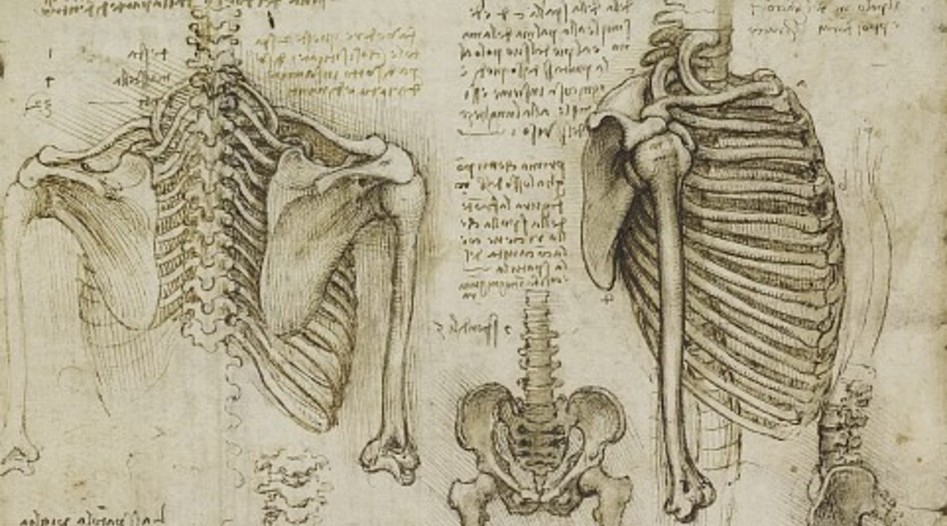
1. Вступление
Сталкиваясь с необходимостью контролировать работу других программистов, начинаешь понимать, что, помимо вещей, которым люди учатся достаточно легко и быстро, находятся проблемы, для устранения которых требуется существенное время.
Сравнительно быстро можно обучить человека пользоваться необходимым инструментарием и документацией, правильной коммуникации с заказчиком и внутри команды, правильному целеполаганию и расстановке приоритетов (ну, конечно, в той мере, в которой сам всем этим владеешь).
Но когда дело доходит собственно до кода, все становится гораздо менее однозначно. Да, можно указать на слабые места, можно даже объяснить, что с ними не так. И в следующий раз получить ревью с абсолютно новым набором проблем.
Профессии программиста, как и большинству других профессий, приходится учиться каждый день в течение нескольких лет, а, по большому счету, и всю жизнь. Вначале ты осваиваешь набор базовых знаний в объеме N семестровых курсов, потом долго топчешься по различным граблям, перенимаешь опыт старших товарищей, изучаешь хорошие и плохие примеры (плохие почему-то чаще).
Говоря о базовых знаниях, надо отметить, что умение писать красивый профессиональный код — это то, что по тем или иным причинам, в эти базовые знания категорически не входит. Вместо этого, в соответствующих заведениях, а также в книжках, нам рассказывают про алгоритмы, языки, принципы ООП, паттерны дизайна…
Да, все это необходимо знать. Но при этом, понимание того, как должен выглядеть достойный код, обычно появляется уже при наличии практического (чаще в той или иной степени негативного) опыта за плечами. И при условии, что жизнь “потыкала” тебя не только в сочные образцы плохого кода, но и в примеры всерьез достойные подражания.
В этом-то и заключается вся сложность: твое представление о “достойном” и “красивом” коде полностью основано на личном многолетнем опыте. Попробуй теперь передать это представление в сжатые сроки человеку с совсем другим опытом или даже вовсе без него.
Но если для нас действительно важно качество кода, который пишут люди, работающие вместе с нами, то попробовать все же стоит!







 Всем привет. Меня зовут Игорь Акимов, я руководитель направления мобильных продуктов ABBYY. Наверное, многие знают
Всем привет. Меня зовут Игорь Акимов, я руководитель направления мобильных продуктов ABBYY. Наверное, многие знают