонами кода, проблему оракулов, риски и другие.
В том числе вы найдете объяснение, почему вендинговые аппараты (как пример наиболее наглядной и простой реализации смарт-контракта) люди используют давно и успешно, а использование более сложных смарт-контрактов, например в логистике или страховании, пока затруднительно.
Байесовские многорукие бандиты против A/B тестов
20 мин
 Здравствуйте, коллеги. Рассмотрим обычный онлайн-эксперимент в некоторой компании «Усы и когти». У неё есть веб-сайт, на котором есть красная кнопка в форме прямоугольника с закругленными краями. Если пользователь нажимает на эту кнопку, то где-то в мире мурлычет от радости один котенок. Задача компании — максимизация мурлыкания. Также есть отдел маркетинга, который усердно исследует формы кнопок и то, как они влияют на конверсию показов в клико-мурлыкания. Потратив почти весь бюджет компании на уникальные исследования, отдел маркетинга разделился на четыре противоборствующие группировоки. У каждой группировки есть своя гениальная идея того, как должна выглядеть кнопка. В целом никто не против формы кнопки, но красный цвет раздражает всех маркетологов, и в итоге было предложено четыре альтернативных варианта. На самом деле, даже не так важно, какие именно это варианты, нас интересует тот вариант, который максимизирует мурлыкания. Маркетинг предлагает провести A/B/n-тест, но мы не согласны: и так на эти сомнительные исследования спущено денег немерено. Попробуем осчастливить как можно больше котят и сэкономить на трафике. Для оптимизации трафика, пущенного на тесты, мы будем использовать шайку многоруких байесовских бандитов (bayesian multi-armed bandits). Вперед.
Здравствуйте, коллеги. Рассмотрим обычный онлайн-эксперимент в некоторой компании «Усы и когти». У неё есть веб-сайт, на котором есть красная кнопка в форме прямоугольника с закругленными краями. Если пользователь нажимает на эту кнопку, то где-то в мире мурлычет от радости один котенок. Задача компании — максимизация мурлыкания. Также есть отдел маркетинга, который усердно исследует формы кнопок и то, как они влияют на конверсию показов в клико-мурлыкания. Потратив почти весь бюджет компании на уникальные исследования, отдел маркетинга разделился на четыре противоборствующие группировоки. У каждой группировки есть своя гениальная идея того, как должна выглядеть кнопка. В целом никто не против формы кнопки, но красный цвет раздражает всех маркетологов, и в итоге было предложено четыре альтернативных варианта. На самом деле, даже не так важно, какие именно это варианты, нас интересует тот вариант, который максимизирует мурлыкания. Маркетинг предлагает провести A/B/n-тест, но мы не согласны: и так на эти сомнительные исследования спущено денег немерено. Попробуем осчастливить как можно больше котят и сэкономить на трафике. Для оптимизации трафика, пущенного на тесты, мы будем использовать шайку многоруких байесовских бандитов (bayesian multi-armed bandits). Вперед.
Невероятно эффектная цветомузыка на Arduino и светодиодах
4 мин
С наступающим! Приближается Новый год, а значит, пора срочно создавать настроение! Ну и как всегда в это время года рождаются десятки электронных схем различных цветомузыкальных установок.
Чего только самобытные мастера не придумают. От трехцветных моргалок до лазерных многолучевых установок с управлением по MIDI интерфейсу.

