
Исследуем пакетный менеджер Nix и операционную систему NixOS.
Ранее мы разработали универсальный скрипт сборки для проектов autotools.
Сегодня мы обратимся к программе GNU hello, чтобы исследовать зависимости времени сборки и времени выполнения.

Пользователь
Исследуем пакетный менеджер Nix и операционную систему NixOS.
Ранее мы разработали универсальный скрипт сборки для проектов autotools.
Сегодня мы обратимся к программе GNU hello, чтобы исследовать зависимости времени сборки и времени выполнения.

Я написал эту статью для себя, но подумал, что она будет полезна и начинающим айтишникам, и тем, кому необходимо освежить знания или быстро вспомнить основные вещи, не открывая полное руководство.
Ещё раз подчеркну, статья задумывалась как базовая памятка и помощь для начинающих, а никак не исчерпывающая документация. Многое я опускаю ввиду избыточности или неактульности, по крайней мере в моей работе.


Заканчиваем разбирать части пайплайна RLHF с точки зрения исторической ретроспективы, чтобы понять, как сформировалась идея, которая сегодня лежит в основе самых популярных LLM.
В первой части мы ознакомились с общим пайплайном RLHF, LLM, KL-контролем и необходимостью предобучения на пусть и грязных, но больших данных
Во второй - сравнили Offline RL и Online RL, увидели их ограничения, попробовали имитировать Online RL через self-play и непрерывную обратную связь от среды через Reward Modelling. А еще первый раз задумались о сборе непротиворечивой но достаточно полной обратной связи от человека.
В третьей - добавили этап дообучения с учителем на качественных демонстрациях и осознали важность контроля за сбором человеческой обратной связи.
В этой, финальной части, мы узнаем современное и будто бы общепринятое понятие и определение "согласованной модели" - HHH: helpful, honest, harmless, поиграемся с различными комбинациями RM для представления HHH моделей, а еще увидим, как обогащать и собирать обратную связь не от человека, а от LLM.

Привет, Хабр! Раньше мы уже рассказывали о распознавании документов прямо в браузере и технологии WebAssembly (или WASM), которая позволяет это делать. Теперь давайте разберем, как и где это работает в реальной жизни.


В нашей прошлой статье про синтез речи мы дали много обещаний: убрать детские болячки, радикально ускорить синтез еще в 10 раз, добавить новые "фишечки", радикально улучшить качество.
Сейчас, вложив огромное количество работы, мы наконец готовы поделиться с сообществом своими успехами:
Это по-настоящему уникальное и прорывное достижение и мы не собираемся останавливаться. В ближайшее время мы добавим большое количество моделей на разных языках и напишем целый ряд публикаций на эту и смежные темы, а также продолжим делать наши модели лучше (например, еще в 2-5 раз быстрее).
Попробовать модель как обычно можно в нашем репозитории и в колабе.
Привет, Хабр! Предлагаю вашему вниманию перевод статьи Rudy Gilman и Katherine Wang Intuitive RL: Intro to Advantage-Actor-Critic (A2C).

Специалисты по обучению с подкреплением (RL) подготовили множество отличных учебных пособий. Большинство, однако, описывают RL в терминах математических уравнений и абстрактных диаграмм. Нам нравится думать о предмете с другой точки зрения. Сама RL вдохновлена тем, как учатся животные, так почему бы не перевести лежащий в основе этого механизм RL обратно в природные явления, которые он призван имитировать? Люди учатся лучше всего через истории.
Это история о модели Actor Advantage Critic (A2C). Модель «Субъект-критик» — это популярная форма модели Policy Gradient, которая сама по себе является традиционным алгоритмом RL. Если вы понимаете A2C, вы понимаете глубокий RL.

"Cтоит ли тратить деньги на тот или иной дорогой курс с codename «Стань DS за два месяца» или все же выучиться на дата-саентиста самостоятельно и бесплатно, и в таком случае, с чего начать?" такие вопросы я получаю от аудитории своего блога. Меня зовут Айра, я делаю проекты в DS&ML, продюсирую курсы по созданию ML-проектов и веду блог по теме.
Недавно собрала ответ на этот вопрос достаточно развернуто, чтобы поделиться им с широкой аудиторией. Не все платные курсы плохие (хотя большинство — да — из-за механизмов отбора, продаж и слабой программы), но о них напишу отдельно. Мне кажется, нужно учитывать больше персонализированных параметров для того, чтобы грамотно выбирать хороший курс за деньги.
Мы уже выяснили, что у нас есть дефицит рабочих рук во всех отраслях. На примере СССР увидели, что дефицит легко закрывается деньгами и плюшками, что сейчас и происходит в IT. Однако при дефиците рабочих рук в остальных отраслях зарплаты остаются на уровне Румынии и никак не подтягиваются. Почему?
Пару недель назад вышел новый отчет «State of AI Report 2021». Уже несколько лет подряд такой отчет ежегодно выпускает венчурный фонд «Air Street Capital» (https://www.airstreet.com). Он инвестирует в компании в области искусственного интеллекта (ИИ) и наук о жизни (НЖ) на ранних стадиях. Миссия фонда – создавать устойчивые компании, оказывающие долгосрочное влияние на рынки. В портфеле фонда сейчас шесть стартапов в ИИ и семь в НЖ. Еще тринадцать стартапов было проинвестировано в прошлом. Портфель диверсифицирован по странам – сейчас их семь в портфеле. Ссылка на слайды – в конце.

