Приветствую, это вторая заметка о Spring Data JPA. Первая часть была целиком посвящена подводным граблям, а также советам бывалых. В этой части мы поговорим о том, как заточить фреймворк под свои нужды. Все описанные примеры доступны здесь.

mik @mik
Пользователь
Spring Data JPA: что такое хорошо, и что такое плохо
13 мин
Крошка-сын к отцу пришел
И спросила кроха
— Что такое хорошо
и что такое плохо
Владимир Маяковский
Эта статья о Spring Data JPA, а именно в подводных граблях, встретившихся на моём пути, ну и конечно же немного о производительности.
Как мы мигрировали критичную БД с Oracle в CockroachDB
6 мин
… простите, мигрировали куда? Туда!
CockroachDB — PostgreSQL-совместимая (по SQL-синтаксису DML) распределенная СУБД с открытым кодом (ну, почти). Ее название символизирует, что она, как таракан, выживает в любых экстремальных ситуациях. Лично мне крайне импонирует такая СУБД с привычным SQL-интерфейсом, настройка которой занимает 5 минут, которая хранит данные — как Kafka — на нескольких узлах в нескольких ЦОДах сразу, имеет настраиваемый replication factor на уровне конкретных таблиц, легко переживает потерю как одного узла, так и целого ЦОДа, использует для этого механизм распределенного консенсуса Raft и при этом еще и имеет строгую консистентность и уровень изоляции serializable. Разработчики CockroachDB — выходцы из компании Google, которые решили коммерциализировать архитектуру распределенной СУБД Spanner.

Недостатки тоже есть, не переживайте, но про них лучше в другой раз :)
Почему именно CockroachDB?
Среди распределенных SQL-СУБД есть альтернативы в виде Yugabyte и TiDB, и с прошлого месяца YDB. Вопрос «Почему?» связан в первую очередь с тем, зачем вообще нужна БД. Как мне кажется, БД нужна для того, чтобы надежно хранить данные и доставать их через стандартный язык SQL, а удобство ее использования — приятный, но вторичный фактор. Тут надо заметить, что я почти 9 лет проработал в техподдержке Oracle, и видел достаточно случаев порчи БД, как из-за дисковых сбоев и ошибок администраторов, так и из-за багов в приложении и даже в коде самой СУБД.
Ключевыми критериями выбора были:
«Ленивый сахар» PostgreSQL
7 мин

SQL - декларативный язык - то есть вы описываете "что" хотите получить, а СУБД сама решает, "как" именно она будет это делать. Некоторые из них при этом позволяют им "подсказывать", как именно лучше выполнять запрос, но PostgreSQL - нет.
Тем не менее, "синтаксический сахар" некоторых языковых конструкций позволяет не только писать меньше кода (учите матчасть!), но и добиться, что ваша база будет делать часть вычислений "лениво", только при фактической необходимости.
Как мы построили корпоративную шину данных на Kafka, которая обрабатывает до 3 млн сообщений в секунду
10 мин

