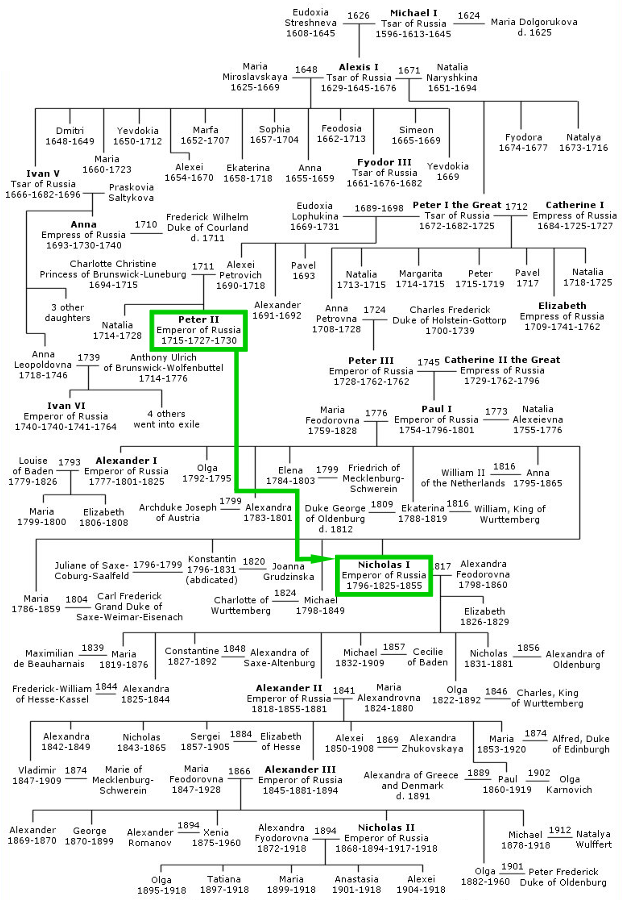
Программа, способная к логическим выводам в рамках поставленной задачи, может казаться техническим чудом и воплощением Скайнета. Но, как можно убедиться ниже, на сегодняшний день создать такую программу на языке Python не составит труда, если использовать семантические технологии. Мы остановимся на наглядном примере онтологий — родословных — и для любого члена семьи в родословной сможем выводить его родственные отношения произвольной сложности (она ограничена вычислительными ресурсами). К примеру, на фамильном древе семьи Романовых ниже показан внучатый двоюродный племянник (first cousin twice removed) российского императора Петра II.
Так что если вы хотите познакомиться с технологиями семантического веба на практике, добро пожаловать под кат, где мы потренируемсяна кошках на родословных.
Так что если вы хотите познакомиться с технологиями семантического веба на практике, добро пожаловать под кат, где мы потренируемся

 Лисп часто рекламируют как язык, имеющий преимущества перед остальными из-за того, что он обладает некоторыми уникальными, хорошо интегрированными и полезными фичами.
Лисп часто рекламируют как язык, имеющий преимущества перед остальными из-за того, что он обладает некоторыми уникальными, хорошо интегрированными и полезными фичами.