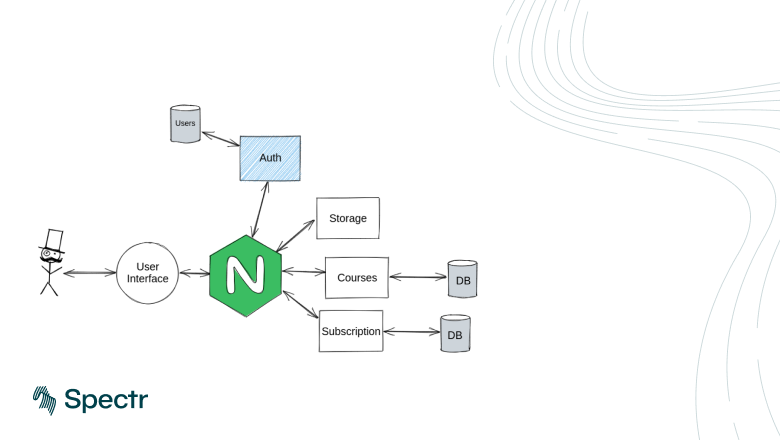
Погружение в мир контейнеризации с докером — это путь к оптимизации развёртыванию приложений, а также ключ к упрощению жизни разработчиков и системных администраторов. Меня зовут Андрей Аверков, в IT c 2008 начинал пусть с аналитика-проектировщика IT систем, 11 лет в роли разработчика и последние годы на руководящих должностях. Сейчас я тимлид команды разработки из 9 человек в группе компании Кокос. Мы занимаемся созданием и поддержкой CPA платформ (gdeslon.ru, fxpartners.ru, ads.mobisharks.com), а также проектом по генерации лендингов — lpgenerator.ru. У нас большой опыт в разделении продуктов на части, поэтому, сегодня мы собрали самое основное и необходимое для работы с Docker. В нашей шпаргалке вы найдете все необходимое для успешного старта с докером: от базовых концепций и установки до продвинутых техник работы с контейнерами.
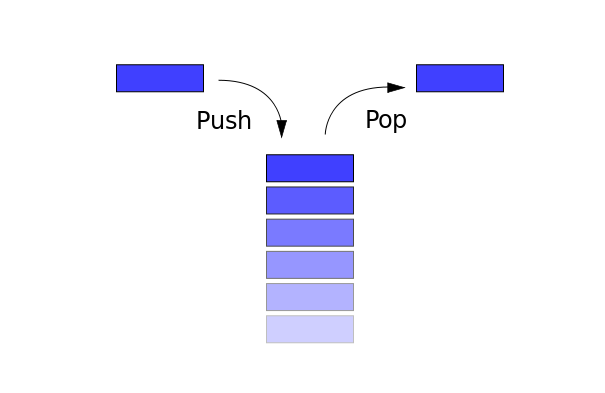
 методики FAANG — по этой причине практически во всех IT-собесах есть она: секция алгоритмов. Кто-то ей рад, кто-то не очень, но секция есть и уходить пока не планирует. Поэтому нужно закатать рукава и достойно встретить суровую реальность.
методики FAANG — по этой причине практически во всех IT-собесах есть она: секция алгоритмов. Кто-то ей рад, кто-то не очень, но секция есть и уходить пока не планирует. Поэтому нужно закатать рукава и достойно встретить суровую реальность.