Привет! Меня зовут Иван Гаас, я руковожу автоматизацией процессов разработки в Почтатехе — компании, создающей цифровые продукты для Почты России.
Среднее количество сообщений, которые мы обрабатываем в Почте — от 500 тысяч до миллиона в секунду. В пики, когда наша big data прогоняет свои 25 петабайт данных — до 3 миллионов. При этом кластер Kafka состоит всего из 12 серверов в каждом из 3 дата-центров и справляется с этим.
C 2016 года мы в три раза увеличили количество новых цифровых сервисов. Корпоративная шина на Kafka помогла быстро масштабироваться: количество интеграций за последнее время упало с 1000 до 300 и теперь растёт незначительно. Если раньше интеграция сервиса растягивалась на месяцы, то теперь достаточно нескольких дней.
Я расскажу, как мы построили шину, которая обеспечивает такую производительность.
Как работает оптимизатор PostgreSQL при большом количестве таблиц в запросе
9 мин
SQL — это декларативный язык программирования, используемый для создания и манипулирования объектами в реляционных СУБД. Этот язык описывает что должно быть получено, но не описывает как это получить. Программист пишет запрос и (чаще всего) хочет получить результат от СУБД максимально быстро.
Работу по нахождению самого лучшего способа получения требуемых данных выполняет планировщик (он же оптимизатор) запросов. Он выбирает способы соединения наборов строк и их обработки, строит различные планы выполнения запроса и находит среди них наилучший, для чего используется стоимостная модель оптимизации.
Поэтому оптимизатор — это ключевая часть СУБД, один из самых сложных элементов всей системы.
Для демонстрации работы оптимизатора практически во всех наших (и чужих) примерах на эту тему используются довольно скромные параметры: две-три таблицы, пара JOIN-ов, миллисекунды на выполнение запросов. А что будет, если загрузить оптимизатор десятками таблиц за раз? Как разные конфигурационные параметры влияют на производительность запросов с сотней JOIN-ов? И переживет ли это среднестатистический рабочий ноутбук? Ответы на эти вопросы — со схемами и графиками — вы найдете под катом!
Работу по нахождению самого лучшего способа получения требуемых данных выполняет планировщик (он же оптимизатор) запросов. Он выбирает способы соединения наборов строк и их обработки, строит различные планы выполнения запроса и находит среди них наилучший, для чего используется стоимостная модель оптимизации.
Поэтому оптимизатор — это ключевая часть СУБД, один из самых сложных элементов всей системы.
Для демонстрации работы оптимизатора практически во всех наших (и чужих) примерах на эту тему используются довольно скромные параметры: две-три таблицы, пара JOIN-ов, миллисекунды на выполнение запросов. А что будет, если загрузить оптимизатор десятками таблиц за раз? Как разные конфигурационные параметры влияют на производительность запросов с сотней JOIN-ов? И переживет ли это среднестатистический рабочий ноутбук? Ответы на эти вопросы — со схемами и графиками — вы найдете под катом!
Гайд по архитектуре приложений для Android. Часть 1: обзор
7 мин
Перевод

Перевод обновлённого гайда Android по архитектуре приложений. Это — первая часть из пяти: обзор рекомендаций по архитектуре.
Распределённые транзакции Kafka + PostgreSQL средствами Spring
9 мин

Как известно, во многих IT-проектах есть типичная задача - транзакционная обработка данных в интеграционных сценариях, когда необходимо согласованно отправить или принять данные из внешней системы и при этом обновить собственное состояние приложения.
Особенно интересной эта задача становится, когда для интеграции используется Kafka, так как она имеет свои ограничения, касающиеся реализации транзакционности. Вообще, сейчас Kafka достаточно широко применяется именно в качестве платформы для асинхронной интеграции, это справедливо и для проектов, которые мы в ЛАНИТ — Би Пи Эм реализуем, например, в Альфа-Банке и ВТБ. Поэтому, надеемся, данная тема будет интересна многим.
В этой статье рассмотрим подход к реализации распределённых транзакций (в рамках одного Java-приложения), которые охватывают Kafka и реляционную СУБД. Для этого воспользуемся средствами управления транзакциями, имеющимися в Spring.
Варианты с организацией eventual consistency с помощью типовых паттернов (Saga, Transactional Outbox и др.) и/или использования дополнительных платформ (Debezium, Kafka Connect и пр.) - тема для отдельной статьи (так что ждите продолжения). В этой статье тему затрагивать не будем.
Пока, ФИАС! Рассказываем, как устроен адресный справочник ГАР
10 мин

1 сентября 2021 года ФНС перестала обновлять свой адресный справочник в формате ФИАС. Относительно новый ГАР внезапно стал единственным государственным адресный реестром, доступным общественности. Рассказываем, что из себя представляет новый справочник и чем он отличается от ФИАС.
Почему следует избегать использования JPA/Hibernate в продакшене
11 мин
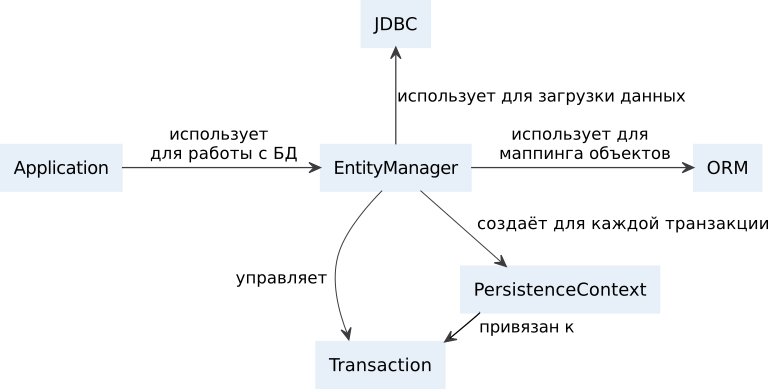
JPA безусловно самая распространённая технология работы с базами данных на платформе Java. Но она же и наименее пригодна для разработки быстрых и поддерживаемых систем. В этой статье я расскажу почему JPA лучше не использовать в продакшене и что можно использовать вместо неё.
Чистые транзакции в гексагональном Go
9 мин
В современной микросервисной разработке очень популярна чистая архитектура (она же луковая). Этот подход ясно отвечает на много архитектурных вопросов, а также хорошо подходит для сервисов с небольшой кодовой базой. Другая приятная особенность чистой архитектуры состоит в том, что она отлично сочетается с Domain Driven Development — они отлично дополняют друг друга.
Одной из прикладных реализаций чистой архитектуры является гексагональная архитектура — подход, явно выделяющей слои, адаптеры и прочее. Данный подход заслуженно сыскал любовь среди разработчиков на Go — он не требует сложных абстракций или зубодробительных паттернов, а также почти ни в чем не противоречит сложной идиоматике языка — так называемому Go way.
Но есть проблема, которую я часто вижу во многих командах, адаптирующих гексагоны, и с которой я сам столкнулся и успешно решил — реализация транзакций базы данных в рамках DDD и пресловутого гексагона. Что у меня вышло я и расскажу в этой заметке.
5 трендов баз данных. Идеи с конференции VLDB’21
13 мин

