
Цикл постов про Keycloak (часть 1): Внедрение.
О чем речь?
Это первая часть серии статей о переходе на Keycloak в качестве SSO в условиях кровавого enterprise.

Пользователь
Цикл постов про Keycloak (часть 1): Внедрение.
О чем речь?
Это первая часть серии статей о переходе на Keycloak в качестве SSO в условиях кровавого enterprise.
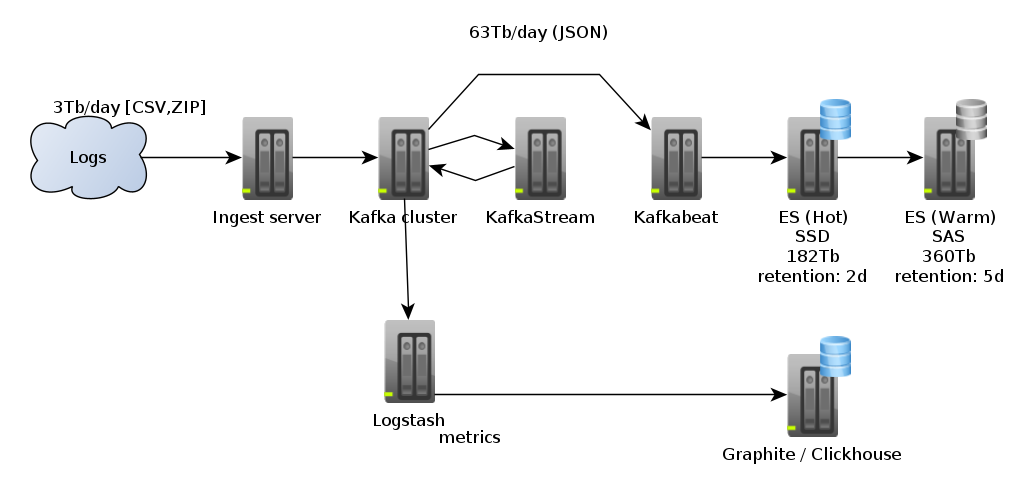
Черновик статьи был написан еще год назад, когда я работал на крупном международном проекте, но из-за разных событий прошлого года он остался неопубликованным.
На проекте в моем ведении находилось несколько on-premise кластеров в нескольких европейских датацентрах. «Мы» в этой статье — небольшая команда DataOps из 5 человек.
Было дело я читал на Хабре статью про «Кластер Elasticsearch на 200 ТБ+» и примерял написанное к нам, у нас такой кластер считался средним, самый маленький кластер под 0,1Ptb, а большой тогда был под 0,5Ptb. Потом была поставлена задача подготовить кластер к увеличению объемов входящих данных в 2-3 раза, а срок хранения в 2 раза, т. е. объем хранимых данных, если грубо экстраполировать, должен был стать в районе 2-3Ptb.
Хочу поделиться нашим опытом, может кому пригодиться.

В статье рассказываем, как оптимизировать базу данных PostgreSQL на примере Linux на IBM Z. Опираясь на представленные примеры, вы шаг за шагом узнаете, какие опции и параметры конфигурации улучшат установку PostgreSQL с точки зрения:

OOM Killer — защитный механизм ядра Linux, призванный решать проблемы с нехваткой памяти. При исчерпании доступной памяти он принудительно «убивает» наиболее подходящий по приоритетам процесс, отправляя ему сигнал KILL. Сообщение об этом отображается в /var/log/syslog (Debian/Ubuntu) или /var/log/messages (Centos/Rhel).
Иногда OOM Killer может затрагивать важные процессы, нарушая работу проекта. Как исправить это, узнали у Сергея Юдина, инженера Southbridge. Ниже подробный кейс с примерами кода.
Перечитал я трезвым взглядом свой предыдущий пост и понял, что новичкам через все эти нагромождения апдейтов и обсуждений в комментариях (которые местами были даже полезнее, чем сам пост) продираться будет затруднительно.
Поэтому здесь я приведу сжатую пошаговую инструкцию, как обходить блокировки, если у вас есть:
Если у вас нет чего-то из этого или у вас есть что-то другое или вы хотите узнать, почему так, а не иначе — добро пожаловать в предыдущий пост, где это всё описано более-менее подробно. Имейте в виду, что схемы включения и настройки в этом посте немного отличаются для упрощения решения.
Те, кто уже всё сделал по мотивам предыдущего поста, в этом полезной информации не почерпнут.

Продолжаем цикл статей об организации мониторинга. В первом материале разбирали, как и куда вообще имеет смысл навешивать алерты. Теперь поговорим о мониторинге базового серверного ПО, которое встречается в работе практически любого веб-проекта. Хочу поделиться метриками и алертами, которые мы в ITSumma используем для мониторинга виртуальных машин, docker/LXC-контейнеров, web- и application-серверов, supervisor’а, кастомных сервисов, а также ping-url’ов, SSL-сертификатов и доменных имен.

У меня возникла задача настроить отказоустойчивый Bare Metal кластер для комплексного приложения, в связи с чем и возникла данная статья. Сразу хочу сказать, что не являюсь экспертом в K8S, однако имею опыт развертывания продуктовых кластеров DC/OS (экосистемы, основанной на Apache Mesos).
Долгое время K8S меня отпугивал тем, что, при попытке его изучения, тебя закидывают кучей концепций и терминов, отчего мозг взрывается.
Ну ладно, про «полюбил» — это преувеличение. Скорее «смог сосуществовать с».
Как вы все знаете, с 16 апреля 2018 года Роскомнадзор крайне широкими мазками блокирует доступ к ресурсам в сети, добавляя в "Единый реестр доменных имен, указателей страниц сайтов в сети «Интернет» и сетевых адресов, позволяющих идентифицировать сайты в сети «Интернет», содержащие информацию, распространение которой в Российской Федерации запрещено" (по тексту — просто реестр) по /10 иногда. В результате граждане Российской Федерации и бизнес страдают, потеряв доступ к необходимым им совершенно легальным ресурсам.
После того, как в комментариях к одной из статей на Хабре я сказал, что готов помочь пострадавшим с настройкой схемы обхода, ко мне обратились несколько человек с просьбой о такой помощи. Когда у них всё заработало, один из них порекомендовал описать методику в статье. Поразмыслив, решил нарушить свое молчание на сайте и попробовать в кои-то веки написать что-то промежуточное между проектом и постом в Facebook, т.е. хабрапост. Результат — перед вами.