Наверное, каждому программисту приходилось сталкиваться с задачами вида «прочитать что-то в формате А и произвести с ним некие манипуляции». Будь то json, логи nginx, cfg, sql, yaml, csv или что-то еще. Хорошо, когда можно воспользоваться библиотекой, однако, по разным причинам, это удается не всегда. Тогда и встает вопрос создания собственного парсера для заданного формата. И это, как говорят англичане, часто оказывается PITA (болью в ...). В этой статье я постараюсь облегчить эту боль. Кому интересно, добро пожаловать.

Павел @pahaz
C-level, startupper, co-founder, делаю ит-компании
Кто трогал мой mac? Ловим горничную или evil maid detection
Простой
4 мин
Кейс

Я часто нахожусь в командировках и путешествиях, внимательно отношусь к безопасности своего macbook. Недавно, вернувшись в отель, я обнаружил признаки того, что кто-то что-то делал с моим ноутбуком в мое отсутствие.
В этой статье мы рассмотрим способы, позволяющие узнать о попытке физического доступа к вашему макбуку, соберем данные о вторжении и отправим их себе в Telegram.
PostgreSQL Antipatterns: сказ об итеративной доработке поиска по названию, или «Оптимизация туда и обратно»
7 мин
Тысячи менеджеров из офисов продаж по всей стране фиксируют в нашей CRM-системе ежедневно десятки тысяч контактов — фактов общения с потенциальными или уже работающими с нами клиентами. А для этого клиента надо сначала найти, и желательно очень быстро. И происходит это чаще всего по названию.
Поэтому неудивительно, что, разбирая в очередной раз «тяжелые» запросы на одной из самых нагруженных баз — нашего собственного корпоративного аккаунта СБИС, я обнаружил «в топе» запрос для «быстрого» поиска по названию для карточек организаций.
Причем дальнейшее расследование выявило интересный пример сначала оптимизации, а затем деградации производительности запроса при последовательной его доработке силами нескольких команд, каждая из которых действовала исключительно из лучших побуждений.
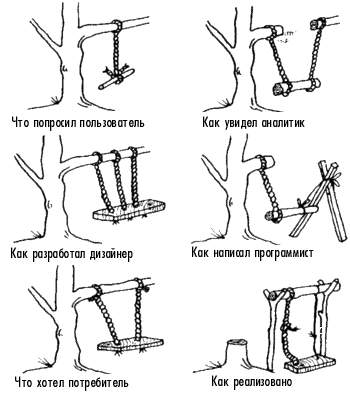 [КДПВ отсюда]
[КДПВ отсюда]
Что вообще обычно подразумевает пользователь, когда говорит про «быстрый» поиск по названию? Почти никогда это не оказывается «честный» поиск по подстроке типа
Пользователь же подразумевает на бытовом уровне, что вы ему обеспечите поиск по началу слова в названии и покажете более релевантным то, что начинается на введенное. И сделаете это практически мгновенно — при подстрочном вводе.
Поэтому неудивительно, что, разбирая в очередной раз «тяжелые» запросы на одной из самых нагруженных баз — нашего собственного корпоративного аккаунта СБИС, я обнаружил «в топе» запрос для «быстрого» поиска по названию для карточек организаций.
Причем дальнейшее расследование выявило интересный пример сначала оптимизации, а затем деградации производительности запроса при последовательной его доработке силами нескольких команд, каждая из которых действовала исключительно из лучших побуждений.
0: чего же хотел пользователь
Что вообще обычно подразумевает пользователь, когда говорит про «быстрый» поиск по названию? Почти никогда это не оказывается «честный» поиск по подстроке типа
... LIKE '%роза%' — ведь тогда в результат попадают не только 'Розалия' и 'Магазин Роза', но и 'Гроза' и даже 'Дом Деда Мороза'.Пользователь же подразумевает на бытовом уровне, что вы ему обеспечите поиск по началу слова в названии и покажете более релевантным то, что начинается на введенное. И сделаете это практически мгновенно — при подстрочном вводе.
Микросервисная архитектура, Spring Cloud и Docker
14 мин
Туториал
Привет, Хабр. В этой статье я кратко расскажу о деталях реализации микросервисной архитектуры с использованием инструментов, которые предоставляет Spring Cloud на примере простого концепт-пруф приложения.