В середине августа мы приняли участие в международной научной конференции VLDB (Very Large Data Bases), и хотим поделиться актуальными идеями о работе с базами данных.
Если вы специалист по базам данных, или так или иначе связаны с ними, то приглашаем к чтению.
Запросы в PostgreSQL: 7. Сортировка и слияние
21 мин
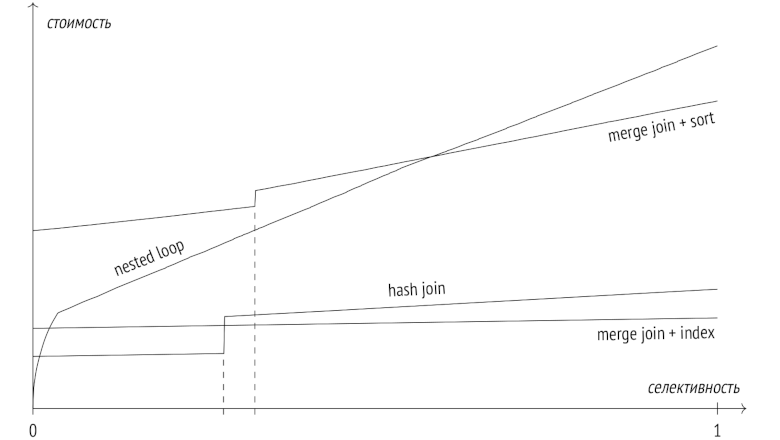
В предыдущих статьях я писал про этапы выполнения запросов, про статистику, про два основных вида доступа к данным — последовательное сканирование и индексное сканирование, — и успел рассказать о двух способах соединения — вложенном цикле и соединении хешированием.
В заключительной статье этой серии я расскажу про алгоритм слияния и про сортировку, и сравню все три алгоритма соединения между собой.
Что такое Spring Framework? От внедрения зависимостей до Web MVC
41 мин
Туториал
Перевод

Вы можете использовать это руководство для различных целей:
- Чтобы понять, что такое Spring Framework
- Как работают ее основные фичи: такие как внедрение зависимостей или Web MVC
- Это также исчерпывающий FAQ (Перечень часто задаваемых вопросов)
Примечание: Статья ~ 9000 слов, вероятно, не стоит читать ее на мобильном устройстве. Добавьте ее в закладки и вернитесь позже. И даже на компьютере ешь читай этого слона по одному кусочку за раз :-)
Содержание
- Введение
- Основы внедрения зависимостей
- Контейнер Spring IOC / Dependency Injection
- Spring AOP (Аспектно-ориентированное программирование) и прокси
- Управление ресурсами Spring
- Spring Web MVC
- Дополнительные модули Spring Framework
- Spring Framework: часто задаваемые вопросы
- Заключение
Keycloak интеграция со Spring Boot и Vue.js для самых маленьких
22 мин
Туториал
Вы больше не можете создать сервер авторизации с помощью @EnableAuthorizationServer, потому что Spring Security OAuth задеприкейтили, а проект Spring Authorization Server всё ещё экспериментальный? Выход есть! Напишем авторизацию своими руками... Что?.. Нет?.. Не хочется? И вообще получаются какие-то костыли и велосипеды? Ну ладно, тогда давайте возьмём уже что-то готовое. Например, Keycloak.
Хорошие новости для тех, кто всё ещё использует row-level локи в PostgreSQL
10 мин

