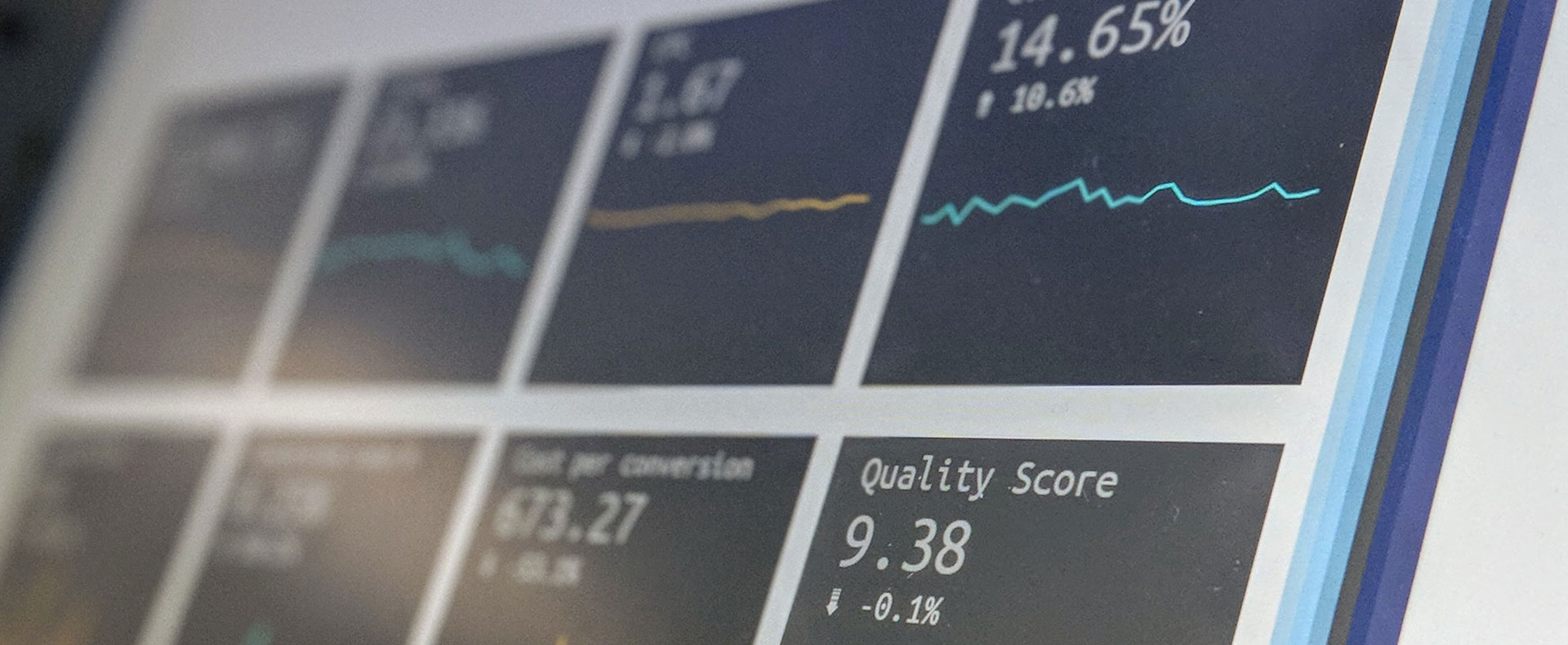
Уважаемые коллеги, всем доброго дня.
В данной статье хочу поделиться собственным опытом знакомства с MDM решением компании Юнидата (UniData). Попытаюсь сделать акцент на конкретные трудности и особенности платформы, с которыми столкнулся при переходе с SAP MDM на ЮниДата MDM.
Предыстория проекта
К моменту старта проекта по переходу на UniData MDM в Компании уже примерно 5 лет функционировала корпоративная система управления нормативно-справочной информацией (КСУ НСИ) на базе SAP MDM. Проект внедрения SAP MDM был по-настоящему успешным и эксплуатация системы практически не создавала проблем.
В КСУ НСИ велись два общекорпоративных справочника:
- материально-технических ресурсов, работ и услуг (МТРиУ), 200000 записей
- контрагентов, 40000 записей
Применялась модель централизованного ведения НСИ с единой точкой ввода через механизм заявок от пользователей. MDM выступал мастер-системой для ряда информационных систем Дочерних обществ, обслуживающих различные бизнес-процессы (бухгалтерский и налоговый учет, планирование и централизованные закупки, техническое обслуживание и ремонт оборудования и другие).
Конфигурация системы включала в себя портал (тонкий клиент, GUI) для работы с заявками пользователей, толстый клиент для настройки модели данных и других операций, специализированный инструментарий для экспорта и импорта данных и другие компоненты.
В системе была реализована достаточно сложная модель ведения данных, большой атрибутивный состав справочников. Система классификации и кодирования состояла из иерархических и фасетно-иерархических (онтологических) классификаторов и их связей (мэппинг), для записей было предусмотрено кодирование по системе свойств и значений, развит инструментарий в части управления качеством данных.
В целом состав данных и функционал системы можно назвать достаточно типовым для крупного бизнеса в сфере промышленного производства.
В силу разных причин перед Компанией встала задача импортозамещения системы SAP MDM с полным сохранением существующей функциональности.