Код доступен для ознакомления на гитхабе. Образы опубликованы на докерхабе, весь зоопарк стартует одной командой.
Знакомство с хранилищем Ceph в картинках
11 мин
Recovery Mode
Облачные файловые хранилища продолжают набирать популярность, и требования к ним продолжают расти. Современные системы уже не в состоянии полностью удовлетворить все эти требования без значительных затрат ресурсов на поддержку и масштабирование этих систем. Под системой я подразумеваю кластер с тем или иным уровнем доступа к данным. Для пользователя важна надежность хранения и высокая доступность, чтобы файлы можно было всегда легко и быстро получить, а риск потери данных стремился к нулю. В свою очередь для поставщиков и администраторов таких хранилищ важна простота поддержки, масштабируемость и низкая стоимость аппаратных и программных компонентов.
Ceph — это программно определяемая распределенная файловая система с открытым исходным кодом, лишенная узких мест и единых точек отказа, которая представляет из себя легко масштабируемый до петабайтных размеров кластер узлов, выполняющих различные функции, обеспечивая хранение и репликацию данных, а также распределение нагрузки, что гарантирует высокую доступность и надежность. Система бесплатная, хотя разработчики могут предоставить платную поддержку. Никакого специального оборудования не требуется.
При выходе любого диска, узла или группы узлов из строя Ceph не только обеспечит сохранность данных, но и сам восстановит утраченные копии на других узлах до тех пор, пока вышедшие из строя узлы или диски не заменят на рабочие. При этом ребилд происходит без секунды простоя и прозрачно для клиентов.
Знакомьтесь: Ceph
Ceph — это программно определяемая распределенная файловая система с открытым исходным кодом, лишенная узких мест и единых точек отказа, которая представляет из себя легко масштабируемый до петабайтных размеров кластер узлов, выполняющих различные функции, обеспечивая хранение и репликацию данных, а также распределение нагрузки, что гарантирует высокую доступность и надежность. Система бесплатная, хотя разработчики могут предоставить платную поддержку. Никакого специального оборудования не требуется.
При выходе любого диска, узла или группы узлов из строя Ceph не только обеспечит сохранность данных, но и сам восстановит утраченные копии на других узлах до тех пор, пока вышедшие из строя узлы или диски не заменят на рабочие. При этом ребилд происходит без секунды простоя и прозрачно для клиентов.
Яндекс открывает технологию машинного обучения CatBoost
6 мин
Сегодня Яндекс выложил в open source собственную библиотеку CatBoost, разработанную с учетом многолетнего опыта компании в области машинного обучения. С ее помощью можно эффективно обучать модели на разнородных данных, в том числе таких, которые трудно представить в виде чисел (например, виды облаков или категории товаров). Исходный код, документация, бенчмарки и необходимые инструменты уже опубликованы на GitHub под лицензией Apache 2.0.

CatBoost – это новый метод машинного обучения, основанный на градиентном бустинге. Он внедряется в Яндексе для решения задач ранжирования, предсказания и построения рекомендаций. Более того, он уже применяется в рамках сотрудничества с Европейской организацией по ядерным исследованиям (CERN) и промышленными клиентами Yandex Data Factory. Так чем же CatBoost отличается от других открытых аналогов? Почему бустинг, а не метод нейронных сетей? Как эта технология связана с уже известным Матрикснетом? И причем здесь котики? Сегодня мы ответим на все эти вопросы.
CatBoost – это новый метод машинного обучения, основанный на градиентном бустинге. Он внедряется в Яндексе для решения задач ранжирования, предсказания и построения рекомендаций. Более того, он уже применяется в рамках сотрудничества с Европейской организацией по ядерным исследованиям (CERN) и промышленными клиентами Yandex Data Factory. Так чем же CatBoost отличается от других открытых аналогов? Почему бустинг, а не метод нейронных сетей? Как эта технология связана с уже известным Матрикснетом? И причем здесь котики? Сегодня мы ответим на все эти вопросы.
Sysdig — инструмент для диагностики Linux-систем
16 мин

