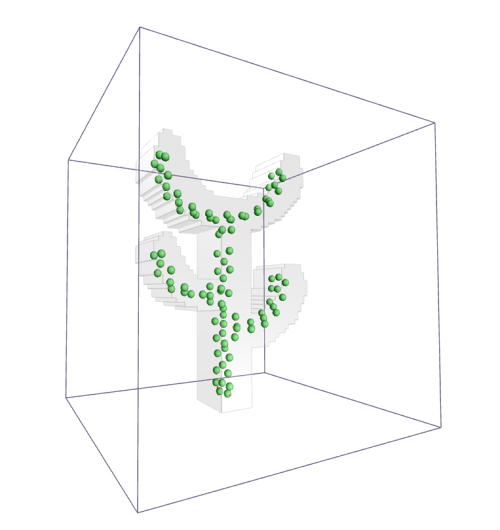
Привет, Хабр!
Три года назад на сайте Леонида Жукова я ткнул ссылку на курс Юре Лесковека cs224w Analysis of Networks и теперь мы будем его проходить вместе со всеми желающими в нашем уютном чате в канале #class_cs224w. Cразу же после разминки с открытым курсом машинного обучения, который начнётся через несколько дней.

Вопрос: Что там начитывают?
Ответ: Современную математику. Покажем на примере улучшения процесса IT-рекрутинга.
