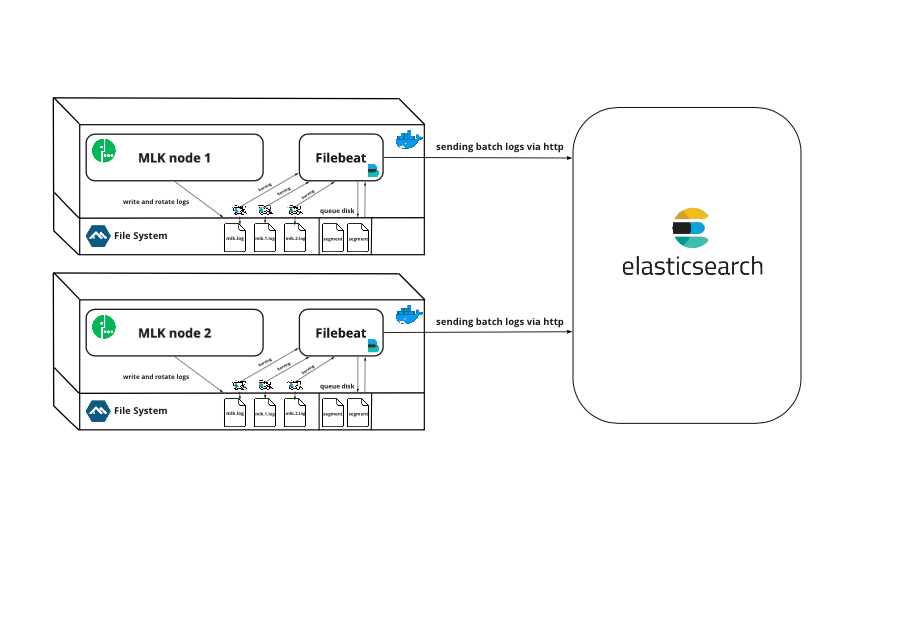
Глубокое понимание внутреннего устройства DRBD позволяет более тонко настраивать работу системы и правильно планировать ресурсы. К счастью, у команды DRBD уже есть отличная документация, которая довольно подробно разбирает эту тему. Мы опирались на нее в своей работе, и решили перевести и выложить в открытом доступе 17-ю главу — как удобную шпаргалку по внутреннему устройству DRBD. Так что это не обычная статья, а перевод части официальной документации (исходная нумерация разделов сохранена).
В этой главе представлена информация о внутренних алгоритмах и структурах DRBD. Она довольно подробно рассматривает внутреннюю работу DRBD, но делает это не настолько глубоко, чтобы служить справочником для разработчиков. Для этой цели рекомендуем обратиться к материалам, перечисленным в разделе Publications, и, естественно, к комментариям в исходном коде DRBD.