Для сбора и анализа информации о системе в Linux используется целый набор утилит. Для диагностики каждого из компонентов системы используется отдельный диагностический инструмент.
Лекции Техносферы. 1 семестр. Введение в анализ данных (весна 2016)
3 мин
Слушайте и смотрите новую подборку лекций Техносферы Mail.Ru. На этот раз представляем в открытом доступе весенний курс «Введение в анализ данных», на котором слушателей знакомят со сферой анализа данных, основными инструментами, задачами и методами, с которыми сталкивается любой исследователь данных в работе. Курс преподают Евгений Завьялов (аналитик проекта Поиск Mail.Ru, занимающийся извлечением полезных бизнесу знаний из данных, генерируемых поисковым движком и десктопными приложениями), Михаил Гришин (программист-исследователь из отдела анализа данных) и Сергей Рыбалкин (старший программист из студии Allods Team).
Из первой лекции вы узнаете, что такое анализ данных, какие инструменты используют для анализа данных, а также как работает Python.
Лекция 1. Введение в Python
Из первой лекции вы узнаете, что такое анализ данных, какие инструменты используют для анализа данных, а также как работает Python.
4 вида утечек памяти в JavaScript и как с ними бороться
16 мин
Перевод
В этой статье мы рассмотрим распространённые виды утечек памяти в клиентском JavaScript. Также мы узнаем, как их обнаружить с помощью Chrome Development Tools.
Конкурентный доступ к реляционным базам данных
13 мин
 Вопросы параллелизма в компьютерных вычислениях очень сложны! Причинами большой сложности являются огромное количество деталей, которые нужно учитывать при разработке параллельных программ. В программирование и без того существует большое количество деталей, которые создают почву для ошибок, параллелизм же, добавляет ещё.
Вопросы параллелизма в компьютерных вычислениях очень сложны! Причинами большой сложности являются огромное количество деталей, которые нужно учитывать при разработке параллельных программ. В программирование и без того существует большое количество деталей, которые создают почву для ошибок, параллелизм же, добавляет ещё.Вопросы конкурентного доступа к реляционным базам данных встают практически перед любыми разработчиками прикладного программного обеспечения и не только перед ними. Результатом такой востребованности этой области является наличие большого количества созданных архитектурных паттернов. Это позволяет успешно справляться с большой сложностью разработки таких программ. Ниже пойдёт речь о таких рецептах, а также механизмах на которых базируется их реализация. Повествование будет иллюстрироваться примерами кода на Java, но большинство материала не привязано к языку. Цель статьи — описать проблемы конкурентного доступа к реляционным базам данных, в качестве введения в предмет, а не полноценного охвата темы.
Быстрый старт в изучении анализа данных и машинного обучения от МФТИ и Яндекса
5 мин
Почему анализ данных
Потребность в анализе данных вышла далеко за пределы технологических и интернет-компаний. Методы машинного обучения все активнее используются в совершенно различных областях, вплоть до оптимизации маршрутов транспорта. С их помощью создаются новые лекарства и автомобили без водителя, подбирается музыка под настроение, находятся потенциальные спутники жизни.
Специалист по анализу данных или data scientist – одна из самых востребованных профессий сегодняшнего дня. За реальных практиков, умеющих получать значимые результаты в сжатые сроки, идет настоящая борьба, и стоимость таких специалистов взлетает до небес.
Также интерес подогревают государственные и коммерческие структуры, которые не только говорят об этих специальностях, но и уже готовятся к проведению первых олимпиад по ним.
Что же скрывается за этими словами, все ли понимают их значение? К сожалению, нередко к ним относятся как к некому волшебному ингредиенту, который решит все проблемы. Не осознаются ни границы его применения, ни порядок действий, чтобы использовать их «здесь и сейчас».
Пришла пора внести ясность в этот вопрос.

Многопользовательский онлайн-шутер на WebGL и asyncio, часть вторая
17 мин

В этом материале постарался описать создание браузерного
3D-шутера, начиная от импорта симпатичных моделей танков на сцену и заканчивая синхронизацией игроков и ботов между собой с помощью websocket и asyncio и балансировкой их по комнатам.Введение
1. Структура игры
2. Импорт моделей и blender
3. Подгрузка моделей в игре с babylon.js и сами модели
4. Передвижения, миникарта и звуки игры в babylon.js
5. Вебсокеты и синхронизация игры
6. Игроки и их координация
7. Балансировка игроков по комнатам и объектный питон
8. Asyncio и генерация поведения бота
9. Nginx и проксирование сокетов
10. Асинхронное кэширование через memcache
11. Послесловие и RoadMap
Всех кому интересна тема асинхронных приложений в
Python3, WebGL и просто игр, прошу под кат.Примеры использования MongoDB в e-commerce (часть 2)
25 мин
Туториал