Под катом читателя ждёт история о том, как руководителя проектов дискретная математика до нейросетей довела, почему внедряющим ERP и управляющим продуктами стоит почитывать журнал Биоинформатика, как появилась и решается задача рекомендации связей, кому нужны графовые эмбеддинги и откуда взялись, а также мнение о том, как перестать бояться вопросов про деревья на собеседованиях, и чего всё это может стоить. Погнали!
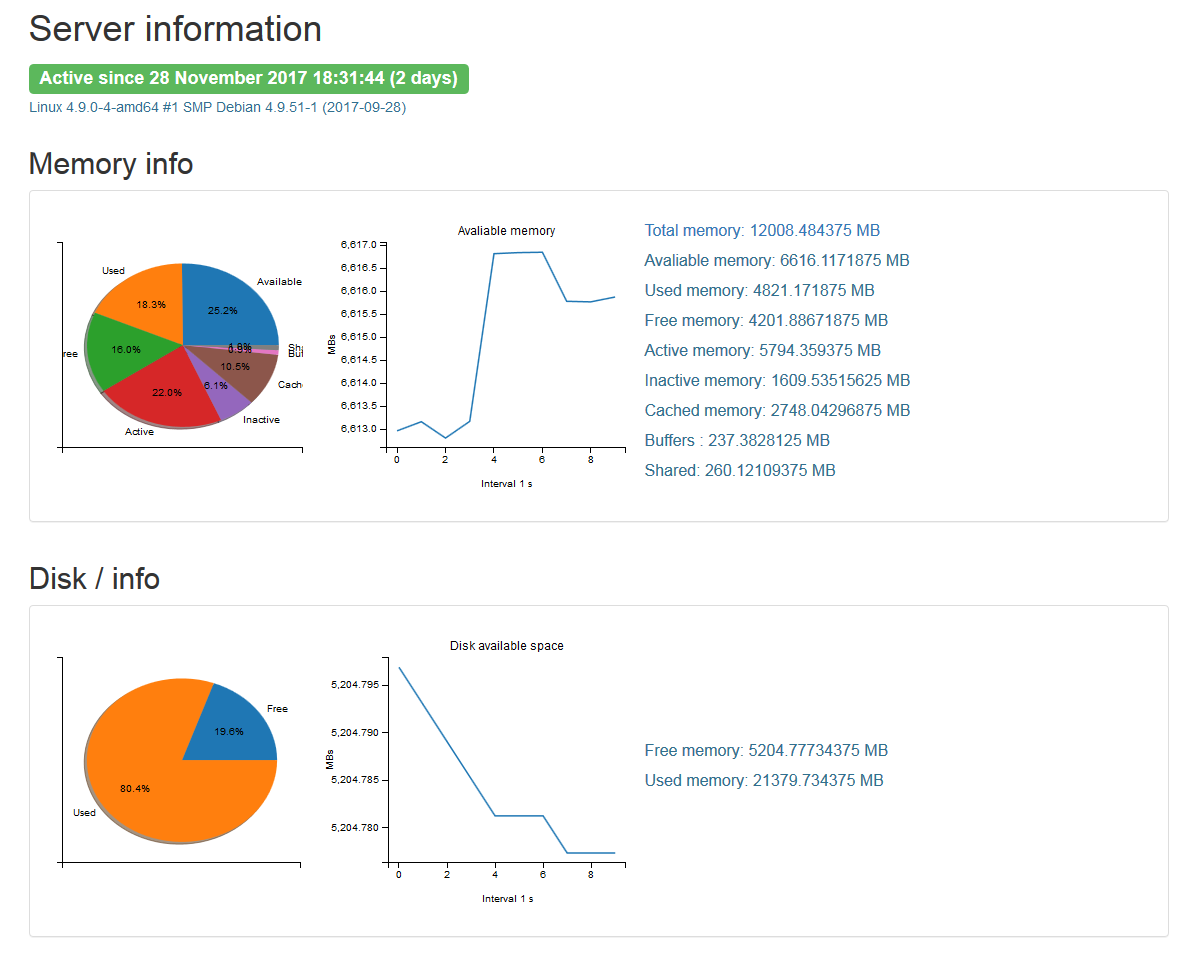

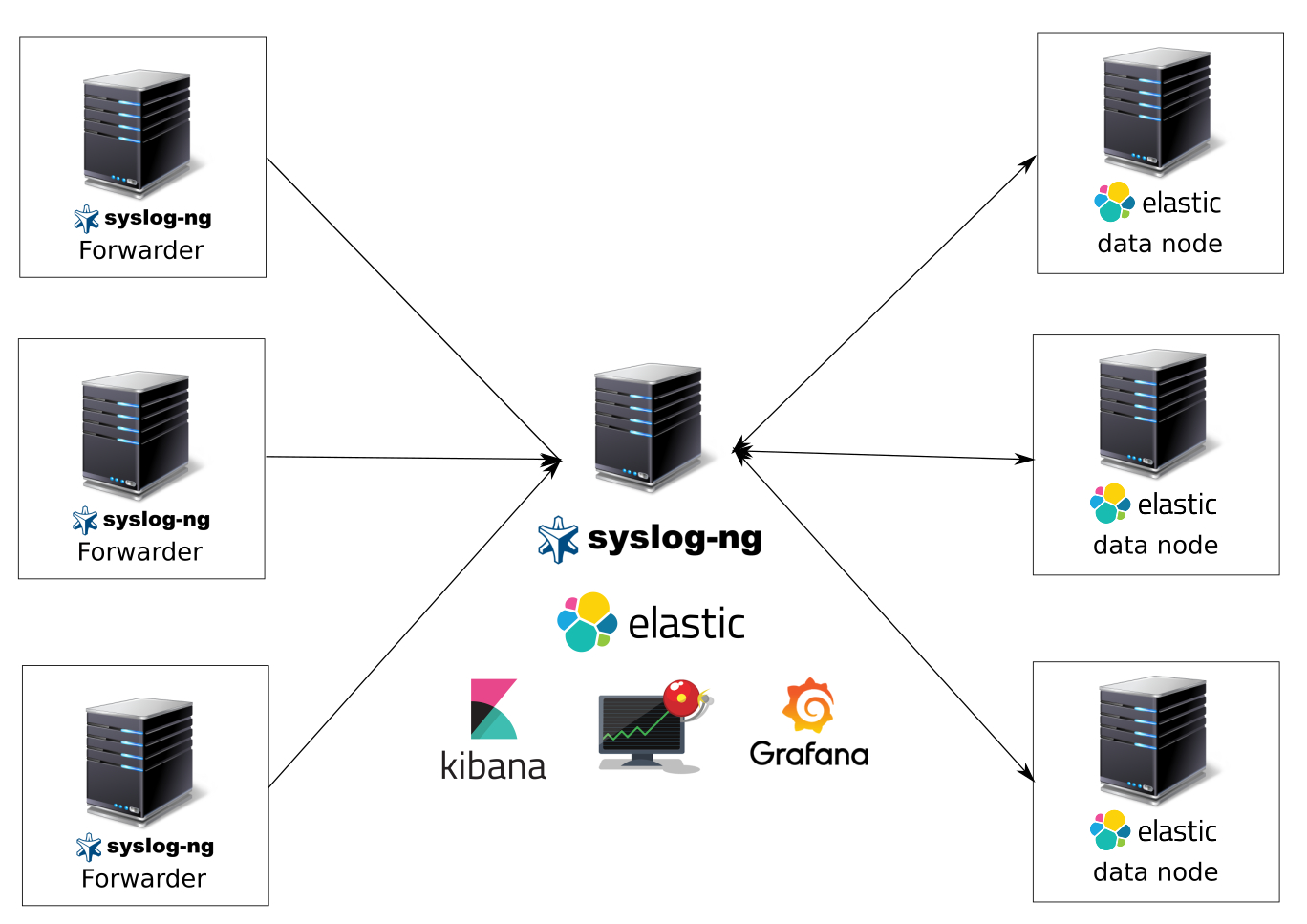
 .
.