
Интро
К сожалению, большая часть работы тимлида скрыта от команды. И в зависимости от многочисленных факторов, таких как размер команды, выстроенные процессы, наличие других ролей, занимающихся работой с командой — она еще и невероятно размыта. Список твоих обязанностей в разных компаниях будет отличаться. Где-то это просто формальная должность человека, который просто перетаскивает задачи из одного статуса в другой в свободное время от написания кода, в другой — это полноценная роль, где придется отложить в сторону свою любимую IDE и заняться кучей других обязанностей. Кстати, очень часто эту роль совмещают с еще одной ролью, техлида, и далеко не всегда это плохо.
Но один момент не меняется — если ты стал тимлидом, в твоей жизни изменится многое, если этого не произошло, это первый знак, говорящий о том, что ты явно не справляешься со своими обязанностями (либо это звание носит сугубо формальный характер).
Если ты никогда раньше этим не занимался, тебе предстоит свой долгий и тернистый путь с огромным количеством разбросанных граблей, на которые тебе придется наткнуться и без поддержки команды, увы, этот путь преодолеть будет невозможно.








 В свое время, в 1995-ом году, на меня произвел впечатление фильм «Хакеры». Можно
В свое время, в 1995-ом году, на меня произвел впечатление фильм «Хакеры». Можно



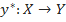 , значения которой известны только на объектах конечной обучающей выборки
, значения которой известны только на объектах конечной обучающей выборки 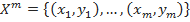 . Требуется построить алгоритм
. Требуется построить алгоритм 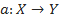 , способный классифицировать произвольный объект x∈X. Однако более распространенным является вероятностная постановка задачи. Пусть X — множество описаний объектов, Y — множество номеров (или наименований) классов. На множестве пар «объект, класс» X×Y определена вероятностная мера P. Имеется конечная обучающая выборка независимых наблюдений
, способный классифицировать произвольный объект x∈X. Однако более распространенным является вероятностная постановка задачи. Пусть X — множество описаний объектов, Y — множество номеров (или наименований) классов. На множестве пар «объект, класс» X×Y определена вероятностная мера P. Имеется конечная обучающая выборка независимых наблюдений