[ Первая часть ]
В этом посте будет то, что не поместилось в первую часть. Это некоторые операторы, которые есть в
aggregation framework и достаточно вольный перевод трех статей из раздела экоситема на сайте со справкой к MongoDB, описывающих некоторые случаи применения для интернет-коммерции.Случаи использования разделены там на восемь статей, которые условно можно разделить на три группы. Мне показались самыми интересными для перевода три материала, связанные с
e-commerce.- Операторы в aggregation framework
- Каталог продуктов
- Корзина и управления остатками на складе
- Иерархия категорий
Шпаргалка по mongodb: e-commerce, миграция, часто применяемые операции и немного о транзакциях
40 мин
Туториал
Этот пост — небольшая шпаргалка по mongodb и немного длинных запросов с парой рецептов. Иногда бывает удобно когда какие-то мелочи собраны в одном месте, надеюсь, каждый, кто интересуется mongodb, найдет для себя что-то полезное.
Не хотелось бы, чтобы пост воспринимался в ключе холиваров на тему SQL vs. NOSQL И так понятно что везде есть свои плюсы и минусы, в данном случае это просто где-то немного справки, где-то немного примеров из того, с чем приходилось сталкиваться. Примеры на mongo shell и на python.
- Миграция в на новые версии в mongodb
- Запросы сравнения и логические
- Полнотекстовый поиск в Mongodb, regexp, индексы и пр.
- Атомарные операторы (модифицирующие данные )
- Немного о транзакциях в Mongodb
- Агрегационный фреймворк и JOIN-ы в Mongodb
- Примеры
- Небольшая песочница на Python
19 советов по повседневной работе с Git
14 мин
Туториал
Перевод

Если вы регулярно используете Git, то вам могут быть полезны практические советы из этой статьи. Если вы в этом пока новичок, то для начала вам лучше ознакомиться с Git Cheat Sheet. Скажем так, данная статья предназначена для тех, у кого есть опыт использования Git от трёх месяцев. Осторожно: траффик, большие картинки!
Содержание:
- Параметры для удобного просмотра лога
- Вывод актуальных изменений в файл
- Просмотр изменений в определённых строках файла
- Просмотр ещё не влитых в родительскую ветку изменений
- Извлечение файла из другой ветки
- Пара слов о ребейзе
- Сохранение структуры ветки после локального мержа
- Исправление последнего коммита вместо создания нового
- Три состояния в Git и переключение между ними
- Мягкая отмена коммитов
- Просмотр диффов для всего проекта (а не по одному файлу за раз) с помощью сторонних инструментов
- Игнорирование пробелов
- Добавление определённых изменений из файла
- Поиск и удаление старых веток
- Откладывание изменений определённых файлов
- Хорошие примечания к коммиту
- Автодополнения команд Git
- Создание алиасов для часто используемых команд
- Быстрый поиск плохого коммита
Ceph: Cloud Storage без компромиссов
10 мин
Здравствуйте, уважаемые читатели!
Современные облака, используемые для целей хостинга, высоко поднимают планку требований к инфраструктуре хранения данных. Чтобы клиент получил качественную услугу, системе хранения данных должен быть присущ целый ряд свойств:
Ни RAID-массивы, ни «железные» СХД не способны решить все перечисленные задачи одновременно. Именно поэтому все большее распространение в индустрии хостинга приобретает Software-defined storage. Одним из ярких представителей SDS является распределенное хранилище под названием Ceph.
Мы решили рассказать об этом замечательном продукте, который используется в CERN, 2GIS, Mail.ru и в нашем облачном хостинге.

Современные облака, используемые для целей хостинга, высоко поднимают планку требований к инфраструктуре хранения данных. Чтобы клиент получил качественную услугу, системе хранения данных должен быть присущ целый ряд свойств:
- высокая надежность хранения
- высокая доступность данных, то есть минимальное время простоя при авариях
- высокая скорость доступа и минимальные задержки
- низкая удельная стоимость хранения
- различные прикладные возможности: клонирование, снимки состояния и т.д.
Ни RAID-массивы, ни «железные» СХД не способны решить все перечисленные задачи одновременно. Именно поэтому все большее распространение в индустрии хостинга приобретает Software-defined storage. Одним из ярких представителей SDS является распределенное хранилище под названием Ceph.
Мы решили рассказать об этом замечательном продукте, который используется в CERN, 2GIS, Mail.ru и в нашем облачном хостинге.
Декодирование изображений из мозга человека
1 мин

