Грамотное владение shell — один из самых важных навыков, которыми вы как программист должны обладать. Unix shell — одна из самых мощных идей, реализованных в коде, и она должна стать вашей второй натурой. Ни один другой инструмент и близко не сравним с возможностью быстрого выполнения сложных задач или с сохранением этих команд в виде скриптов.
В своей работе я использую Vim в качестве редактора, а Unix — в качестве «IDE». Я не модифицирую свой vimrc, чтобы добавить в него функции IDE; самый важный плагин, который использую ежедневно — это Ctrl+P, и он нужен мне только для упрощения открытия файлов. Грамотное владение Vim — ценный навык, но важно понимать, когда от него нужно отказаться. В своей повседневной работе я взаимодействую с несколькими терминалами: обычно в одном из них есть Vim, второй используется для запуска сборок или демонов, а в третьем запущен shell, способный выполнить любые мои команды.
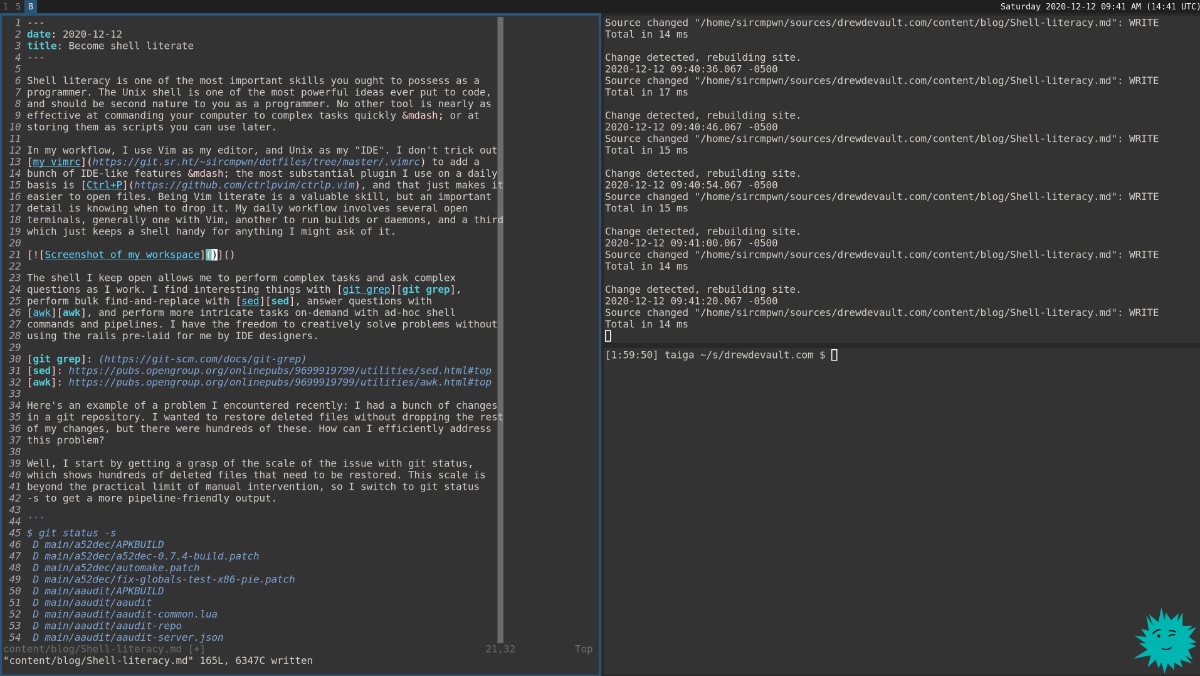
Постоянно открытый shell позволяет мне выполнять сложные задачи и отвечать на сложные вопросы. Интересные вещи я нахожу при помощи git grep, масштабные операции поиска и замены я выполняю через sed, отвечаю на вопросы с помощью awk, а более тонкие задачи я выполняю создаваемыми по ходу работы командами и конвейерами shell. Я обладаю свободой творческого решения задач без ограничений, заложенных проектировщиками IDE.
В своей работе я использую Vim в качестве редактора, а Unix — в качестве «IDE». Я не модифицирую свой vimrc, чтобы добавить в него функции IDE; самый важный плагин, который использую ежедневно — это Ctrl+P, и он нужен мне только для упрощения открытия файлов. Грамотное владение Vim — ценный навык, но важно понимать, когда от него нужно отказаться. В своей повседневной работе я взаимодействую с несколькими терминалами: обычно в одном из них есть Vim, второй используется для запуска сборок или демонов, а в третьем запущен shell, способный выполнить любые мои команды.
Постоянно открытый shell позволяет мне выполнять сложные задачи и отвечать на сложные вопросы. Интересные вещи я нахожу при помощи git grep, масштабные операции поиска и замены я выполняю через sed, отвечаю на вопросы с помощью awk, а более тонкие задачи я выполняю создаваемыми по ходу работы командами и конвейерами shell. Я обладаю свободой творческого решения задач без ограничений, заложенных проектировщиками IDE.


  называют функциональный ряд вида
 называют функциональный ряд вида