За последний год я сталкивалась с необходимостью рисования гистограмм и столбчатых диаграмм достаточно часто для того, чтобы появилось желание и возможность об этом написать. Кроме того, мне самой довольно сильно не хватало подобной информации. В этой статье приведен обзор 3 методов создания таких графиков на языке Python.
Начнем с того, чего я сама по своей неопытности не знала очень долго: столбчатые диаграммы и гистограммы — разные вещи. Основное отличие состоит в том, что гистограмма показывает частотное распределение — мы задаем набор значений оси Ox, а по Oy всегда откладывается частота. В столбчатой диаграмме (которую в англоязычной литературе уместно было бы назвать barplot) мы задаем и значения оси абсцисс, и значения оси ординат.
Для демонстрации я буду использовать избитый набор данных библиотеки scikit learn Iris. Начнем c импортов:
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from sklearn import datasets
iris = datasets.load_iris()
Преобразуем набор данных iris в dataframe — так нам удобнее будет с ним работать в будущем.
data = pd.DataFrame(data= np.c_[iris['data'], iris['target']], columns= iris['feature_names'] + ['target'])
Из интересующих нас параметров data содержит информацию о длине чашелистиков и лепестков и ширине чашелистиков и лепестков.
Используем Matplotlib
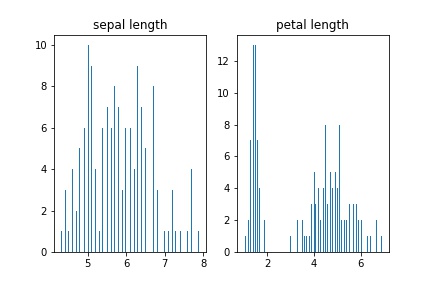
Построение гистограммы
Cтроим обычную гистограмму, показывающую частотное распределение длин лепестков и чашелистиков:
fig, axs = plt.subplots(1, 2)
n_bins = len(data)
axs[0].hist(data['sepal length (cm)'], bins=n_bins)
axs[0].set_title('sepal length')
axs[1].hist(data['petal length (cm)'], bins=n_bins)
axs[1].set_title('petal length')