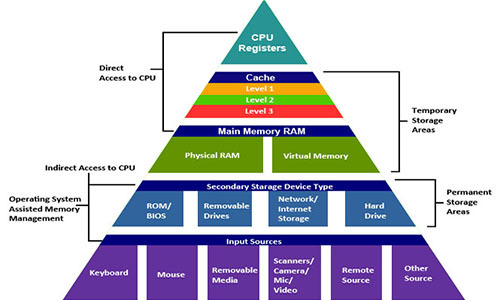
Для начала несколько вопросов:
Разумеется, экспериментально искать ответы на эти вопросы с помощью вашего любимого компилятора в вашей любимой системе на вашем любимом компьютере1) — не лучшая идея. Мы говорим о стандарте языка (С99 и новее).
Если вы уверенно сможете правильно ответить на эти вопросы, тогда эта статья не для вас. В противном случае десять минут, потраченные на её чтение, будут весьма полезны.
- Тип
charпо умолчанию знаковый или нет? Аint? - Законно ли неявное приведение
(signed char *)к(char *)? А то же дляint? - Сколько бит в
unsigned char? - Какое максимальное число гарантированно можно поместить в
int? А минимальное? - Тип
longопределённо больше, чемchar, не так ли?
Разумеется, экспериментально искать ответы на эти вопросы с помощью вашего любимого компилятора в вашей любимой системе на вашем любимом компьютере1) — не лучшая идея. Мы говорим о стандарте языка (С99 и новее).
Если вы уверенно сможете правильно ответить на эти вопросы, тогда эта статья не для вас. В противном случае десять минут, потраченные на её чтение, будут весьма полезны.
Предположу, что вы ответили
- Знаковые оба.
- Законны оба.
- 8.
- 2147483647. -2147483648.
- Конечно, Кэп.
А правильные ответы такие
char— не регламентируется,int— знаковый.- Для
int— законно, а дляchar— нет. - Не менее 8.
- 32767. -32767
- Вообще говоря, нет.





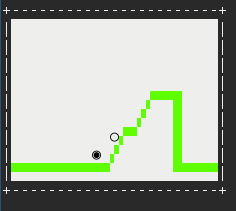 Итак, эта статья посвящается тем, кто любит решать нестандартные задачи на не предназначенных для этого инструментах. Здесь я опишу основные проблемы, с которыми столкнулся во время создания аналога игры Gravity defied с использованием потокового текстового редактора (sed).
Итак, эта статья посвящается тем, кто любит решать нестандартные задачи на не предназначенных для этого инструментах. Здесь я опишу основные проблемы, с которыми столкнулся во время создания аналога игры Gravity defied с использованием потокового текстового редактора (sed).