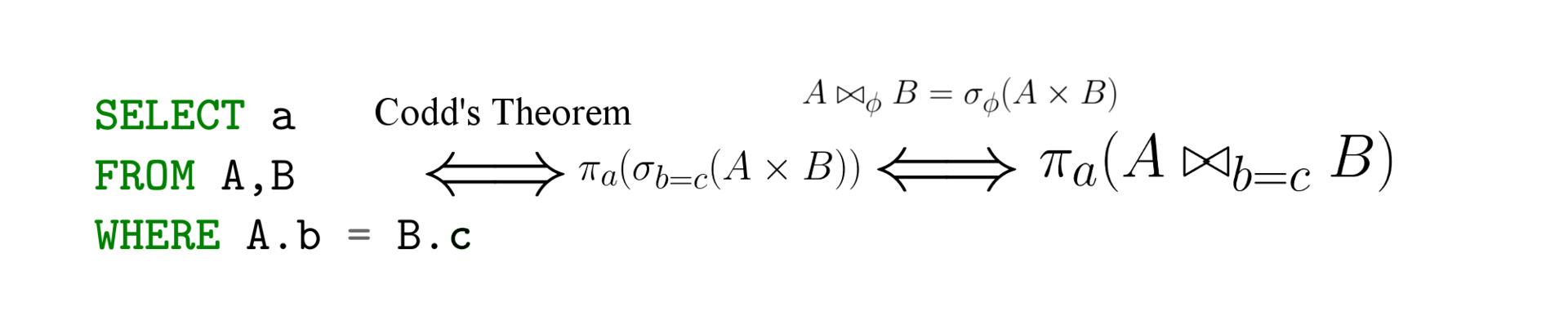В последнее время на Хабре стали чаще появляться посты о том, как хорош Telegram, как гениальны и опытны братья Дуровы в построении сетевых систем, и т.п. В то же время, очень мало кто действительно погружался в техническое устройство — как максимум, используют достаточно простой (и весьма отличающийся от MTProto) Bot API на базе JSON, а обычно просто принимают на веру все те дифирамбы и пиар, что крутятся вокруг мессенджера. Почти полтора года назад мой коллега по НПО "Эшелон" Василий (к сожалению, его учетку на Хабре стёрли вместе с черновиком) начал писать свой собственный клиент Telegram с нуля на Perl, позже присоединился и автор этих строк. Почему на Perl, немедленно спросят некоторые? Потому что на других языках такие проекты уже есть
Тем не менее, в данной серии постов будет не так много криптографии и математики. Зато будет много других технических подробностей и архитектурных костылей (пригодится и тем, кто не будет писать с нуля, а будет пользоваться библиотекой на любом языке). Итак, главной целью было — попытаться реализовать клиент с нуля по официальной документации. То есть, предположим, что исходный код официальных клиентов закрыт (опять же во второй части подробнее раскроем тему того, что это и правда бывает так), но, как в старые времена, например, есть стандарт по типу RFC — возможно ли написать клиент по одной лишь спецификации, "не подглядывая" в исходники, хоть официальных (Telegram Desktop, мобильных), хоть неофициальных Telethon?

 Хочу поделиться историей, ну и заодно услышать мнения других участников хабрасообщества. Это небольшая история о том, как агрессивное внедрение методологии разработки Agile (Scrum) в отдельно взятой российской IT компании послужило началом исхода из компании лучших разработчиков. Обычно в статьях про Agile рассказывают, какая это классная и полезная методология, и вообще — это лучшее, что было придумано в этом направлении. Возможно, эта статья поможет взглянуть на Agile с другой стороны, ведь у любой монеты, как оказалось, есть две стороны.
Хочу поделиться историей, ну и заодно услышать мнения других участников хабрасообщества. Это небольшая история о том, как агрессивное внедрение методологии разработки Agile (Scrum) в отдельно взятой российской IT компании послужило началом исхода из компании лучших разработчиков. Обычно в статьях про Agile рассказывают, какая это классная и полезная методология, и вообще — это лучшее, что было придумано в этом направлении. Возможно, эта статья поможет взглянуть на Agile с другой стороны, ведь у любой монеты, как оказалось, есть две стороны.


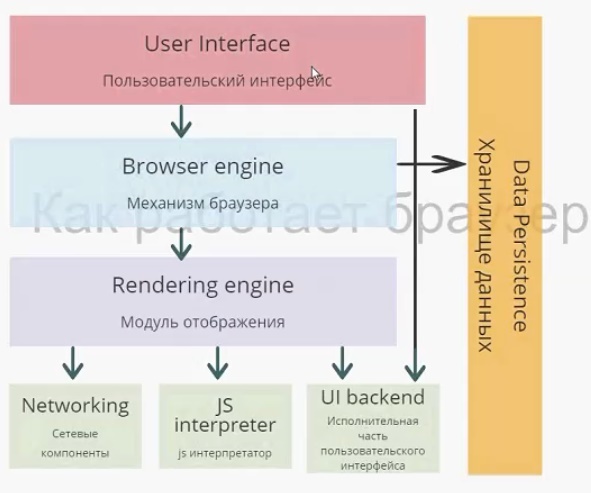




 В задаче распознавания ключевую роль играет выделение значимых параметров объектов и оценка их численных значений. Тем не менее, даже получив хорошие численные данные, нужно суметь правильно ими воспользоваться. Иногда кажется, что дальнейшее решение задачи тривиальное, и хочется «из общих соображений» получить из численных данных результат распознавания. Но результат в этом случае получается далеко не оптимальный. В этой статье я хочу на примере задачи распознавания показать, как можно легко применить простейшие математические модели и за счет этого существенно улучшить результаты.
В задаче распознавания ключевую роль играет выделение значимых параметров объектов и оценка их численных значений. Тем не менее, даже получив хорошие численные данные, нужно суметь правильно ими воспользоваться. Иногда кажется, что дальнейшее решение задачи тривиальное, и хочется «из общих соображений» получить из численных данных результат распознавания. Но результат в этом случае получается далеко не оптимальный. В этой статье я хочу на примере задачи распознавания показать, как можно легко применить простейшие математические модели и за счет этого существенно улучшить результаты.