Для организации совместного доступа к данным в PostgreSQL программисты часто использую row-level локи. В статье поговорим об оверхеде, который получается от такого подхода и какие есть альтернативы. Давайте посмотрим, как можно поторопить слона!
Как научиться разработке на Python: новый видеокурс Яндекса
6 мин
Туториал
 Осенью прошлого года в московском офисе Яндекса прошла первая Школа бэкенд-разработки. Мы сняли занятия на видео и сегодня рады поделиться на Хабре полным видеокурсом Школы. Он позволит вам научиться промышленной разработке на Python. Авторы лекций — опытные разработчики в Яндексе. К каждому видео приложены ссылки на примеры и полезные материалы.
Осенью прошлого года в московском офисе Яндекса прошла первая Школа бэкенд-разработки. Мы сняли занятия на видео и сегодня рады поделиться на Хабре полным видеокурсом Школы. Он позволит вам научиться промышленной разработке на Python. Авторы лекций — опытные разработчики в Яндексе. К каждому видео приложены ссылки на примеры и полезные материалы.Для изучения курса нужно знать основы Python и понимать, как приложения развёртываются на серверах. Мы ждём, что вы умеете делать запросы к базам данных и знаете, как создаются веб‑приложения, — хотя бы на начальном уровне.
Лекции Технополиса. Проектирование высоконагруженных систем (осень 2017)
5 мин

Мы начинаем публиковать курсы лекций Технополиса — образовательного проекта команды Одноклассников в Санкт-Петербургском Политехническом университете Петра Великого. Создание высоконагруженных приложений — это не только проектирование и написание кода, но и огромное количество других аспектов на всём протяжении жизненного цикла продукта. Мы пройдём по всему процессу создания и использования высоконагруженной системы. Особое внимание будет уделено особенностям эксплуатации, сетям, балансировке нагрузки, иерархии памяти, повседневным инструментам. Также поговорим о мониторинге, аудите и многом другом. Лекции курса читает команда экспертов под руководством ведущего разработчика в Одноклассниках Вадима Цесько.
Список лекций:
- Введение (Вадим Цесько incubos)
- Типовые архитектуры (Александр Христофоров)
- Эксплуатация (Илья Щаников)
- Сетевой стек (Дмитрий Самсонов dmitrysamsonov)
- Балансировка (Андрей Домась)
- Процессоры и память (Алексей Горбов)
- Хранилища данных (Сергей Егоричев)
- JVM (Андрей Паньгин apangin)
- Мониторинг (Сергей Шарапов Sharapoff)
- Облака (Леонид Талалаев)
Профилирование PL/SQL кода при помощи IDE PL/SQL Developer
2 мин
Проблематика и назначение:
Периодически Oracle разработчики сталкиваются с проблемой производительности PL/SQL кода. Возникают проблемы с тем, чтобы найти место pl/sql кода, в котором возникают проблемы.
Обычно профилирование pl/sql кода используется, когда необходимо определить проблему производительности в очень большом методе, либо когда у метода много внутренних зависимостей с большим количеством логики, а также нет понимание в каком месте метод код тормозит.
Методы решения проблемы:
В решение проблем с производительность в БД Oracle нам помогут:
- PL/SQL Developer — Популярное IDE для Oracle разработчиков.
- DBMS_PROFILE — Oracle пакет для профилирования (не будет рассматриваться в рамках данной статьи, т.к. информации достаточно на просторах интернета).
Руководство по alt-text от слабовидящего веб-разработчика
7 мин
Перевод
Эта статья содержит всё, что вам нужно знать об alt-text! Когда их использовать и как идеально их подготовить. Подготовил я, Дэниель, веб-разработчик с частичной потерей зрения, который ежедневно использует скринридер.

Во время сёрфинга в вебе я использую сочетание увелителя экрана и скринридера. Как показывает практика, увеличение экрана удобнее на дисплеях большого размера, а скринридер — на меньших устройствах.
Мой опыт с картинками в вебе
Во время сёрфинга в вебе я использую сочетание увелителя экрана и скринридера. Как показывает практика, увеличение экрана удобнее на дисплеях большого размера, а скринридер — на меньших устройствах.