Как большой поклонник, так называемых адресных светодиодов, хочу показать вам очень простую и удивительную цветомузыку. Я вообще такой ни разу не видел. Пока не собрал за один вечер. Итак, визуализатор звука!
Чего только самобытные мастера не придумают. От трехцветных моргалок до лазерных многолучевых установок с управлением по MIDI интерфейсу.
Как большой поклонник, так называемых адресных светодиодов, хочу показать вам очень простую и удивительную цветомузыку. Я вообще такой ни разу не видел. Пока не собрал за один вечер. Итак, визуализатор звука!
Анализируй это — Lenta.ru
47 мин

Анализируй это. Lenta.ru (часть 1)
What, How, Why
Для тех кому лень читать — ссылка на датасет внизу статьи.
What — анализ статей новостного ресурса Lenta.ru за последние 18 лет (с 1 сентября 1999 года). How — средствами языка R (с привлечением программы MySterm от Yandex на отдельном участке). Why… В моем случае, коротким ответом на вопрос "почему" будет "получение опыта" в Big Data. Более развернутым же объяснением будет "выполнение какого-либо реального задания, в рамках которого я смогу применить навыки, полученные во время обучения, а так же получить результат, который я бы смог показывать в качестве подтверждения своих умений".
Пример решения задачи множественной регрессии с помощью Python
6 мин
Введение
Добрый день, уважаемые читатели.
В прошлых статьях, на практических примерах, мной были показаны способы решения задач классификации (задача кредитного скоринга) и основ анализа текстовой информации (задача о паспортах). Сегодня же мне бы хотелось коснуться другого класса задач, а именно восстановления регрессии. Задачи данного класса, как правило, используются при прогнозировании.
Для примера решения задачи прогнозирования, я взял набор данных Energy efficiency из крупнейшего репозитория UCI. В качестве инструментов по традиции будем использовать Python c аналитическими пакетами pandas и scikit-learn.
О выборе структур данных для начинающих
18 мин
Перевод

Часть 1. Линейные структуры
Массив
Когда вам нужен один объект, вы создаёте один объект. Когда нужно несколько объектов, тогда есть несколько вариантов на выбор. Я видел, как многие новички в коде пишут что-то типа такого:
// Таблица рекордов
int score1 = 0;
int score2 = 0;
int score3 = 0;
int score4 = 0;
int score5 = 0;Это даёт нам значение пяти рекордов. Этот способ неплохо работает, пока вам не потребуется пятьдесят или сто объектов. Вместо создания отдельных объектов можно использовать массив.
// Таблица рекордов
const int NUM_HIGH_SCORES = 5;
int highScore[NUM_HIGH_SCORES] = {0};Будет создан буфер из 5 элементов, вот такой:

Заметьте, что индекс массива начинается с нуля. Если в массиве пять элементов, то они будут иметь индексы от нуля до четырёх.
Топливо для ИИ: подборка открытых датасетов для машинного обучения
6 мин