Выстраивание производственных процессов — распространенная боль в IT-разработке. Это большая и комплексная задача, с которой неизбежно приходится сталкиваться на проектах, чтобы доставить фичу в срок. Однозначного и единственно правильного решения здесь нет. Зато есть множество маркеров: кранчи, выгорание, фичекат, — указывающих на то, что что-то вы все-таки делаете не так.
Изменение воркфлоу — процесс, способный растянуться не на один год, и, конечно, не обойдется без собственных набитых шишек. Ниже я расскажу об опыте команды War Robots: с чего мы когда-то начинали и каких результатов добились сейчас. И, поверьте, для нас это того стоило.
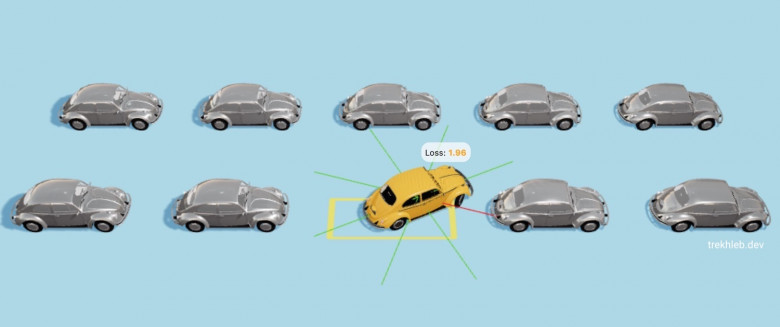
В этой статье мы "научим" автомобиль выполнять самостоятельную парковку с помощью генетического алгоритма.
В 1-м поколении автомобили будут иметь случайный геном и будут вести себя хаотично.
К ≈40-му поколению автомобили понемногу начнут учиться парковке и будут все ближе и ближе подбираться к парковочному месту
Чтобы увидеть эволюционный процесс прямо в браузере вы можете запустить ? симулятор эволюции, .
Генетический алгоритм для этого проекта будем реализовывать на TypeScript. В этой статье будет показан полный исходный код алгоритма, но вы также можете найти финальные примеры кода в репозитории симулятора.

Меня зовут Павел Куницын, я работаю в Первой грузовой компании (ПГК) главным специалистом по анализу данных и машинному обучению. Недавно опубликовал пост на Kaggle с рекомендациями для тех, кто хочет перейти в Data Science, не имея релевантного опыта. Он оказался интересным сообществу, и я решил подготовить специально для вас расширенную версию публикации – дополнить важной информацией, рекомендациями.
Здесь я не напишу список онлайн-платформ с курсами по Data Science. Об этом писали уже много раз, а расскажу о том, как нужно учиться. У меня есть список правил, которых придерживаюсь сам, когда хочу развить свои профессиональные навыки в какой-то новой сфере. Используйте их не только при изучении Data Science, но и других областей.
1. Сформулируйте для себя конечную цель
Вы можете прийти в Data Science по разным причинам: от интереса к новой сфере до желания устроиться на высокооплачиваемую работу. Возможно, вы — руководитель проекта, и ваша цель – получить краткое представление о том, какие этапы включают в себя проекты по машинному обучению (ML), чтобы сделать общение со своей командой эффективнее. Или, может быть, вы аналитик, и ваша цель – получить новые технические навыки? А, может быть, ваша нынешняя работа никак не связана со статистикой или разработкой, вы никогда не писали код, но хотели бы научиться. Тогда целью может быть получение всех необходимых для этого знаний.
Для достижения каждой из перечисленных целей требуются разные стратегии и разное количество времени, поэтому формулируйте их четко. Чтобы правильно сформулировать свою цель, спросите себя:

И так, вот команда растёт, растёт и дорастает хотя бы до 15+ человек. В этот момент вы неожиданно понимаете, что у вас 3 бекенд-разработчика или даже 5. Здесь возникает неудержимое желание сделать одного из них Самым-Главным-Бекенд-Разработчиком-Проекта. Это желание понятно, и даже логично...

Ведь я профессионал в IT. Как такое могло произойти?
65 лет, по идее, это год «выхода на пенсию». Для меня этот год стал годом «окончания» всего. В этой статье я решил рассказать о своем двухлетнем пути без работы. Ну и как теперь я работаю неполный день.
Дисклеймер. Эта статья -- перевод текста разработчика из США. Думаю, разница в том, что в странах СНГ подобные проблемы начинаются еще раньше. В дополнение к переводу предлагаю обсудить проблемы поиска работы среди возрастных соискателей в нашей стране. Об этом в конце статьи.