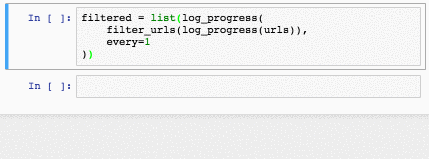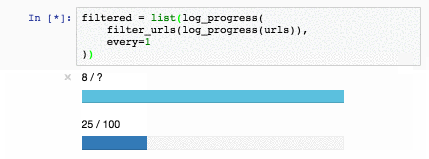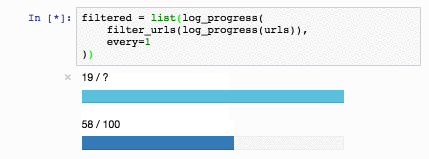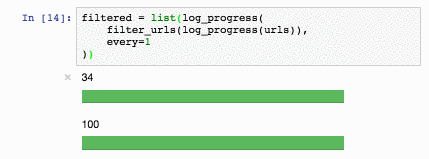
Речь пойдет о технологии, которая дает возможность реализации инструментов разработчика, подобных показанному на картинке ниже.
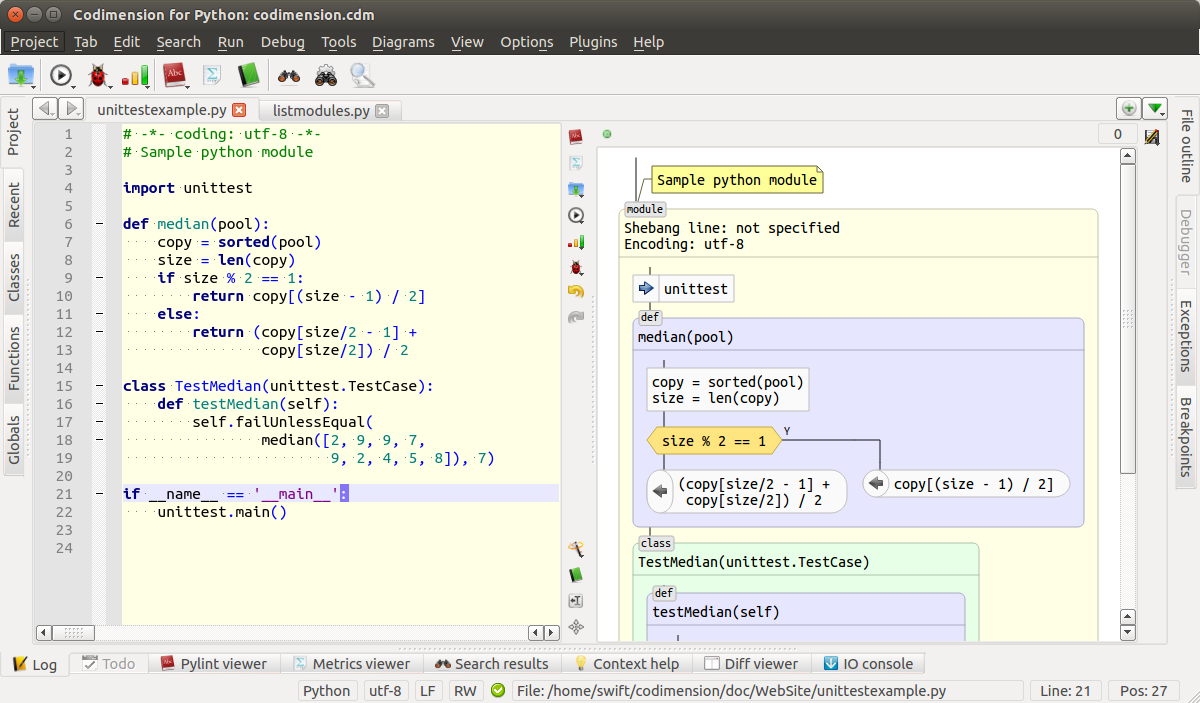
Общий вид среды с альтернативными представлениями кода
Здесь окно среды разработки разбито на две части. Слева — привычный текстовый редактор, а справа — автоматически генерируемая диаграмма, по возможности приближенная к традиционным блок-схемам алгоритмов. Генерация и перерисовка диаграммы производится по ходу набивки текста. Среда разработки определяет паузу в действиях разработчика и обновляет диаграмму, если код остается корректным. В результате появляется возможность работы не только с текстом программы, но и с его графическим представлением.
Общий вид среды с альтернативными представлениями кода
Здесь окно среды разработки разбито на две части. Слева — привычный текстовый редактор, а справа — автоматически генерируемая диаграмма, по возможности приближенная к традиционным блок-схемам алгоритмов. Генерация и перерисовка диаграммы производится по ходу набивки текста. Среда разработки определяет паузу в действиях разработчика и обновляет диаграмму, если код остается корректным. В результате появляется возможность работы не только с текстом программы, но и с его графическим представлением.



 Кто не любит эмодзи? Активно используя их в мессенджерах и почтовых приложениях, я решил проэкспериментировать с тем, как можно применить их с умом в повседневной разработке приложений. Хотя поначалу это была просто шутка, эмодзи действительно оказались полезными в ряде случаев. Как так?
Кто не любит эмодзи? Активно используя их в мессенджерах и почтовых приложениях, я решил проэкспериментировать с тем, как можно применить их с умом в повседневной разработке приложений. Хотя поначалу это была просто шутка, эмодзи действительно оказались полезными в ряде случаев. Как так?