Связанные проекты сообщества Open Data (проект Linked Open Data Cloud). Многие датасеты на этой диаграмме могут включать в себя данные, защищенные авторским правом, и они не упоминаются в данной статье
Если вы прямо сейчас не делаете свой ИИ, то другие будут делать его вместо вас для себя. Ничто более не мешает вам создать систему на основе машинного обучения. Есть открытая библиотека глубинного обучения TensorFlow, большое количество алгоритмов для обучения в библиотеке Torch, фреймворк для реализации распределенной обработки неструктурированных и слабоструктурированных данных Spark и множество других инструментов, облегчающих работу.
Добавьте к этому доступность больших вычислительных мощностей, и вы поймете, что для полного счастья не хватает лишь одного ингредиента — данных. Огромное количество данных находится в открытом доступе, однако непросто понять, на какие из открытых датасетов стоит обратить внимание, какие из них годятся для проверки идей, а какие могут быть полезны в качестве средства проверки потенциальных продуктов или их свойств до того, как вы накопите собственные проприетарные данные.
Мы разобрались в этом вопросе и собрали данные по датасетам, удовлетворяющим критериям открытости, востребованности, скорости работы и близости к реальным задачам.
Визуализация результатов выборов в Москве на карте в Jupyter Notebook
11 мин
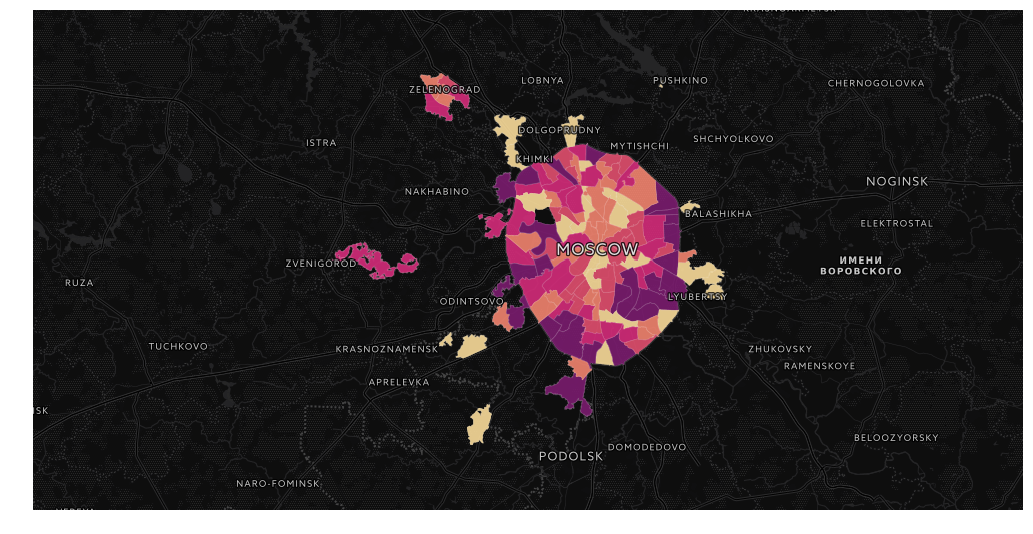
Всем привет!
Сегодня мы поговорим о визуализации геоданных. Имея на руках статистику, явно имеющую пространственную привязку, всегда хочется сделать красивую карту. Желательно, с навигацией да инфоокнами В тетрадках. И, конечно же, чтоб потом можно было показать всему интернету свои успехи в визуализации!
В качестве примера возьмем недавно отгремевшие муниципальные выборы в Москве. Сами данные можно взять с сайта мосгоризбиркома, в можно просто забрать датасеты с https://gudkov.ru/. Там даже есть какая-никакая визуализация, но мы пойдем глубже. Итак, что же у нас в итоге должно получиться?
Яндекс открывает технологию машинного обучения CatBoost
6 мин
Сегодня Яндекс выложил в open source собственную библиотеку CatBoost, разработанную с учетом многолетнего опыта компании в области машинного обучения. С ее помощью можно эффективно обучать модели на разнородных данных, в том числе таких, которые трудно представить в виде чисел (например, виды облаков или категории товаров). Исходный код, документация, бенчмарки и необходимые инструменты уже опубликованы на GitHub под лицензией Apache 2.0.

CatBoost – это новый метод машинного обучения, основанный на градиентном бустинге. Он внедряется в Яндексе для решения задач ранжирования, предсказания и построения рекомендаций. Более того, он уже применяется в рамках сотрудничества с Европейской организацией по ядерным исследованиям (CERN) и промышленными клиентами Yandex Data Factory. Так чем же CatBoost отличается от других открытых аналогов? Почему бустинг, а не метод нейронных сетей? Как эта технология связана с уже известным Матрикснетом? И причем здесь котики? Сегодня мы ответим на все эти вопросы.
CatBoost – это новый метод машинного обучения, основанный на градиентном бустинге. Он внедряется в Яндексе для решения задач ранжирования, предсказания и построения рекомендаций. Более того, он уже применяется в рамках сотрудничества с Европейской организацией по ядерным исследованиям (CERN) и промышленными клиентами Yandex Data Factory. Так чем же CatBoost отличается от других открытых аналогов? Почему бустинг, а не метод нейронных сетей? Как эта технология связана с уже известным Матрикснетом? И причем здесь котики? Сегодня мы ответим на все эти вопросы.