Сегодня замечательный день (if you know what I mean), чтобы анонсировать нашу новую программу —
Специалист по разметке данных.
На текущий момент в сфере искусственного интеллекта сложилась такая ситуация, при которой для обучения сильной нейронной сети нужны несколько компонентов: железо, софт и, непосредственно, данные. Много данных.
Железо, в общем-то, доступно каждому через облака. Да, оно может быть недешевым, но GPU-инстансы на EC2 вполне по карману большинству исследователей. Софт опенсорсный, большинство фреймворков можно скачать себе куда-то и работать с ними. Некоторые сложнее, некоторые проще. Но порог для входа вполне приемлемый. Остается только последний компонент — это данные. И вот здесь и возникает загвоздка.
Deep learning требует действительно больших данных: сотни тысяч–миллионы объектов. Если вы хотите заниматься, например, задачей классификации изображений, то вам, помимо самих данных, нужно передать нейронке информацию, к какому классу относится тот или иной объект. Если у вас задача связана еще и с сегментацией изображения, то получение хорошего датасета — это уже фантастически сложно. Представьте, что вам нужно на каждом изображении выделить границы каждого объекта.
В этом посте хочется сделать обзор тех инструментов (коммерческих и бесплатных), которые пытаются облегчить жизнь этих прекрасных людей — разметчиков данных.

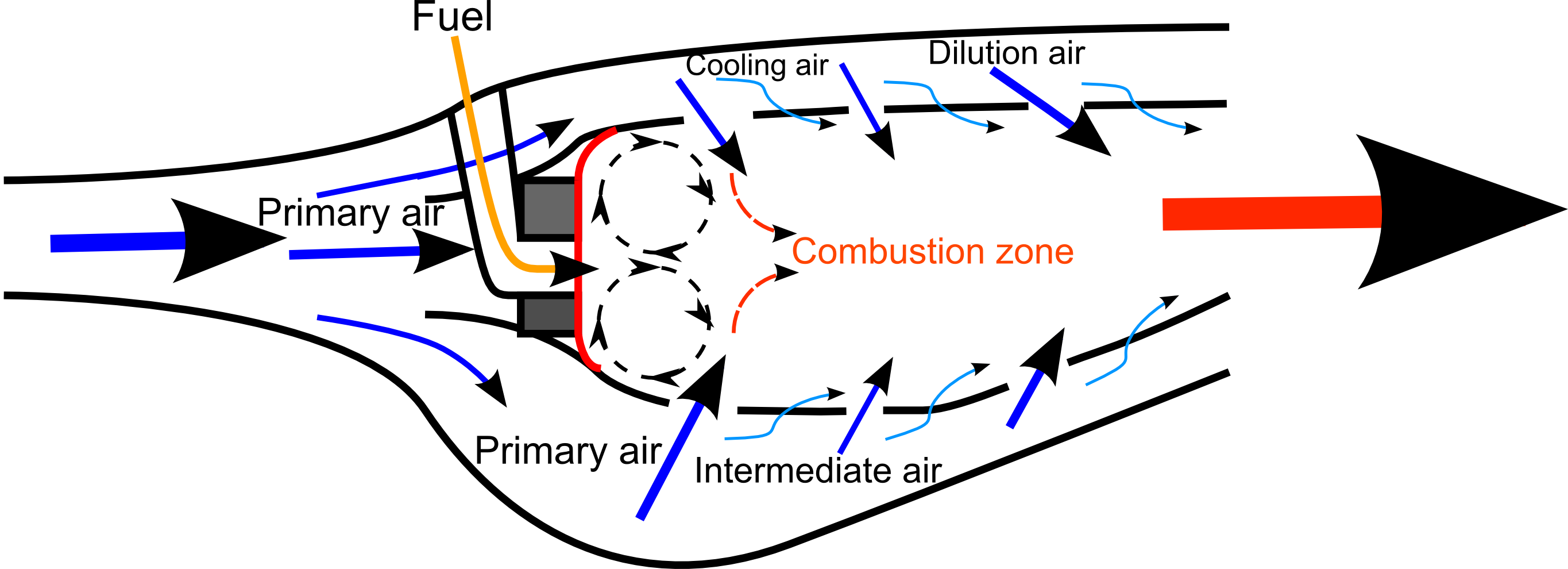













{kind=link}