Сегодня в журнале Science публикована научная работа (pdf) с описанием нового метода автоматической реконструкции изображений из мозга человека. Авторы научной работы считают, что их метод более точный, чем предыдущие работы в этой области: хорошо распознаются символы алфавита и простые контрастные фигуры.
Пока что декодер распознаёт только картинки, которые реально видит человек в данный момент, но в будущем он должен работать и на воображаемых изображениях. В этом случае станет возможным, например, набирать текст с закрытыми глазами.
Вычисление оптического потока методом Лукаса-Канаде. Теория
7 мин



В системах компьютерного зрения и обработки изображений часто возникает задача определения перемещений объектов в трехмерном пространстве с помощью оптического сенсора, то есть видеокамеры. Имея на входе последовательность кадров, необходимо воссоздать запечатленное на них трехмерное пространство и те изменения, которые происходят с ним с течением времени. Звучит сложно, но на практике зачастую достаточно найти смещения двухмерных проекций объектов в плоскости кадра.
Если мы хотим узнать на сколько тот или иной объект объект сместился по отношению к его же положению на предыдущем кадре за то время, которое прошло между фиксацией кадров, то скорее всего в первую очередь мы вспомним про оптический поток (optical flow). Для нахождения оптического потока можно смело воспользоваться готовой протестированной и оптимизированной реализацией одного из алгоритмов, например, из библиотеки OpenCV. При этом, однако, очень невредно разбираться в теории, поэтому я предлагаю всем заинтересованным заглянуть внутрь одного из популярных и хорошо изученных методов. В этой статье нет кода и практических советов, зато есть формулы и некоторое количество математических выводов.
Один крутой Gist: whiteboardCleaner
1 мин
Доброго времени суток уважаемые хабравчане. На просторах интернета мне повстречался один миниатюрный и очень интересный Bash скрипт. С помощью ImageMagick он потрясающим образом обрабатывает фотографии белой учебной доски, очищая «содержимое» от всего лишнего:


#!/bin/bash
convert $1 -morphology Convolve DoG:15,100,0 -negate -normalize -blur 0x1 -channel RBG -level 60%,91%,0.1 $2
До:
После:
Signed Distance Field или как сделать из растра вектор
12 мин
Речь сегодня пойдёт о генерации изображений с картой расстояний (Signed Distance Field). Данный вид изображений примечателен тем, что фактически позволяет получить «векторную» графику на видеоускорителе, причём даром. Одной из первых данный метод растеризации предложила компания Valve в игре Team Fortress 2 для масштабируемых декалей в 2007 году, но до сих пор он не пользуется особой популярностью, хотя позволяет рендерить прекрасного качества шрифты, используя текстуру всего 256х256 точек. Данный метод прекрасно подходит для современных экранов высокой чёткости и позволяет серьёзно сэкономить на текстурах в играх, он не требователен к железу и прекрасно работает на смартфонах.

Хитрость заключается в создании такой специально подготовленной карты расстояний, что при использовании простейшего шейдера получается идеальная векторная картинка. Более того, с помощью шейдеров можно получить эффекты тени, свечения, объёма и т. п.
Как же создавать такие изображения? Очень просто, ImageMagick позволяет сделать это одной командой:
На этом можно было бы поставить точку, но так полноценного топика не получится. Что ж, под катом — описание быстрого алгоритма расчёта SDF, пример на C++ и немного шейдеров для OpenGL.
Хитрость заключается в создании такой специально подготовленной карты расстояний, что при использовании простейшего шейдера получается идеальная векторная картинка. Более того, с помощью шейдеров можно получить эффекты тени, свечения, объёма и т. п.
Как же создавать такие изображения? Очень просто, ImageMagick позволяет сделать это одной командой:
convert in.png -filter Jinc -resize 400% -threshold 30% \( +clone -negate -morphology Distance Euclidean -level 50%,-50% \) -morphology Distance Euclidean -compose Plus -composite -level 45%,55% -resize 25% out.png
На этом можно было бы поставить точку, но так полноценного топика не получится. Что ж, под катом — описание быстрого алгоритма расчёта SDF, пример на C++ и немного шейдеров для OpenGL.